Halo Reference Documentation
- I 前言
- II Release Note
- III Halo Ecology
- IV Halo 快速入门
- 8. Halo开发环境
- 9. 代码生成器使用
- 10. 创建应用
- 11. 使用命令
- 12. 扩展快速入门
- 13. 创建流程
- 14. Halo DDD使用
- 15. Halo QA
- 16. Halo ToolKit
- 17. 快速使用IDEA插件
- 17.1. Halo Settings
- 17.2. 创建 Halo Project
- 17.3. 行标记功能
- 17.4. 增强右键功能
- 17.4.1. 创建Controller
- 17.4.2. 创建Data Object(数据对象)
- 17.4.3. 创建Mapper
- 17.4.4. 创建Command Object(命令对象)
- 17.4.5. 创建(Command Handler)命令执行器
- 17.4.6. 创建阶段
- 17.4.7. 创建步骤
- 17.4.8. 创建应用服务
- 17.4.9. 创建Flow流程定义
- 17.4.10. 创建节点执行器
- 17.4.11. 创建Extension Point(扩展点)
- 17.4.12. 创建Extension(扩展)
- 17.4.13. 创建Event Object(事件对象)
- 17.4.14. 创建 Event Handler(事件处理器)
- 17.4.15. 创建实体
- 17.4.16. 创建值对象
- 17.4.17. 创建Domain Service(领域服务)
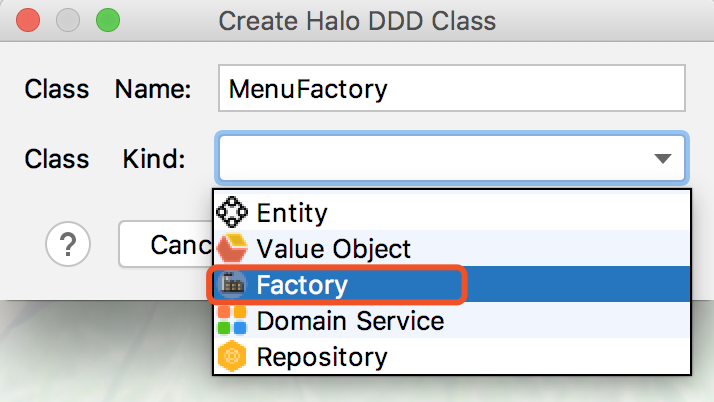
- 17.4.18. 创建工厂
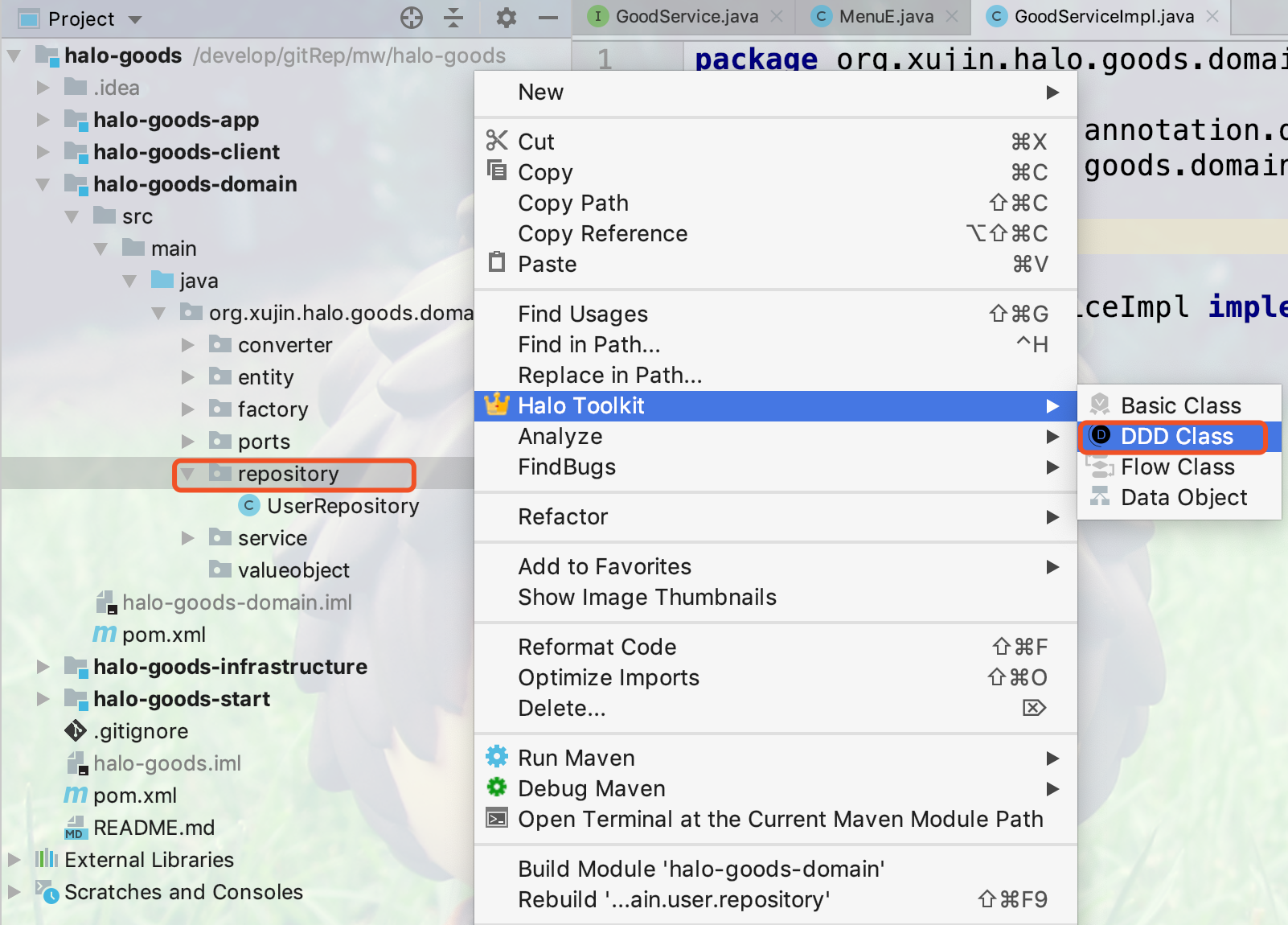
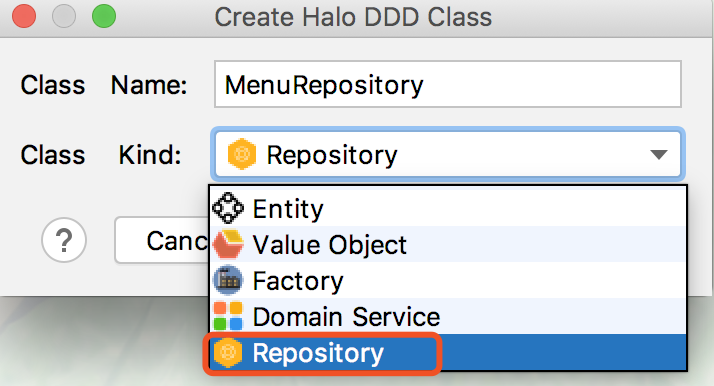
- 17.4.19. 创建资源库
- V Halo Framework
- 18. Halo Framework概述
- 19. Halo Framework设计
- 20. Halo CQRS
- 21. Halo DDD
- 22. Halo扩展点
- 23. 扩展点管理
- 24. 流程编排
- 25. Halo Plugin
- 26. Halo Cache
- 27. 分层设计
- 28. Halo Check
- VI Halo Boot
- 29. 什么是Starter
- 30. Halo Boot概述
- 31. Halo Boot扩展
- 32. Halo Parent介绍
- 33. Halo Mybatis
- 34. Halo Web
- 35. Halo Swagger
- 36. Halo MapStruct
- 37. Halo Excel
- 38. Halo Test
- 39. Halo MongoDB
- 40. Halo ElasticSearch 6.3.2
- 41. Halo ElasticSearch 7.2.1
- 42. Halo Job
- 43. Halo AliMQ
- 44. halo Redis
- 45. Halo Redisson
- 46. Halo Apollo
- 47. Halo Shiro
- 48. Halo influxDB
- 49. Halo Mail
- 50. Halo Retrofit
- VII Halo Cloud
- Halo Admin
- VIII Tools
I 前言
本文档是Halo Reference Documentation提供了 Halo Framework设计和使用说明.其中Halo Core是将DDD,洋葱架构,整洁架构,读写分离架构有机整合一起,基于业务身份+扩展点的设计思想, 采用应用内部流程编排的方式形成可复用的业务资产库。最终架构落地达到业务与业务隔离,业务与平台隔离,管理域与运行域分开,帮助企业快速落地业务中台。
| Halo设计原则简单,即在高内聚,低耦合,可扩展,易理解的指导思想下,尽可能的贯彻面向对象的设计思想和领域驱动设计的原则。 |
Halo生态如下所示:
-
Halo CQRS:读写分离架构-所有请求封装为命令对象,通过Command Bus分发到命令处理器执行,通过Event和Event Bus等实现读写分离。
-
Halo DDD: 根据领域驱动设计思想,自定义注解
@Entity(实体),@Factory(工厂),@DomainService(领域服务),@AggregateRoot(聚合根),@UniqueIdentity(实体唯一标识),@AggregatePart(聚合部件),@ValueObject(值对象),@DomainRepository(资源库),@DomainAbility(域能力)等进行战术设计,落地DDD,实现业务与业务隔离。 -
Halo Admin: 中台可视化管控平台,全链路可视化视角,对业务资产进行可视化。
-
Halo Boot: 基于Spring Boot定制的Starter。包含Halo Basic,Halo Web,Halo Swagger,Halo ES6,Halo Job,Halo Test,Halo MyBatis等
-
Halo Extension:基于扩展点的设计思想,自定义
@ExtensionPoint(扩展点注解)和@Extension(扩展注解), 实现平台和插件隔离。 -
Halo Flow: 基于流程编排思想,开发业务组件,编排应用内部已有业务资产,快速响应前台需求,久而久之形成大量可复用的业务组件库。
-
Halo Cache: 基于流程编排思想,开发业务组件,编排应用内部已有业务资产,快速响应前台需求,久而久之形成大量可复用的业务组件库。
-
Halo ToolKit: 一款IDEA插件,只为加速Halo应用开发而生。
-
Halo Cloud: 对Spring Cloud进行封装增强,简化熟悉使用成本,提高开发效率。更多访问VII Halo Cloud
-
Halo CodeGen: 通过设计代码生成器, 快速生成最佳实践的基础代码和规范,提高开发效率和生产力,让业务开发人员专注于业务开发。
-
Halo Plugin: Halo体系中
-
Halo maven: Halo生态体系中的Maven插件。
-
Halo Standard: Halo制定的开发规范,更多访问开发规范
-
Halo Studio: Halo Studio 基于开源的 IntelliJ Platform进行定制开发扩展,将Halo Toolkit内置其中增强,提供企业级IDE支持。
-
Halo Check:基于
Git Hook+JGit+CheckStyle+PMD对代码增量diff Check是否满足Halo Style。该项目主要用于Git Commit提交的时候对代码进行检查。分为客户端和Gitlab服务端Check
总之,Halo不仅仅只是 一个框架,一种架构,一种思想,一套 可落地业务中台建设 解决方案,而是大型软件研发平台体系!
II Release Note
关于Halo的Release Note可以访问Halo Release Note
III Halo Ecology
1. 什么是光环(Halo)
光环(Halo)是一个企业IT架构生态,专注于解决 基础架构,业务架构,应用架构,业务中台建设,如下图所示。而其中的Halo Core是一款
基于DDD+CQRS+扩展点+流程编排的业务中台应用框架,致力于采用 领域驱动 的设计思想,规范控制程序员的随心所欲,
从而解决软件的复杂性问题。架构原则很简单,即在高内聚,低耦合,可扩展,易理解大的指导思想下,尽可能的贯彻OO的设计思想和原则,以降低开发
的复杂度, 提高开发人员的开发效率, 提升代码质量, 规范开发流程。
Halo在企业IT架构中无所不在,企业IT架构如下所示:
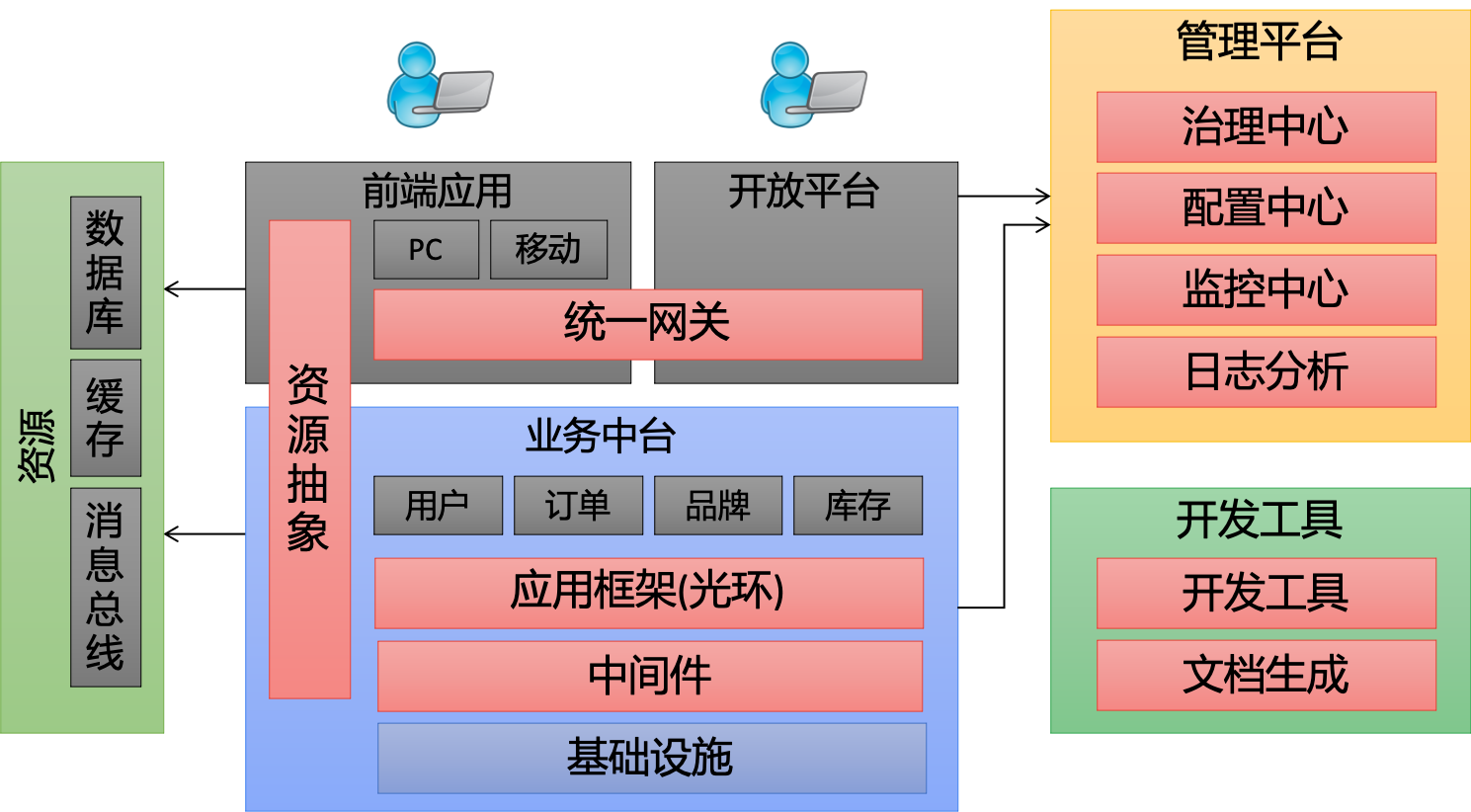
Halo目前也是基础架构的生态,基础架构如下:

-
Halo生态涵盖了WEB, Rest Doc, Halo Boot,服务治理(Halo-Cloud), TDDD, Log, Code Generator等各方面的内容。
-
Halo Framework涵盖
领域驱动设计(DDD),读写分离架构(CQRS),扩展点设计,应用内部流程编排等。
开发人员可以利用Halo-codegen工具,根据设计好的数据库和表,自动生成Halo风格的项目代码。
目前Halo-codegen支持生成带有DDD应用的框架。
2. Halo生态目标
Halo生态的目标如下左图所示,Halo Framework的目标如下右图所示。
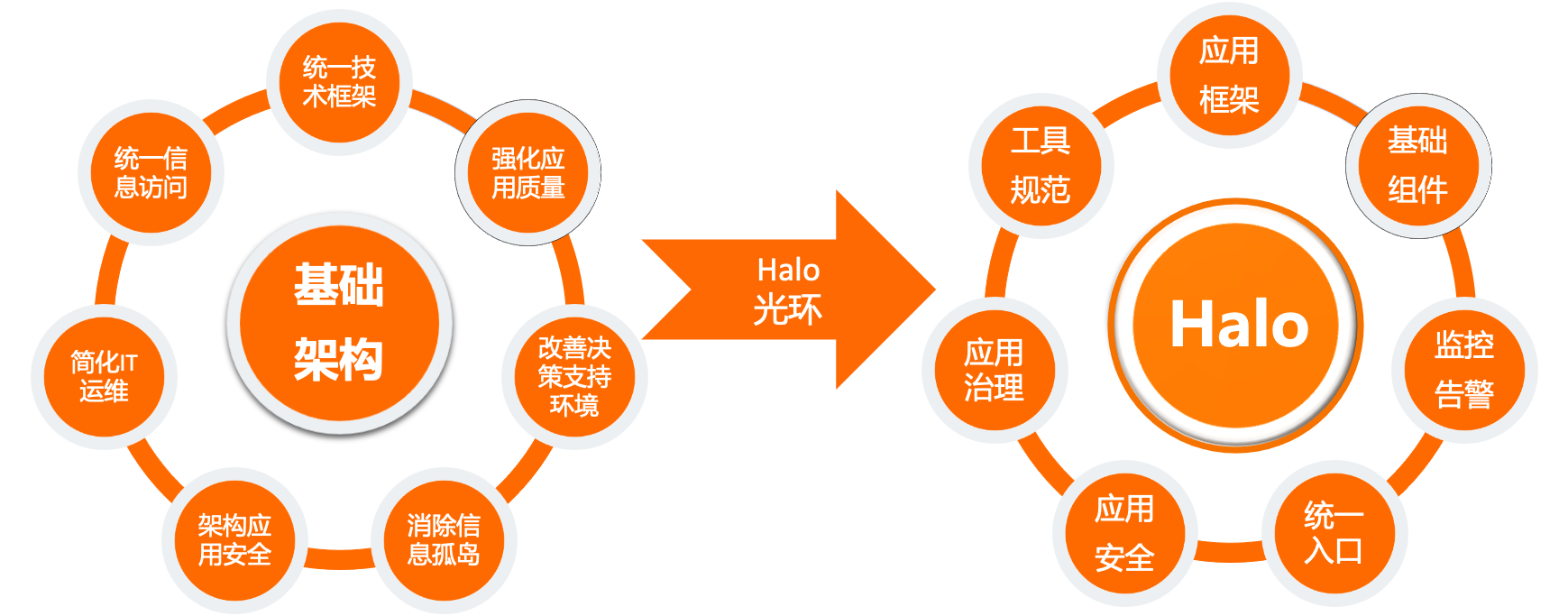
| 开发人员只需要设计好数库表结构,就可以通过Halo-codegen工具自动 生成具有Halo风格的项目基础骨架和基础代码,然后开发人员通过Halo-DDD, Halo-Extension,Halo-Flow去进行业务开发和建模即可。 |

4. Halo生态系统
Halo生态主要包含以下几个大模块,如下所示
-
Halo Framework: Halo Framework是Halo生态的核心框架,起到
承上启下的作用,向上支撑业务开发,构建业务中台,向下整合适配基础设施。-
Halo DDD: 领域驱动方式实现业务和业务隔离
-
Halo Flow: 对业务资产编排复用
-
Halo Extension: 以扩展点方式实现平台和插件隔离
-
-
Halo Boot: Halo Boot是对Spring Boot的增强和扩展
-
Halo Cloud: Halo Cloud是对Spring Cloud的增强和扩展
-
开发工具
-
其它中间件

5. Halo Team
-
设计和开发新一代的基础组件,为重构项目提供技术平台
-
设计和构建统一的应用开发框架(Halo Framework),通过代码生成器(Halo Codegen)提高应用开发效率和质量
-
建立统一的应用开发构建标准,为实现对应用的管理,监控和治理的自动化建立基础
-
评估和引进各种国外先进技术,提高公司平台的技术水准
-
打造业界牛逼的业务中台和应用框架,形成业务可复用的组件库和业务资产,快速响应产品的需求。
-
建立牛逼的开源项目,对含金量高的项目实现开源,以提高知名度。
6. Halo 产品基线
Halo Framework 2.0.0的基线版本如下所示, Halo产品基线定义了Halo产品集,以方便Halo在应用中或重构项目中的推广
| 基础组件 | 版本 | 基线 | 备注 |
|---|---|---|---|
Spring Boot |
2.6.3 |
第三方 |
|
Spring |
5.3.15 |
第三方 |
Spring Boot 2.6.3中内置的版本是5.3.15 |
mysql驱动 |
8.0.25 |
第三方 |
Spring Boot 2.6.3中内置的版本是8.0.25 |
OSM |
1.0.0 |
内部 |
Service Mesh版的RPC框架 |
Nacos |
2.0.4 |
内部 |
Halo体系内进行二开的注册中心和配置中心 |
Chronos |
1.0.0 |
内部 |
分布式任务调度中间件 |
Switch |
1.0.0 |
内部 |
开关中间件 |
Themis |
1.0.0 |
内部 |
基于HicariCP改造的数据库连接池,具有更高的性能,更低的footprint,更完善的监控等,同时支持连接复用和事务优化 |
HCache |
1.0.0 |
内部 |
Halo Cache→Halo体系的缓存框架 |
Juno |
1.0.0 |
内部 |
埋点中间件 |
Janus |
1.0.0 |
内部 |
网关中间件 |
mybatis plus |
3.1.0 |
第三方 |
- |
| 使用Halo Framework只需关心Halo的版本即可,无需关心Spring Boot或者内部中间件的版本,业务应用使用框架即可. |
7. Product Support
Halo框架产品支持,可以扫描下面二维码加入钉钉群或者加微信如下所示:

| 进群后提供Maven私服Settings.xml文件,体验使用! |
IV Halo 快速入门
8. Halo开发环境
使用Halo Framework开发应用要求JDK 1.8+,目前框架已经内置了Spring Boot, Spring Cloud等基础框架.因此无需关心底层框架的版本和实现细节.
8.1. Halo版本说明
| Halo | Spring Cloud | Spring Boot | 备注 |
|---|---|---|---|
2.0.0.RELEASE |
2020.0.0 |
最新稳定版本 |
| 使用Halo Framework只需关心Halo的版本即可,无需关心Spring Boot或者Spring Cloud的版本,业务应用使用框架即可. |
8.2. Halo应用类型
Halo目前支持三种应用类型,如下表所示:
| 应用类型 | 说明 | 备注 |
|---|---|---|
经典DDD应用 |
具有分层架构,适用于业务复杂,适合做成中台的系统 |
推荐使用 经典DDD分层 |
简化DDD应用 |
具有分层架构,适用于业务复杂,适合做成中台的系统 |
更多访问Halo简化版DDD分层 |
传统三层应用 |
传统三层(Controller,Service Dao)应用,适用于简单应用,定时任务应用,工具型应用,基础服务应用 |
只用Halo的Starter和命令Halo传统三层分层 |
| 应用类型,用于约定应用内部的开发公约,主要用于统一应用的开发模式和代码写法。都会被Halo Admin纳管,形成一个体系,统一开发模式。 |
8.3. Halo Release Note
8.3.1. Halo 2.0.0.RELEASE
-
Halo
-
@Command注解更新为@CmdHandler注解
-
增加Halo State Machine(基于Spring状态机进行定制增强开箱即用)
-
增加@AggregateRoot(聚合根), @UniqueIdentity(实体唯一标识),@AggregatePart(聚合部件)注解
-
-
Halo Boot
-
升级Spring Boot版本为2.4.1.RELEASE
-
增加Halo InfluxDB
-
增加Halo Shiro
-
Halo Es7 Fix SocketTimeOut
-
halo Swagger支持GlobalOperationParameters
-
halo MongoDB支持多数据源支持
-
Halo Web增加断言结合全局异常处理器
-
Halo Web 404 Not Found异常处理
-
Halo MyBatis增加开启乐观锁
-
Halo Redis中的redisson-spring-data-21升级到版本为3.12.3
-
-
Halo Cloud
-
Open Feign支持OKhttpClient支持
-
升级Spring Cloud版本为2020.0.0
-
Fix Spring Cloud升级之后导致eureka Client应用返回值Json变Xml
-
-
halo CodeGen支持新的Halo 2.0.0.RELEASE版本
-
halo ToolKit支持把代码模板抽取到远端管控
8.3.2. Halo 1.1.0.Release
-
halo
-
增加无参命令支持
-
Halo打包式自动加入Halo框架版本,应用启动上报halo版本
-
应用启动check当前应用是否属于某个域,开发,测试,UAT环境-只做应用归属check,不做收集,Halo版本上报处理
-
fastJson升级为最新版本1.2.62
-
增加@AppService注解,用于应用层查询服务
-
增加黄金三步法@Phase和@Step注解
-
增加领域层@Port注解
-
增加基础设施层@Adapter注解
-
-
Halo Boot
-
增加Halo Es6
-
增加Halo Es7
-
增加Halo alimq
-
增加halo mongodb
-
增加halo redis
-
重构整理halo Swagger
-
Halo Mybatis支持空Where Sql拦截功能
-
重构整理halo Web,增加打印日志注解
-
Halo web全局异常解析器增加HttpMediaTypeNotSupportedException和IllegalArgumentException统一异常处理
-
增加脱敏
-
-
Halo Admin
-
菜单增加角色可配
-
结合数据字典-Halo版本分布动态报表
-
应用增加时-添加所选框架版本
-
收集域服务(@DomainService),域能力注解
-
中台成熟度模型-增加域服务和域能力两个指标
-
halo admin中无参的命令空类更新为无参的命令
-
-
Halo Codegen
-
Halo Codegen支持选择所属业务域创建
-
8.3.3. Halo 1.0.0.Release
-
2018年7月-Halo 1.0.0.RELEASE
-
Halo框架从0到1整体功能发布
-
8.4. maven依赖引入
Halo Framework由统一的parent或dependencyManagement管理依赖, 引入到工程中有两种引入方式:
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>8.5. Halo Starter列表
1.Halo Boot相关的Starter列表如下所示:
| 名称 | 描述 | 备注 |
|---|---|---|
halo-boot-starter-basic |
包含Halo Framework中的CQRS,DDD,扩展点功能 |
|
halo-boot-starter-flow |
包含Halo Framework中的流程编排 |
更多访问流程编排 |
halo-boot-starter-mybatis |
对Mybatis,Mybatis Plus进行定制扩展 |
更多访问Halo Mybatis |
halo-boot-starter-apollo |
对Apollo进行定制扩展封装 |
更多访问Halo Apollo |
halo-boot-starter-swagger |
对Swagger进行定制扩展,实现开箱即用 |
更多访问 Halo Swagger |
halo-boot-starter-web |
对Spring web封装增强和定制 |
更多访问 Halo Web |
halo-boot-starter-job |
对xxl-job-core封装成Spring Boot Starter |
更多访问 Halo Job |
halo-boot-starter-alimq |
对阿里RocketMQ进行封装 |
更多访问 Halo AliMQ |
halo-boot-starter-redis |
支持Redisson,增加Redis工具类 |
更多访问 halo Redis |
halo-boot-starter-redisson |
支持Redisson,增加Redis工具类 |
更多访问 Halo Redisson |
halo-boot-starter-mongodb |
对Spring Boot MongoDB封装增强和定制 |
更多访问 Halo MongoDB |
halo-boot-starter-es6 |
基于Elastic Search 6.3.2封装的Spring Boot Starter |
|
halo-boot-starter-es7 |
基于Elastic Search 7.2.1封装的Spring Boot Starter |
|
halo-boot-starter-test |
对spring boot test封装定制 |
更多访问 Halo Test |
halo-boot-starter-shiro |
对Shiro+JWT进行扩展封装支持LDAP Realm和DB Realm |
更多访问 Halo Shiro |
halo-boot-starter-influxdb |
对influxdb-java进行封装比提供InfluxDBTemplate以及常用的操作 |
更多访问 Halo influxDB |
halo-boot-starter-mapstruct |
对MapStruct封装定制 |
更多访问 Halo MapStruct |
halo-boot-starter-mail |
对spring-boot-starter-mail进行封装定制 |
更多访问 Halo Mail |
halo-boot-starter-retrofit |
对retrofit进行封装定制 |
更多访问 Halo Retrofit |
2.Halo Cloud的Starter列表如下所示:
| 名称 | 描述 | 备注 |
|---|---|---|
halo-cloud-starter-nacos |
对Spring Cloud Alibaba中的Nacos进行扩展封装 |
更多访问Halo Cloud Nacos |
halo-cloud-starter-eureka |
对Eureka,Ribbon进行定制扩展 |
更多访问Halo Eureka |
halo-cloud-starter-openfeign |
对Open Feign进行定制扩展 |
更多访问Halo Feign |
8.6. Halo Starter说明
halo-booot-starter-basic包含了CQRS,DDD,扩展点功能.需要如下maven依赖
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-basic</artifactId>
</dependency>如果需要使用流程编排的功能,需要引入halo-boot-starter-flow,Maven依赖如下所示:
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-flow</artifactId>
</dependency>Halo Framework的默认扫描包是Spring Boot主入口程序的所在包以及子包,但是可以通过如下配置自定义命令,扩展点,命令拦截器等的扫描包, 配置如下yml文件所示
halo:
command-scan-packages: org.xujin.halo.command
extension-scan-packages: org.xujin.halo.extension
post-interceptor-scan-packages: org.xujin.halo.interceptor
pre-interceptor-scan-packages: org.xujin.halo.interceptor
custom-scan-package: true
10. 创建应用
可以使用网页版代码生成器或者IDEA插件直接创建应用,启动信息如下:
,--,
,--.'| ,--,
,--, | : ,--.'|
,---.'| : ' | | : ,---. Halo Version: 2.0.0-SNAPSHOT
| | : _' | : : ' ' ,'\ Port: 8080 Pid: 16859
: : |.' | ,--.--. | ' | / / |
| ' ' ; : / \ ' | | . ; ,. :
' | .'. | .--. .-. | | | : ' | |: : 更多访问:http://xujin.org/
| | : | ' \__\/: . . ' : |__ ' | .; : 联 系:Software_King@qq.com
' : | : ; ," .--.; | | | '.'| | : |
| | ' ,/ / / ,. | ; : ; \ \ /
; : ;--' ; : .' \ | , / `----'
| ,/ | , .-./ ---`-'
'---' `--`---'
>>>>>>>>>>>>光环(Halo),专注于基础架构,应用架构,业务架构和中台建设!<<<<<<<<<<<<
:: Spring Boot :: 2.4.1
:: Spring Cloud :: 2020.0.0
2020-12-27 11:28:33.430 INFO 16859 --- [ main] o.xujin.halo.admin.HaloAdminApplication : Starting HaloAdminApplication using Java 1.8.0_251 on Halo.local with PID 16859 (/xujin/code/halo-admin/halo-admin-start/target/classes started by xujin in /xujin/code/halo-admin)
2020-12-27 11:28:33.434 INFO 16859 --- [ main] o.xujin.halo.admin.HaloAdminApplication : No active profile set, falling back to default profiles: default11. 使用命令
11.1. 编写命令对象
@Data
public class AddAppCmd extends CommonCommand {
@ApiModelProperty("应用ID")
private String appId;
@ApiModelProperty("应用中文名")
private String name;
@ApiModelProperty("应用所有者")
private String ownerName;
@ApiModelProperty("应用所有者ID")
private Integer ownerId;
@ApiModelProperty("应用描述")
private String description;
@ApiModelProperty("spring应用名称")
private String springApplicationName;
}11.2. 编写命令执行器
下面是增加一个App的命令,代码如下所示:
public class AddAppCmdExe implements CommandExecutorI<ResultData<Long>, AddAppCmd>{ (1)
@Autowired
AppService appService; (2)
@Autowired
AppClientConvertor appClientConvertor; (3)
@Override
public ResultData<Long> execute(AddAppCmd addAppCmd) {
AppE appE = appClientConvertor.clientToEntity(addAppCmd);(4)
ResultData<Long> resultData = ResultData.builder(null);
if (!check(appE, resultData)) {
return resultData;
}
try {
appE.save();
resultData.setData(appE.getId());
} catch (Exception ex) {
log.error(String.format("add app failed, appE=%s", appE), ex);
resultData.setSuccess(false);
resultData.setCode(500);
resultData.setMsgContent("添加失败");
}
return resultData;
}
protected boolean check(AppE appE, ResultData<Long> resultData) { (5)
try {
Preconditions.checkNotNull(appE, "appE不能为null");
Preconditions.checkArgument(!appService.containsAppId(appE.getAppId()), "appId不能重复");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getAppId()), "appId不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getName()), "name不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getOwnerName()), "ownerName不能为空");
Preconditions.checkNotNull(appE.getOwnerId(), "ownerId不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getDescription()), "description不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getSpringApplicationName()), "springApplicationName不能为空");
} catch (Exception ex) {
resultData.setSuccess(false);
resultData.setMsgContent(ex.getMessage());
return false;
}
return true;
}
}以下介绍命令执行器的注意事项:
| 1 | AddAppCmdExe需要实现CommandExecutorI接口,其中CommandExecutorI<ResultData<Long>, AddAppCmd>的ResultData<Long>是命令返回的结果,AddAppCmd是命令对象。 |
| 2 | appService是示例的领域服务 |
| 3 | appClientConvertor是转换防腐层,从App层进入Domain层需要转换防腐。 |
| 4 | 把客户端对象转换为实体 |
| 5 | 验证传入的addAppCmd命令对象是否合法 |
11.3. 发送命令
@Autowired
private CommandBus commandBus; (1)
@PostMapping("")
@ApiOperation(value = "增加应用")
public ResultData<Long> addApp(@RequestBody AddAppCmd addAppCmd) {
return commandBus.send(addAppCmd); (2)
}| 1 | 在需要发送命令的地方,依赖注入CommandBus |
| 2 | commandBus.send发送命令对象 |
12. 扩展快速入门
12.1. 编写一个扩展点
如下所示定义一个扩展点
package org.xujin.halo.extension;
import org.xujin.halo.annotation.extension.ExtensionPoint;
@ExtensionPoint(name = "支付扩展点", desc = "PayExtPt Desc") (1)
public interface PayExtPt extends ExtensionPointI {
public String pay(Object object);
void pay();
}以下介绍编写扩展点的注意事项:
| 1 | @ExtensionPoint是一个扩展点注解,其中name和desc为必填属性。 |
12.1.1. 编写一个扩展
如下所示实现PayExtPt接口,编写了两个扩展
package org.xujin.halo.extension;
import org.xujin.halo.annotation.extension.Extension;
/**
* 支付宝支付扩展
* @author xujin
*/
@Extension(name = "支付包支付扩展", bizCode = "com.pay.alipay",desc = "支付宝支付扩展") (1)
public class AliPayExtension implements PayExtPt {
@Override
public String pay(Object object) {
return "支付包支付扩展";
}
@Override
public void pay() {
}
}| 1 | 其中的bizCode = "com.pay.alipay"是业务身份,业务身份之间用.隔开,一般来说是:一级业务身份.二级业务身份.三级业务身份 |
package org.xujin.halo.extension;
import org.xujin.halo.annotation.extension.Extension;
package org.xujin.halo.extension;
import org.xujin.halo.annotation.extension.Extension;
@Extension(name = "微信支付扩展", bizCode = "com.pay.weixinPay",desc = "微信支付扩展")
public class WeiXinPayExtension implements PayExtPt {
@Override
public String pay(Object object) {
return "微信支付扩展";
}
@Override
public void pay() {
}
}12.2. 调用执行扩展
下面的代码示例是在Controller中调用执行一个扩展点,示例代码如下所示:
@RestController
@RequestMapping("/admin/test")
public class TestController {
/**
* 依赖注入扩展执行器
*/
@Autowired
private ExtensionExecutor extensionExecutor; (1)
@GetMapping("/extensionExe")
public String exeExtension() {
Context context = new Context();
context.setBizCode("com.pay.alipay"); (2)
String result=extensionExecutor.exeReturnValue(PayExtPt.class,context, extension -> extension.pay(null)); (3)
extensionExecutor.exeReturnVoid(PayExtPt.class,context,extension1 -> extension1.pay()); (4)
return result;
}
}通过上述代码,介绍一下调用扩展点的注意事项
| 1 | 表示通过@Autowired依赖注入ExtensionExecutor |
| 2 | 表示通过context.setBizCode("com.pay.alipay")设置业务身份 |
| 3 | 表示通过extensionExecutor.execute执行扩展传入的参数分别是扩展点,上下文,函数式调用的扩展方法 |
14. Halo DDD使用
如何使用Halo DDD具体使用请参考halo DDD实战
15. Halo QA
1.如果出现如下的错误信息,即命令没有在CommandHub中找到
{
"timestamp": "2019-05-29T02:20:46.054+0000",
"status": 500,
"error": "Internal Server Error",
"message": "class org.xujin.order.client.cmo.AddOrderCmd is not registered in CommandHub, please register first",
"path": "/createOrder"
}| 原因:说明工程中有两个命令对象都叫AddOrderCmd,命令对象是不允许重复和复用,一个命令对应唯一的一个业务请求意图。 |
2.ddd的编码方案是否适合每个中心,库存中心这样高并发更新的场景适合用ddd的编码方式吗?
| ddd的编码方案,不一定适用某个中心,有时候写起来会比较别扭.如果是简单,传统的,一些服务没有必要。比如只有接口,Job,跑批的服务. |
3.按照ddd理论,repository获取和更新都是针对聚合根,但在一个聚合根里面嵌套了很多实体的情况下,这样保存和获取可能会存在性能问题,或者有很多麻烦(比如更新订单列表,在基础设施层需要判断哪些记录时新增的,哪些时修改的,哪些时删除的,很麻烦,更有三层嵌套的情况会更加复杂)
| 可以向基础设施层直接发送保存某个单条entity的命令,不按照聚合根维度save.如果是复杂的业务推荐的做法是领域服务调用实体或者值对象,完成自己的行为。 |
4.ddd的开发模式来看,领域层的代码和非领域层的代码是否有必要分成由不同团队人员进行?如果是,是否有经验分享。你们在实施ddd的过程中,领域层的自动化测试是由什么角色承担?
| 领域层的代码和非领域层的代码可以分成不用的团队人员进行。比如应用层和基础设施层的人可以是1-3年或者1-2年的工程师去编写,领域层是是架构师或者3年以上的人处理 |
5.DomainService是必须有的吗?一个模块只有一个聚合根的时候,是否有必要有domainService,domainService 只能调用模块内的不同聚合根,还是可以调用其他模块的聚合根?
| 领域服务是按领域来划分,不是按聚合根来划分。 一般来说领域对象有自己的的行为和能力,可以自己处理的,则不需要通过Domain Service去处理. Domain Service可以调用当前领域内的领域对象(也就是既可以调用实体也可以调用值对象),但是不能访问或者调用其它领域的东西。 |
6.领域对象可以直接持有repository吗?
可以直接持有,领域对象因为不是Spring Bean所以,可以把repository作为一个属性处理,如下代码所示:
@Entity
@AggregateRoot
@Data
public class CustomerE {
@UniqueIdentity
private Long customerId;
private CustomerRepository customerRepository;
private String name;
@DomainAbility
public void save(){
customerRepository.save(this);
}
}7.基础设施层除了保存领域对象以外可以做一些其它操作吗,比如更新某个实体的最后修改时间,其版本号这些?
| 基础设施层主要是提供整个应用的基础设施,比如和db,redis,mq,rpc和rest等打交道。 基础设施层没有实体,只有数据对象也就是DataObject,最终会变成数据对象进行更新。 |
8.halo和cola有哪些显著的异同
Halo吸取了Cola和TMF的优点。最大的不同就是结合DDD和中台有自己的实现。
9.转换层和资源库层出现循环依赖处理?
Halo基于Spring Boot 2.4.1版本升级之后出现Spring依赖强校验循环依赖.
RuleFileConverter依赖RuleFileRepository
@Component
public class RuleFileConverter implements ConverterI {
@Autowired
RuleFileRepository ruleFileRepository;
@Autowired
RuleItemRepository ruleItemRepository;
}而RuleFileRepository依赖RuleFileConverter
@DomainRepository
public class RuleFileRepository {
@Autowired
@Lazy //启动延迟加载bean,调用时再去初始化
RuleFileConverter ruleFileConverter;
@Autowired
RuleFileMapper ruleFileMapper;
}| @Lazy注解的功能是,在Spring 在启动的时候延迟加载这个bean,然后在即调用这个bean的时候再去初始化, 这样就避免了Spring循环引用的异常 |
16. Halo ToolKit
Halo ToolKit是一个IDEA插件专为使用Halo Framework开发应用而生。
16.1. IDEA Plugin 功能
IDEA Plugin加速Halo 应用开发而生。目前主要包含如下功能:
-
1、支持向导式快速搭建中台应用和传统应用
-
2、在应用Spring Application启动入口程序中中点击@Domain前面的图标可快速维护应用和中台业务域的关系
-
3、Halo Setting中的Halo Server支持自定义代码生成器服务端和Halo Admin中台可视化服务端URL
-
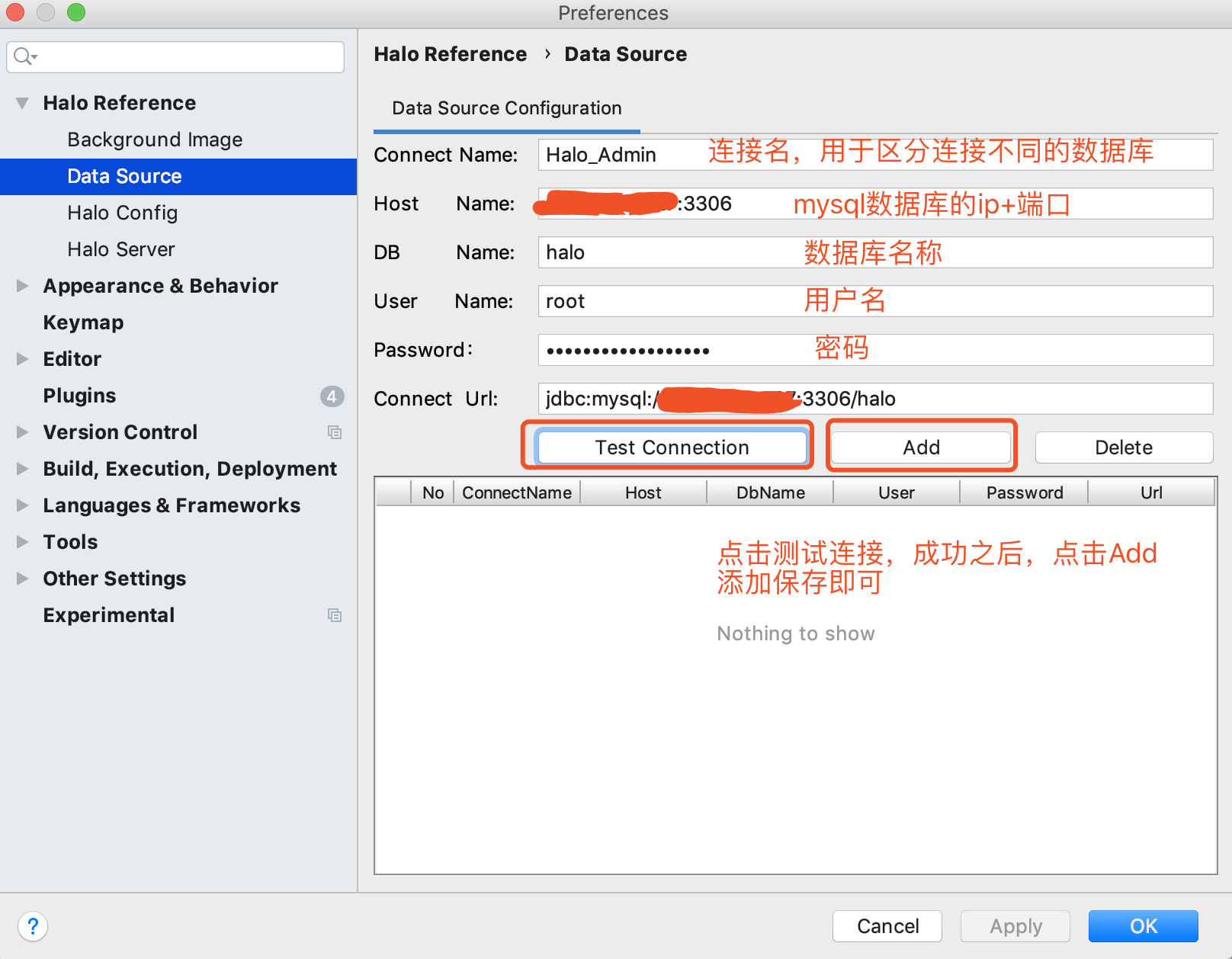
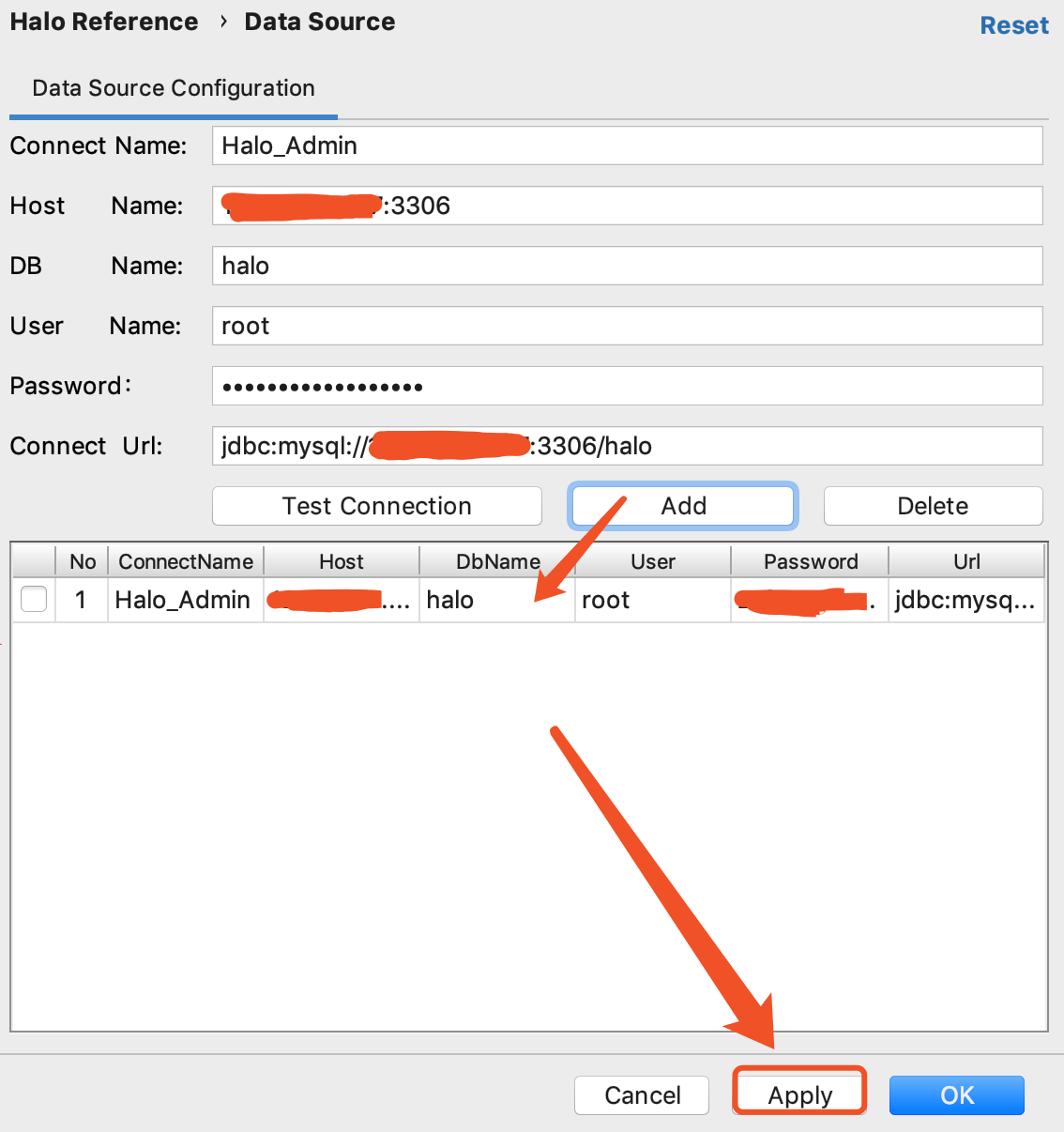
4、Halo Setting中的Data Source支持对数据源进行管理
-
5、Halo Setting中的Halo Config支持对插件的功能进行关闭和打开
-
6、右键支持创建13种Java类,包括创建实体,域服务,流程,资源库,Controller等
-
7、右键创建数据对象支持选择数据库连接和向导式创建工程支持选择数据库连接
16.2. 安装IDEA Plugin
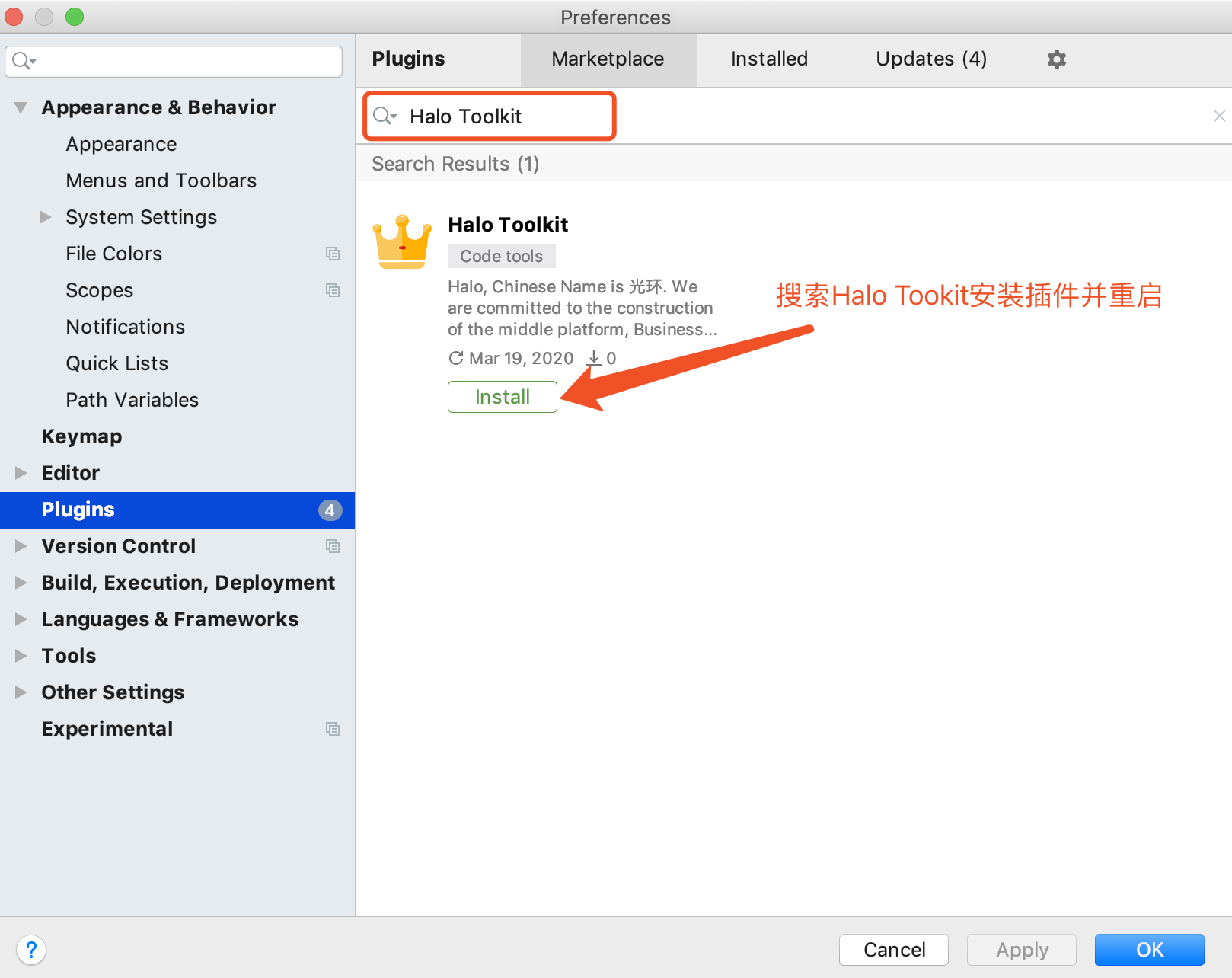
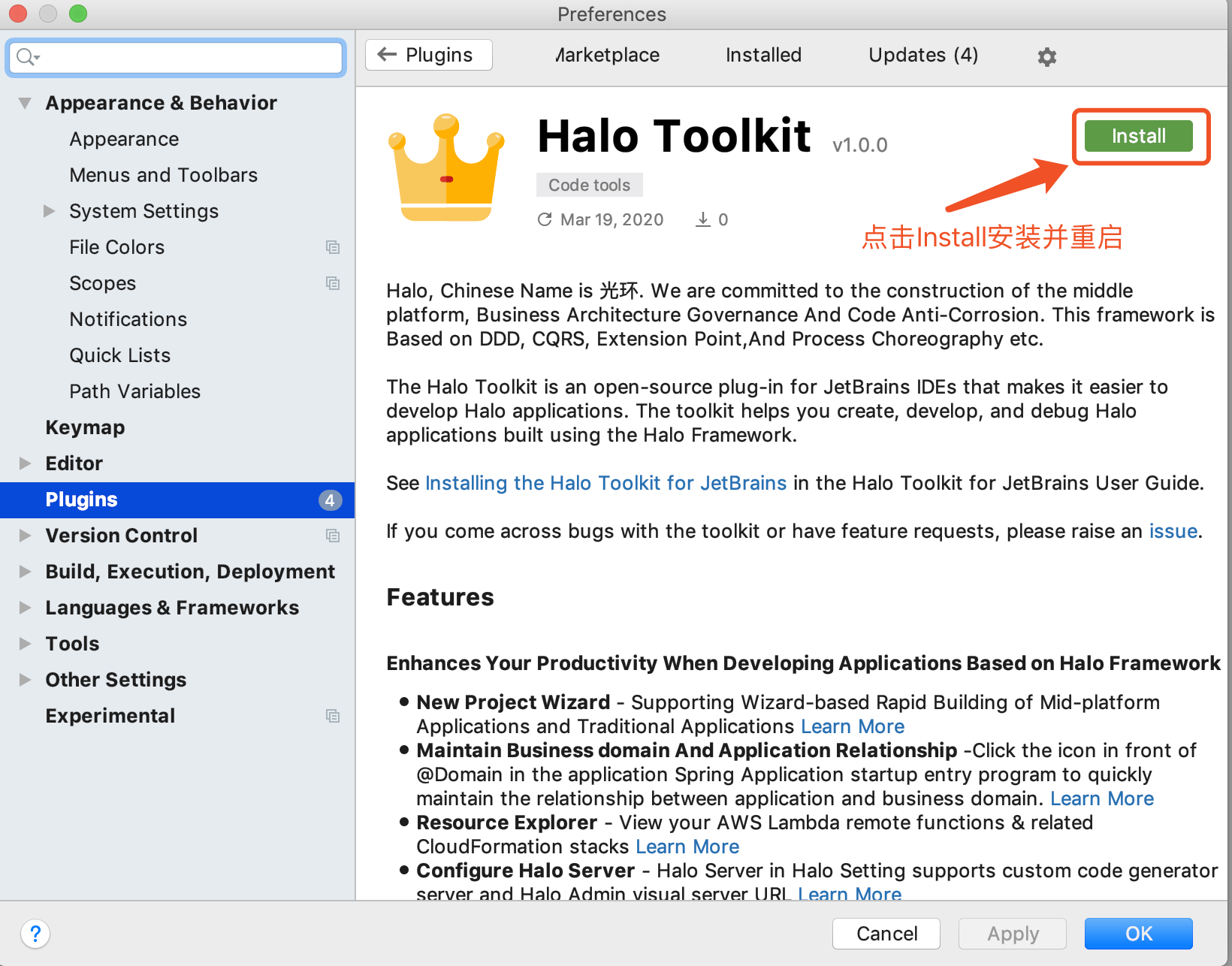
1.打开IDEA在IDEA插件市场中,搜索Halo Tookit进行安装,如下图所示:
17. 快速使用IDEA插件
17.1. Halo Settings
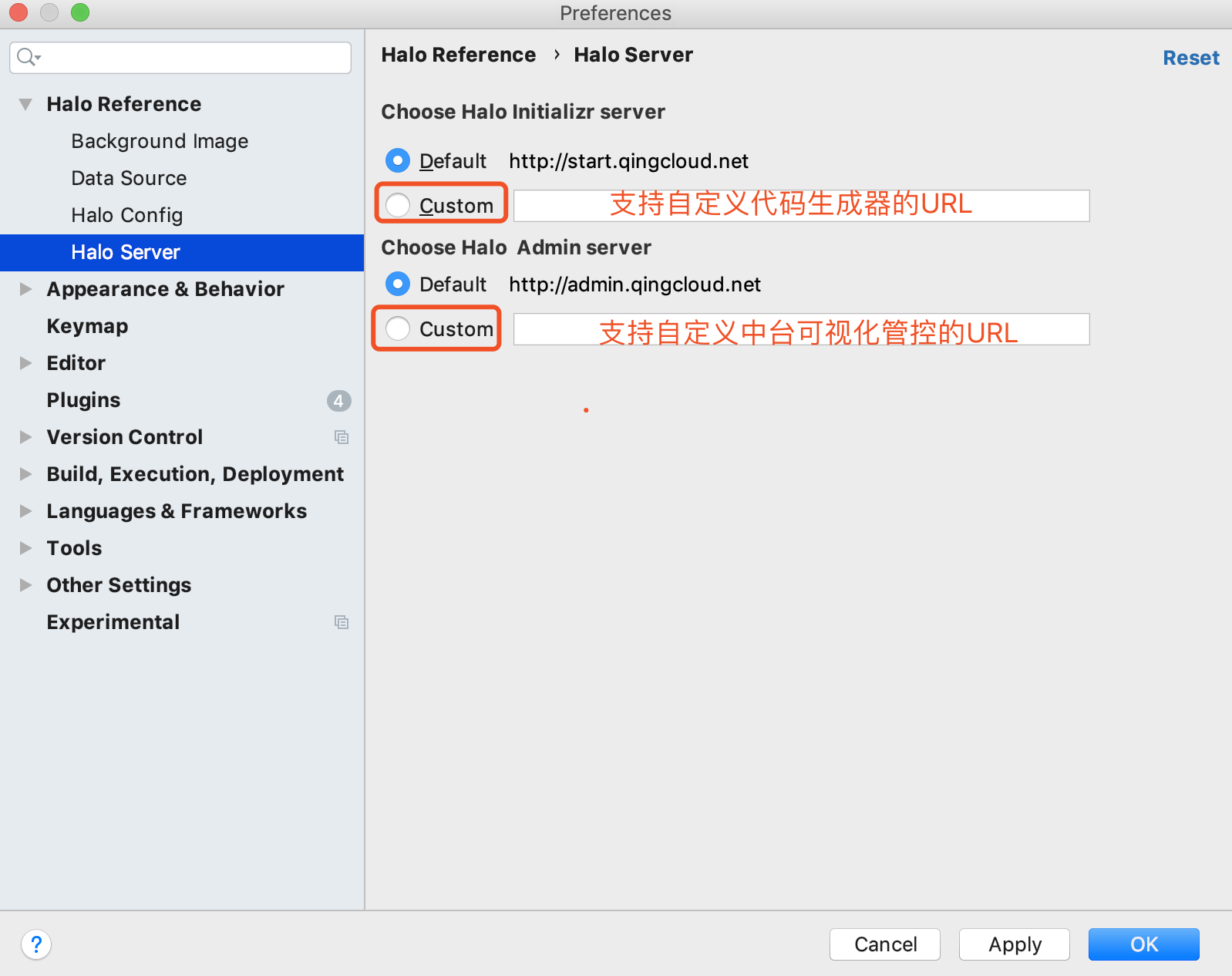
17.1.1. Halo Server设置
Halo ToolKit支持自定义Halo框架对应的代码生成器服务端和Halo Admin可视化中台管控服务端,如下图所示:
|
主要方便内网部署服务端和使用本地的服务端 |
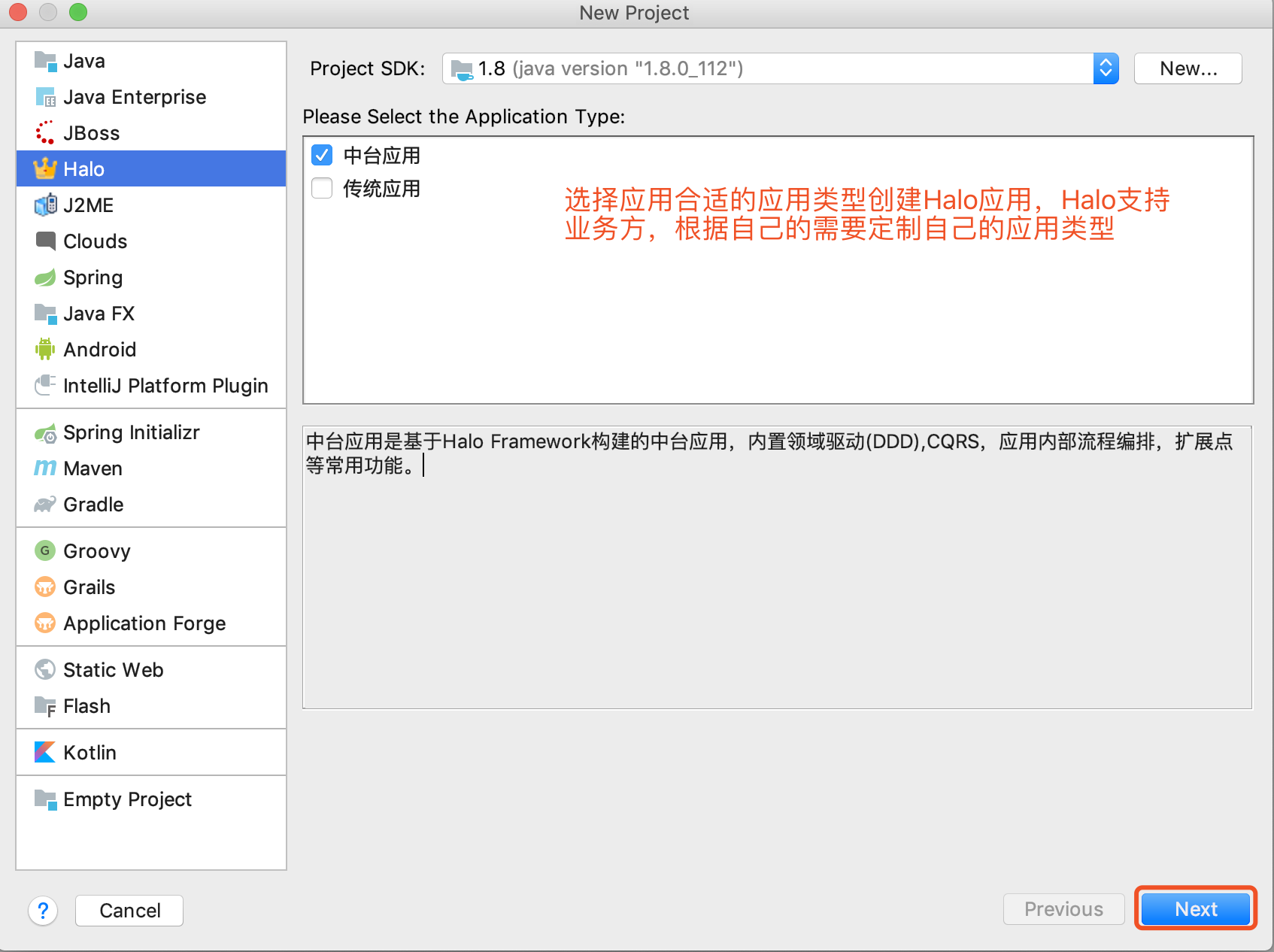
17.2. 创建 Halo Project
1.选择Halo,开始创建Halo工程,如下图所示:
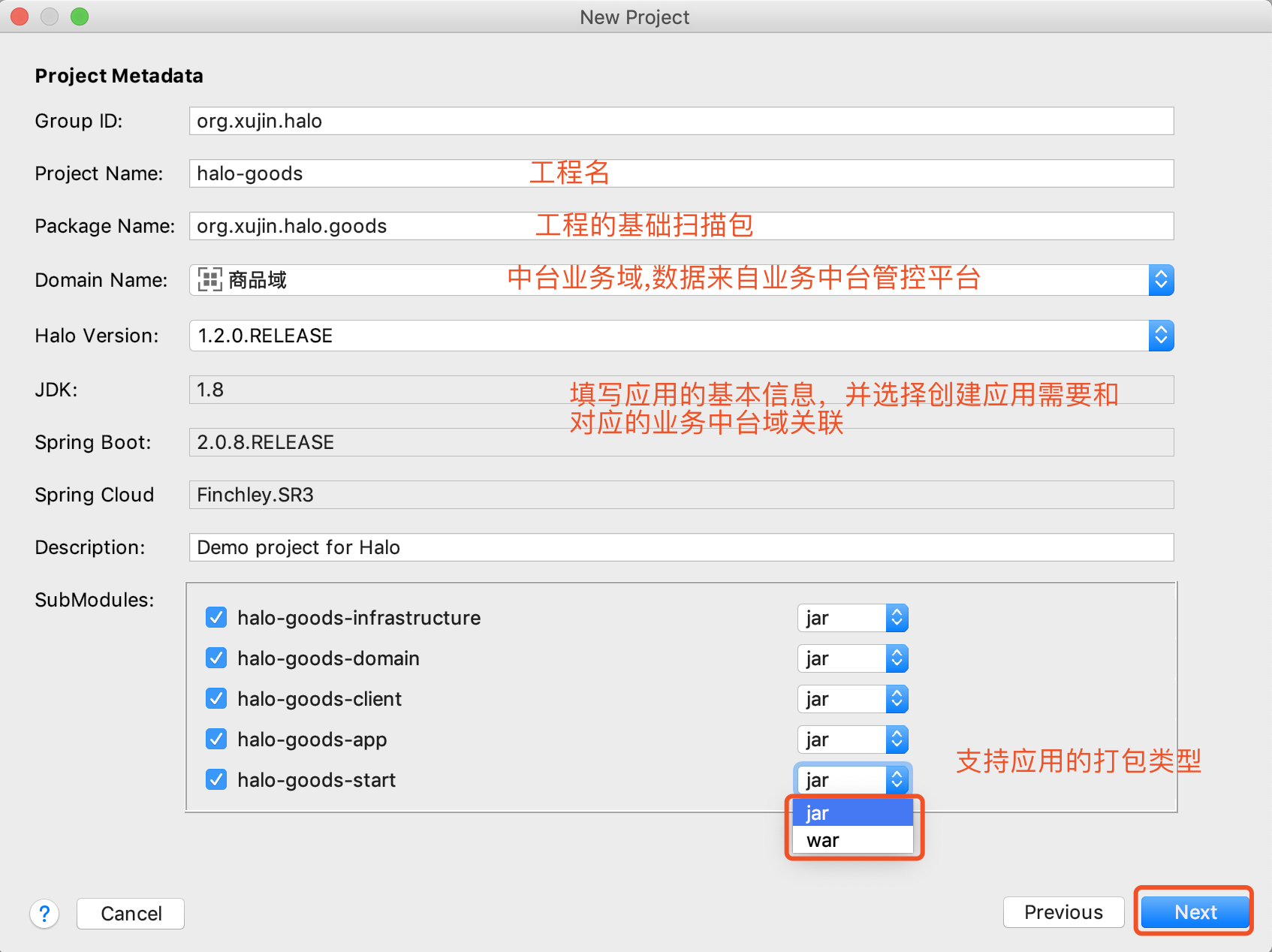
2.填写工程的基本信息和模块信息,如下图所示:
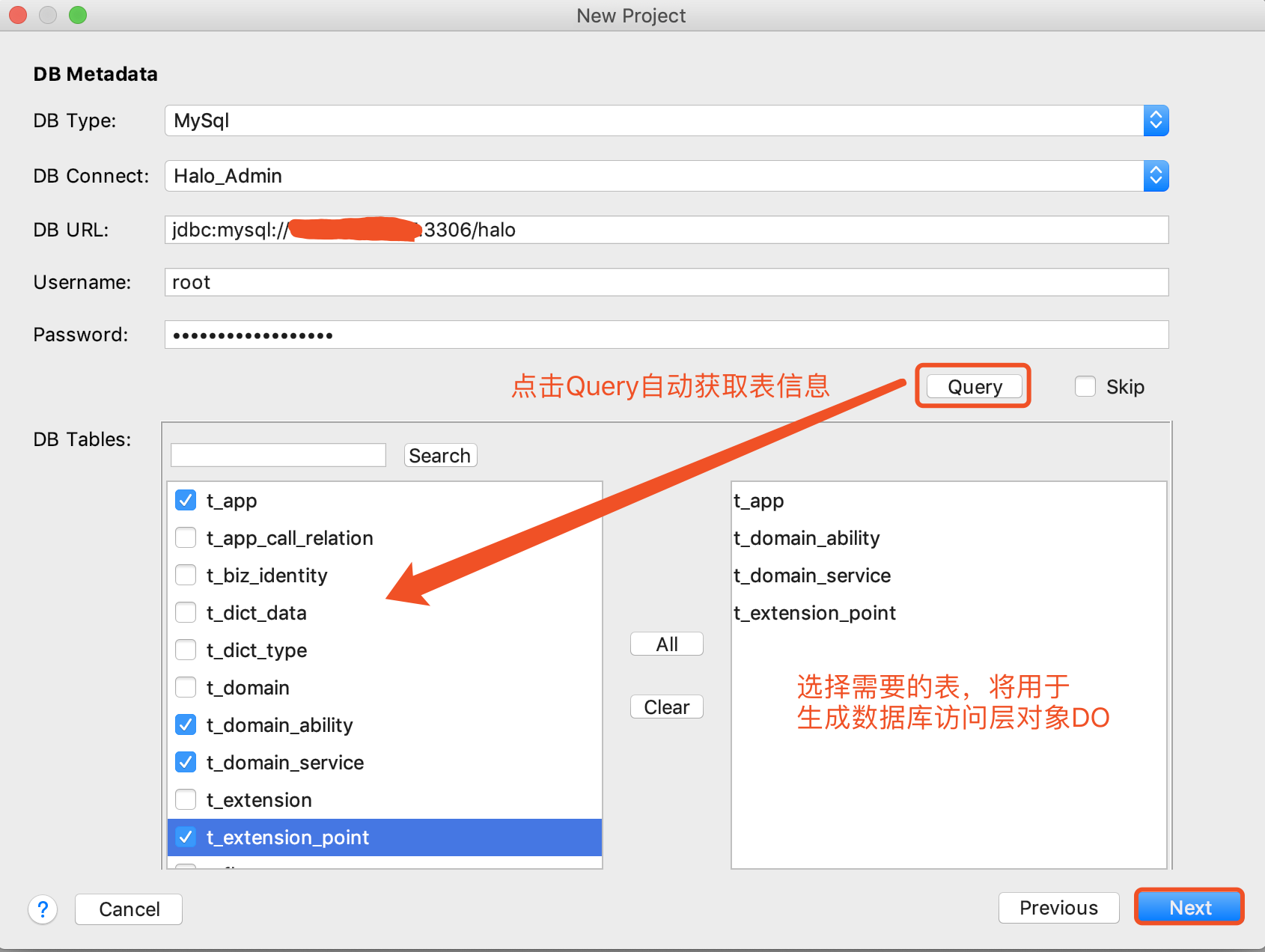
3.如果需要通过数据库中的表生成MyBatis对应的Mapper和数据对象,如下图所示:
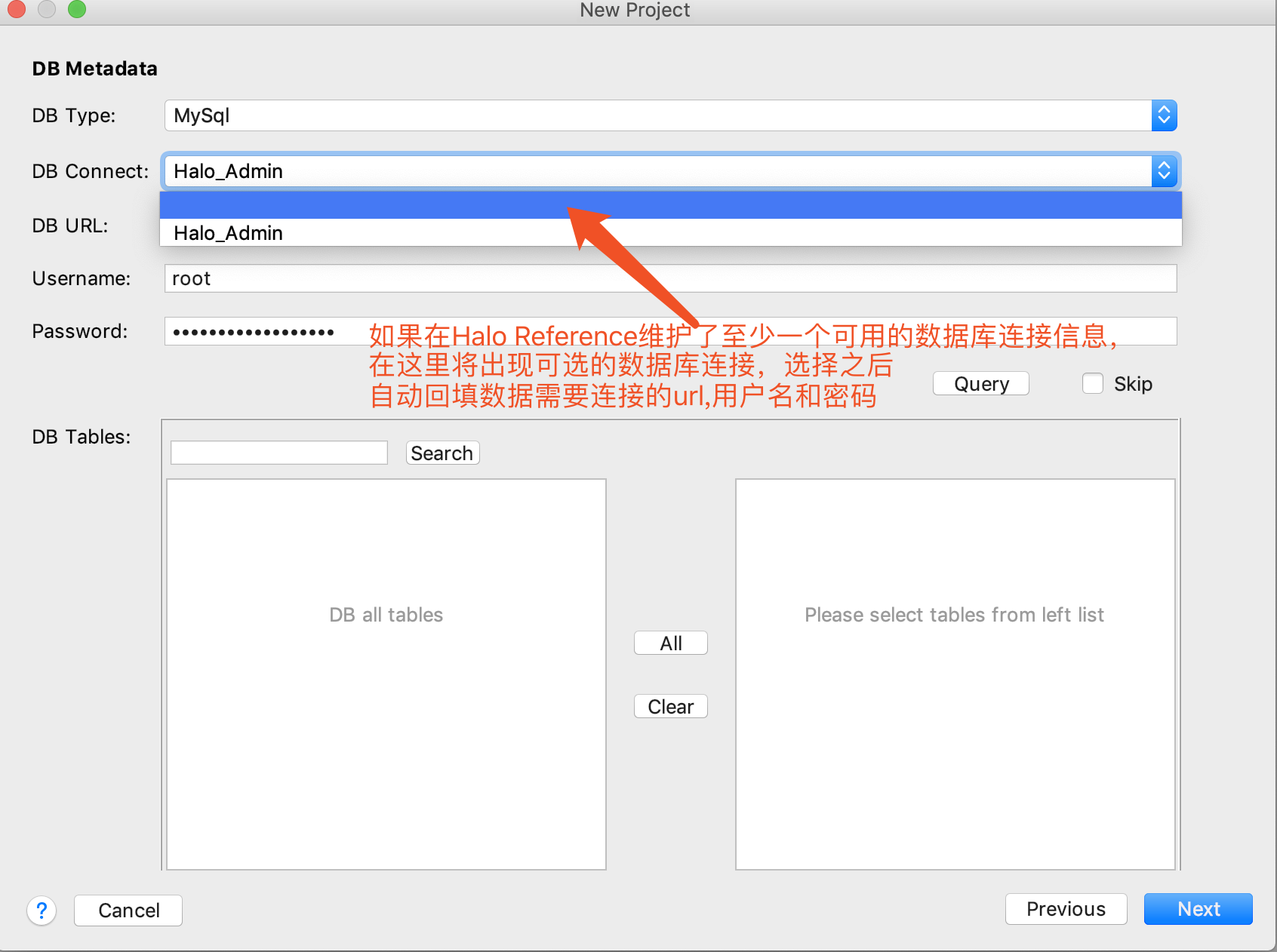
|
如果在Halo Reference维护了至少一个可用的数据库连接信息,在这里将出现可选的数据库连接,如上图所示,否则如下图所示 |
4.设置工程的存储位置(无需设置直接Finish),点击Finish完成
|
创建完毕的Halo Project,IDEA插件自动会刷新工程的Jar依赖,刷新完毕之后,可以直接运行工程。 |
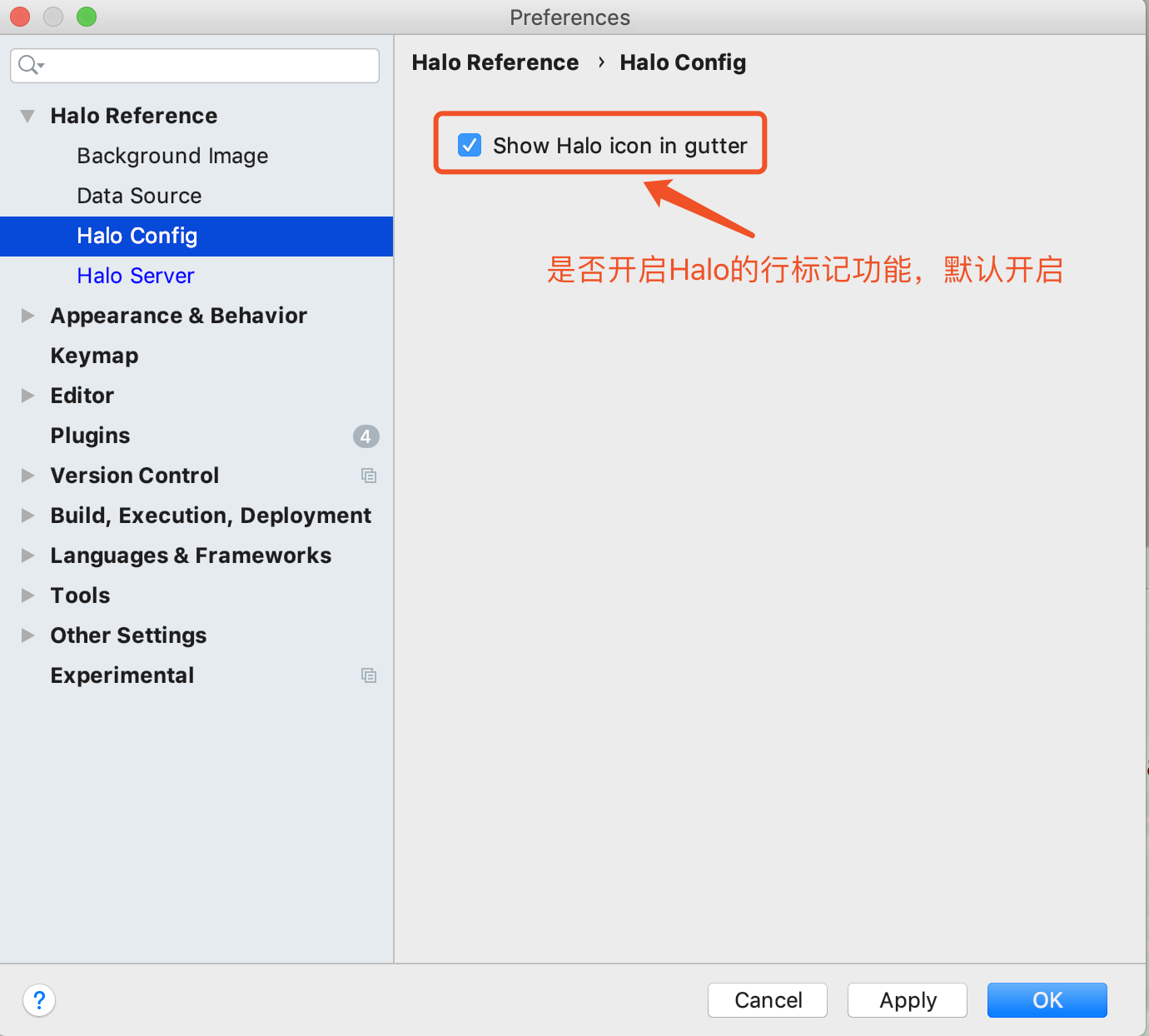
17.3. 行标记功能
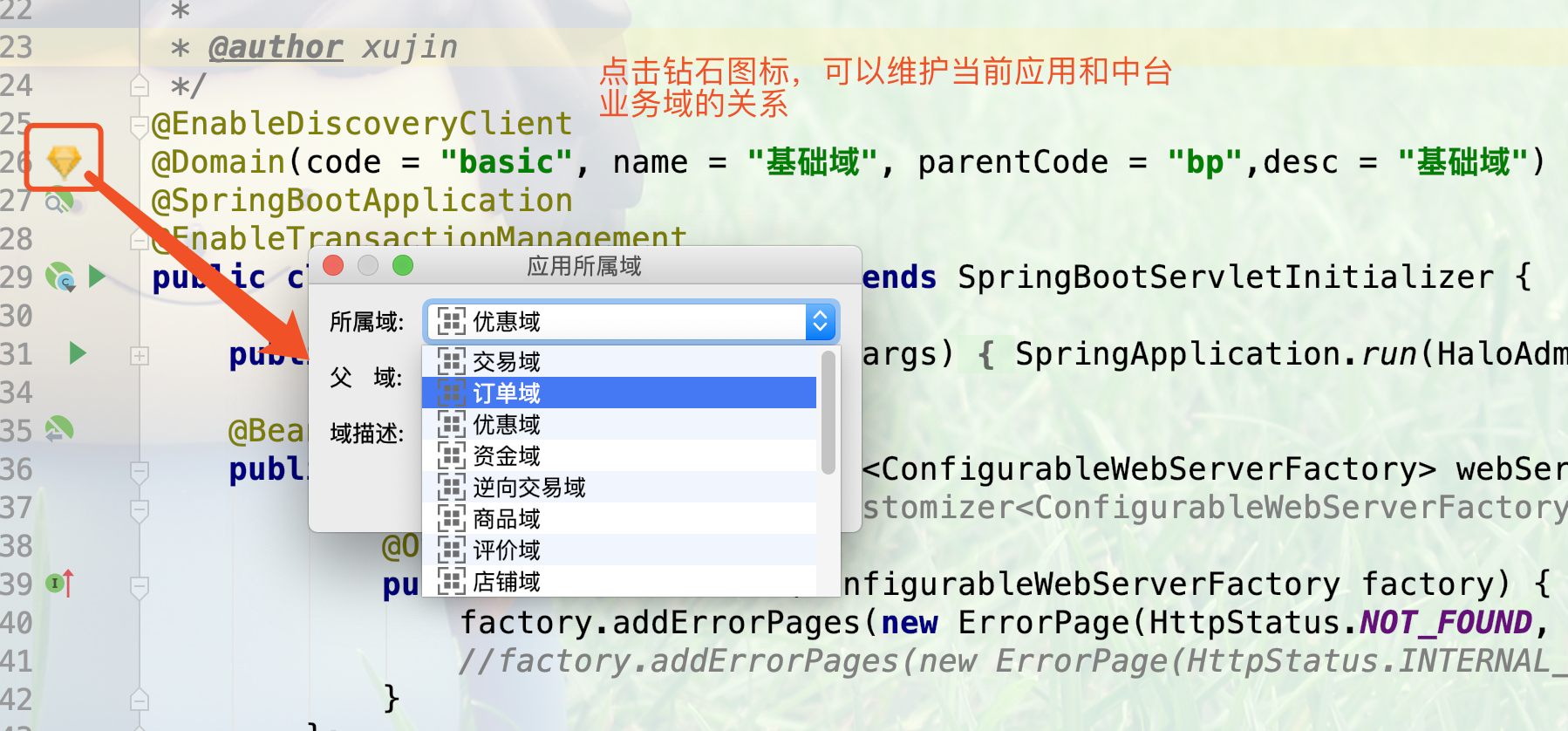
17.3.1. @Domain行标记修改
Halo框架所创建的应用需要管中台可视化纳管,因此当应用启动的时候会判断当前应用是否属于某个域,不属于某个域将停止启动,HaloTools提供一个快速修改编辑的功能。如下图所示:
17.4. 增强右键功能
Halo ToolKit提供右键增强功能,帮助开发快速创建常用的Java类,提高开发效率。
17.4.1. 创建Controller
-
如下图所示,右键点击controller包创建Controller
2.输入Controller对应的类名,下拉列表选择创建Controller
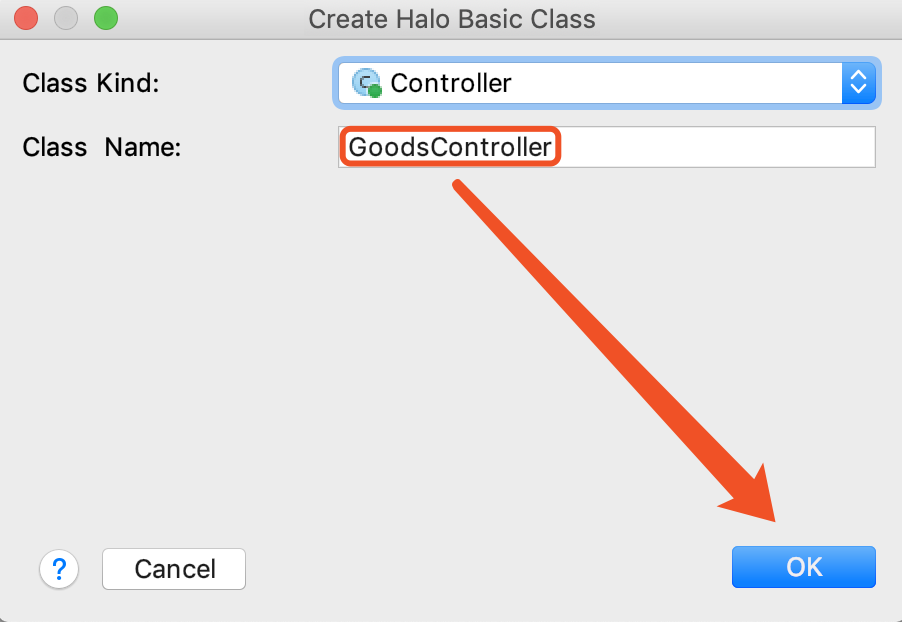
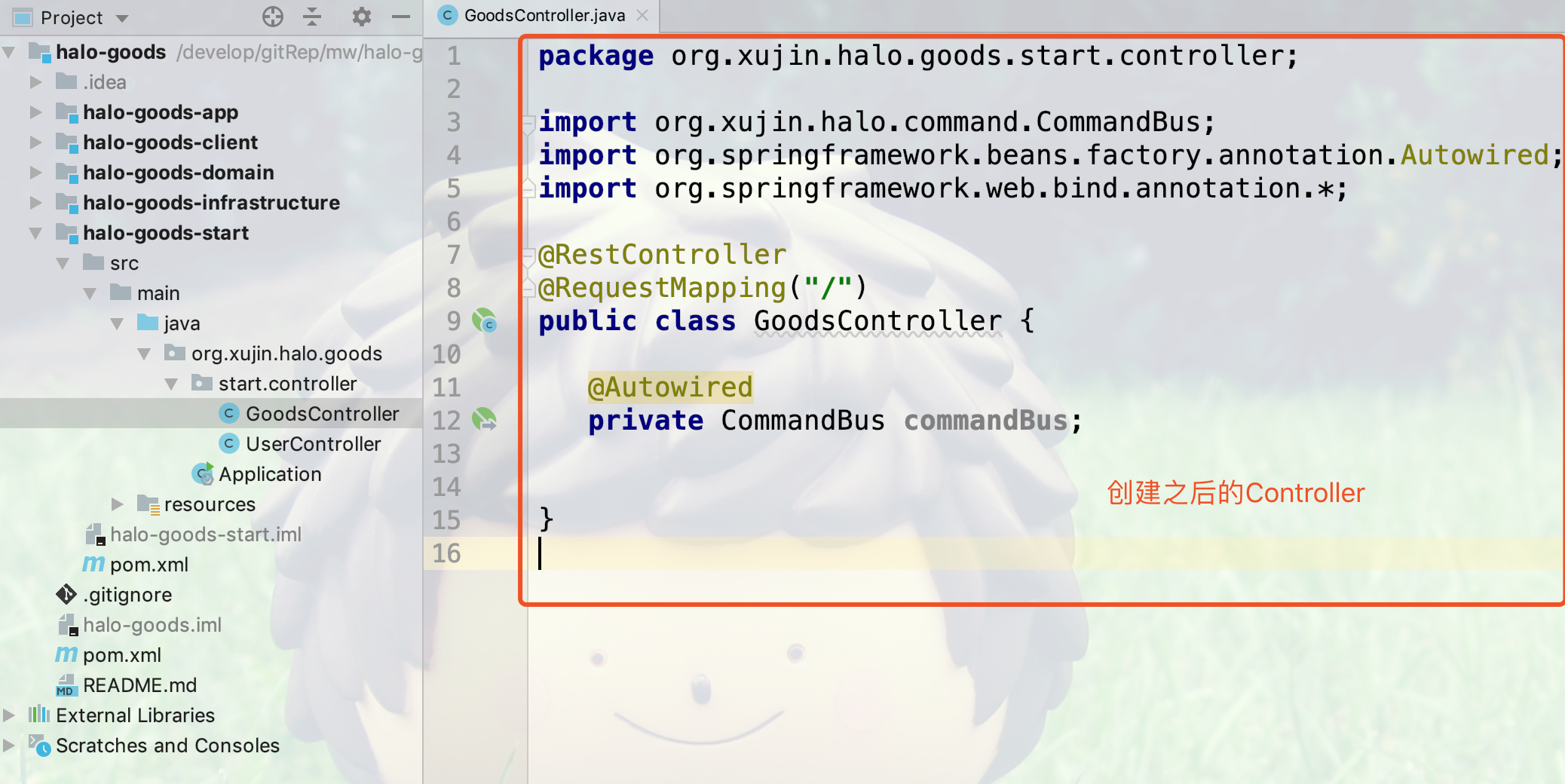
3.创建完之后的Controller代码如下所示:
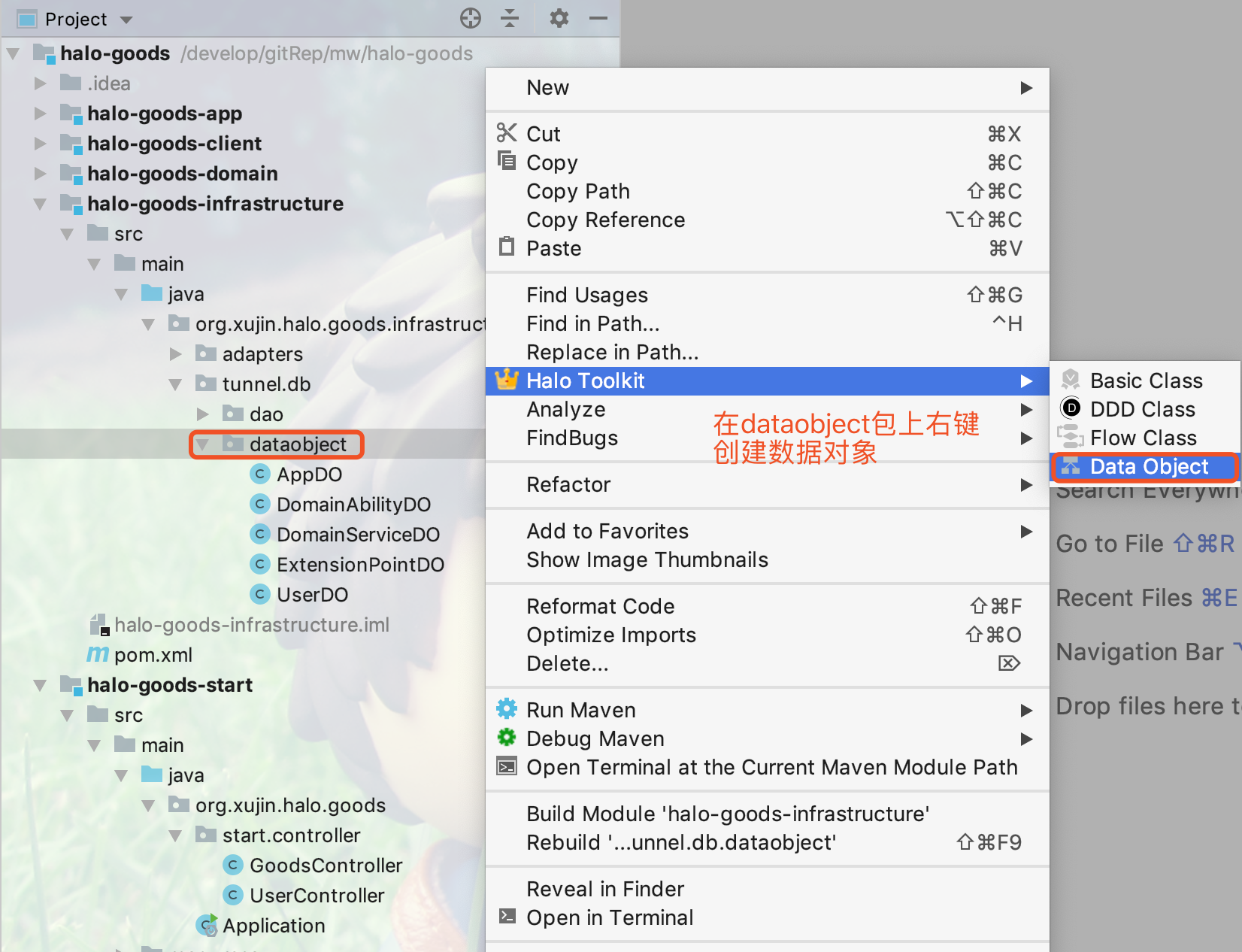
17.4.2. 创建Data Object(数据对象)
1.右键点击dataobject包,创建数据对象
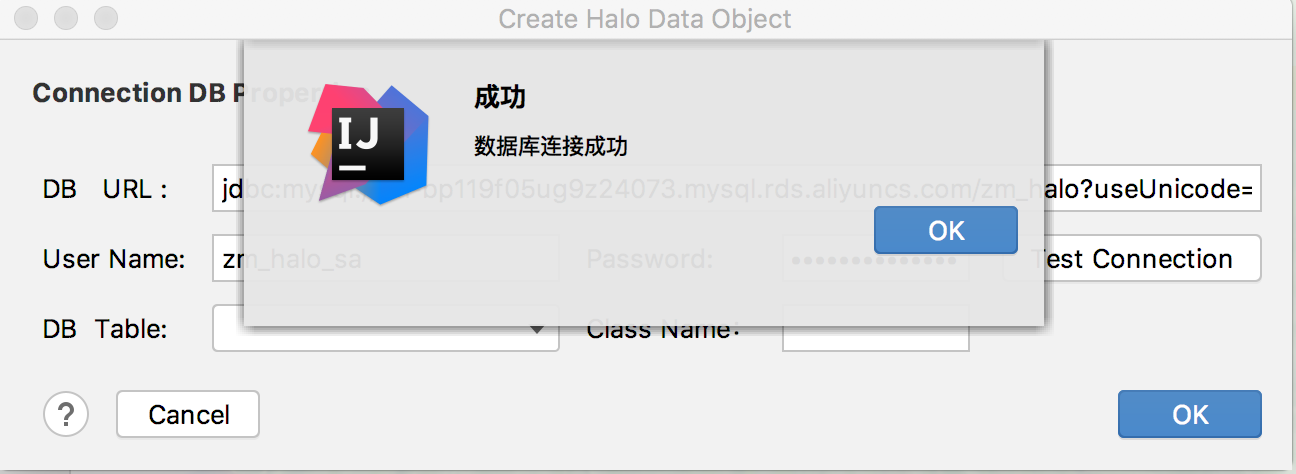
2.填写数据库连接信息,获取表信息
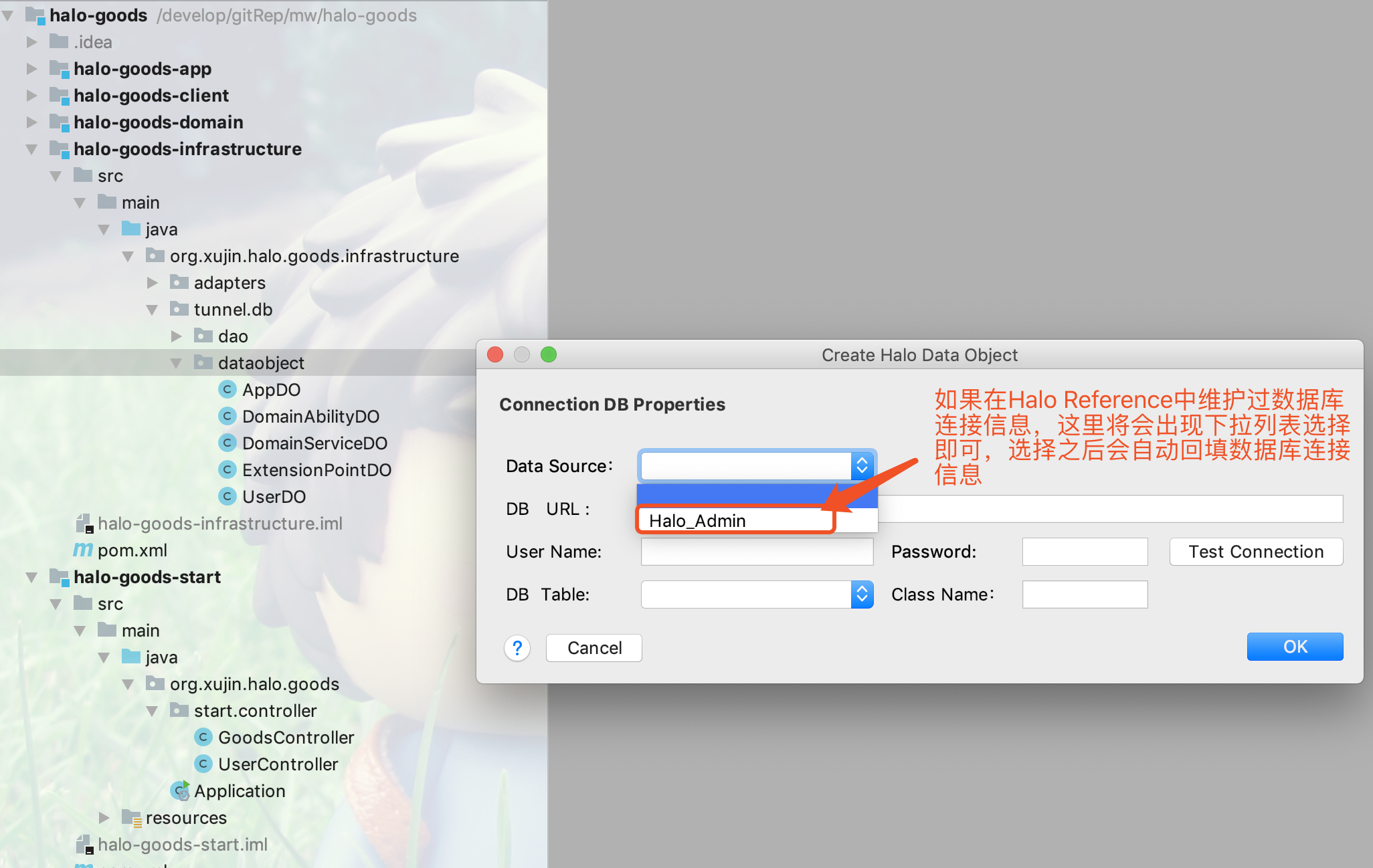
所填写的DB URL中需要包含数据库信息 |
3.连接数据库获取表成功,如下所示:
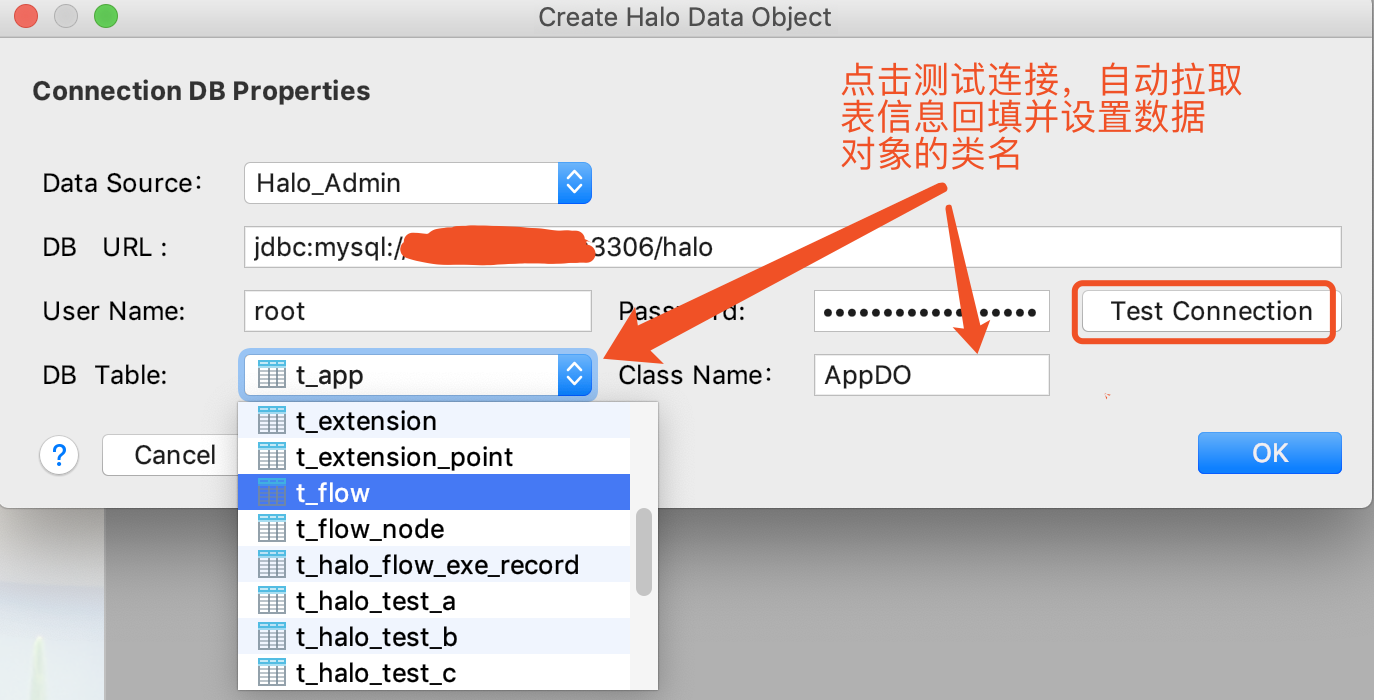
4.选择对应的表,自动转换设置Data Object的类名如下所示:
|
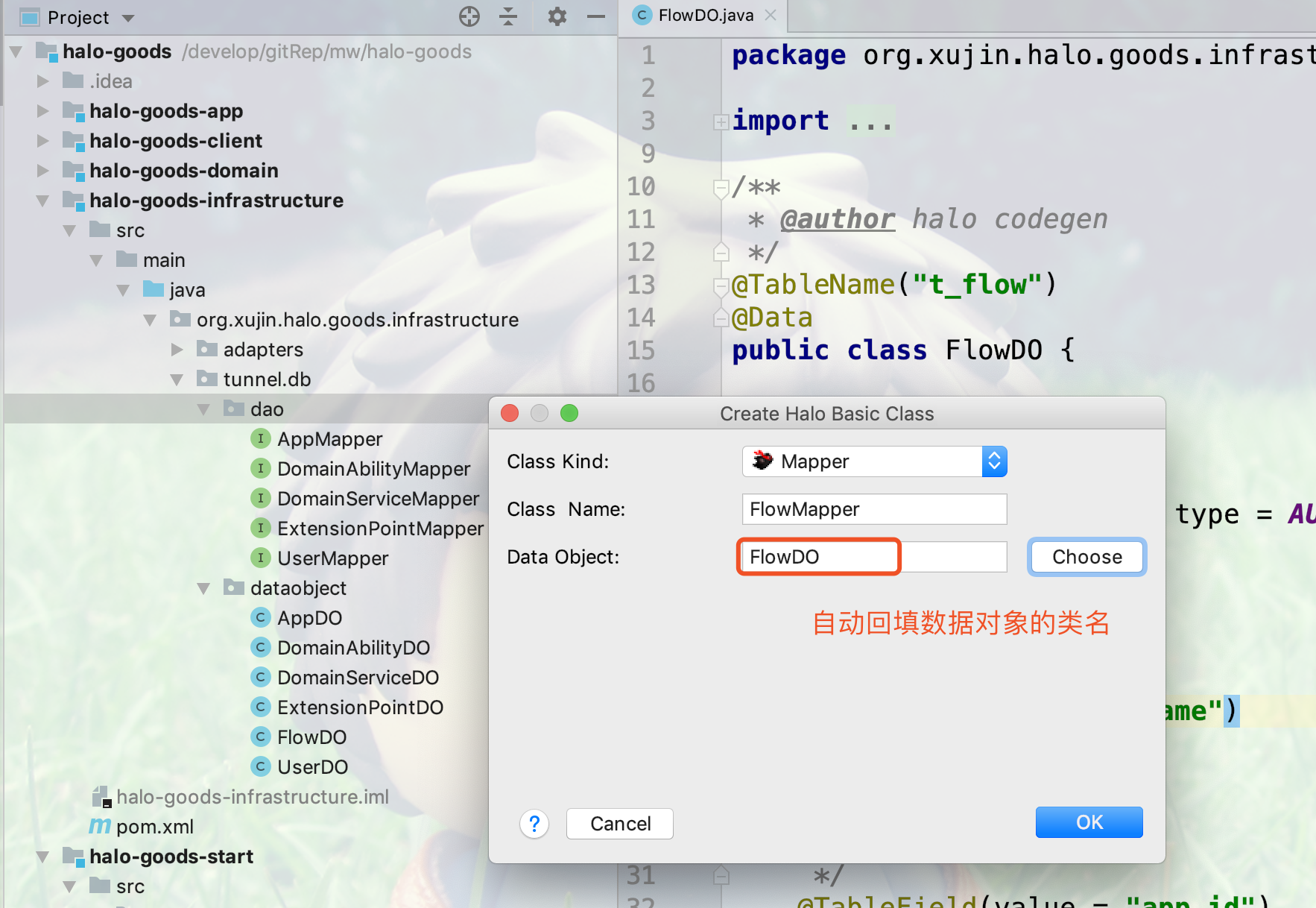
Data Object的类名必须以DO结尾,选择表之后,框架自动设置数据对象的类名。 |
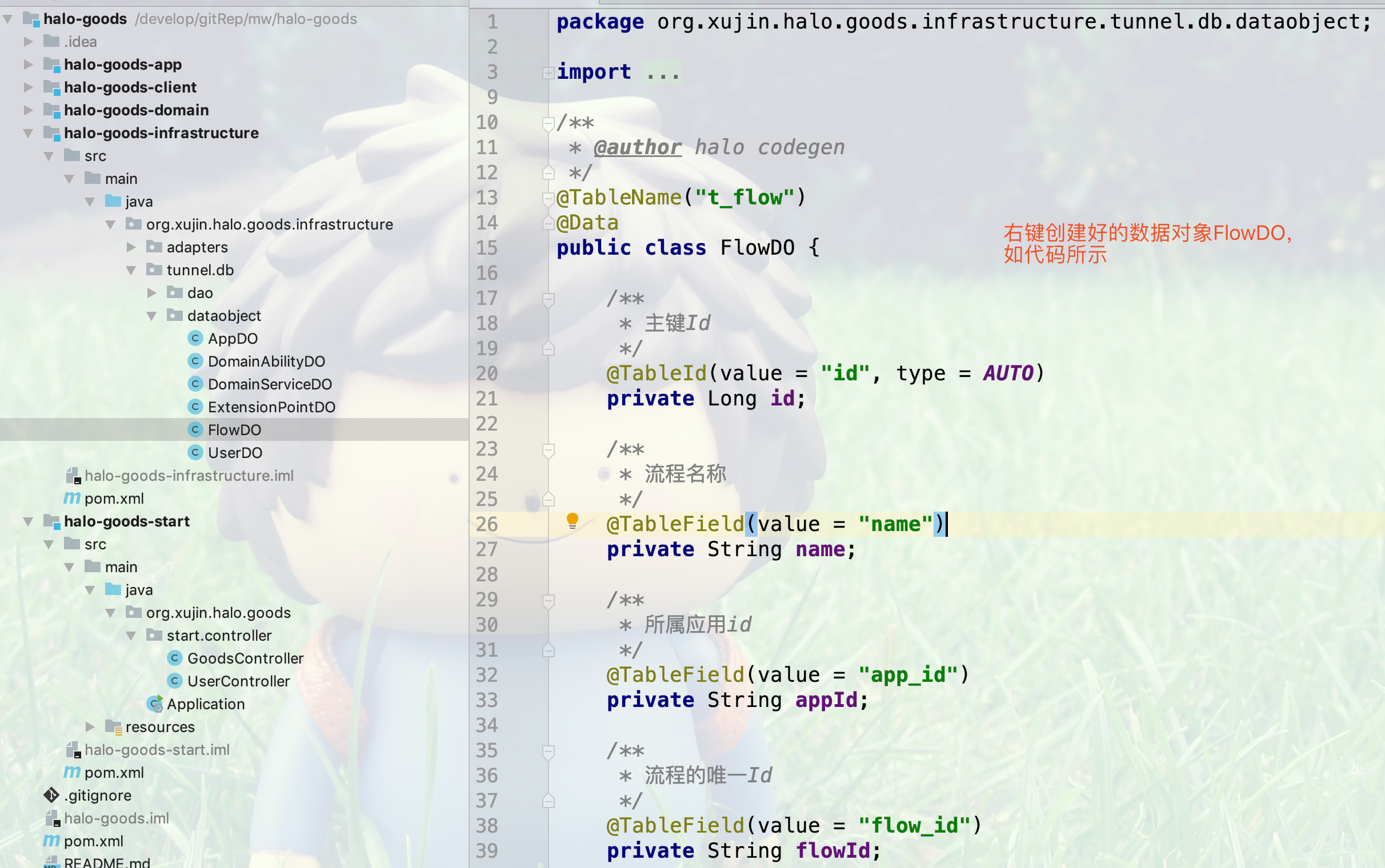
5.生成的Data Object的代码如下所示:
17.4.3. 创建Mapper
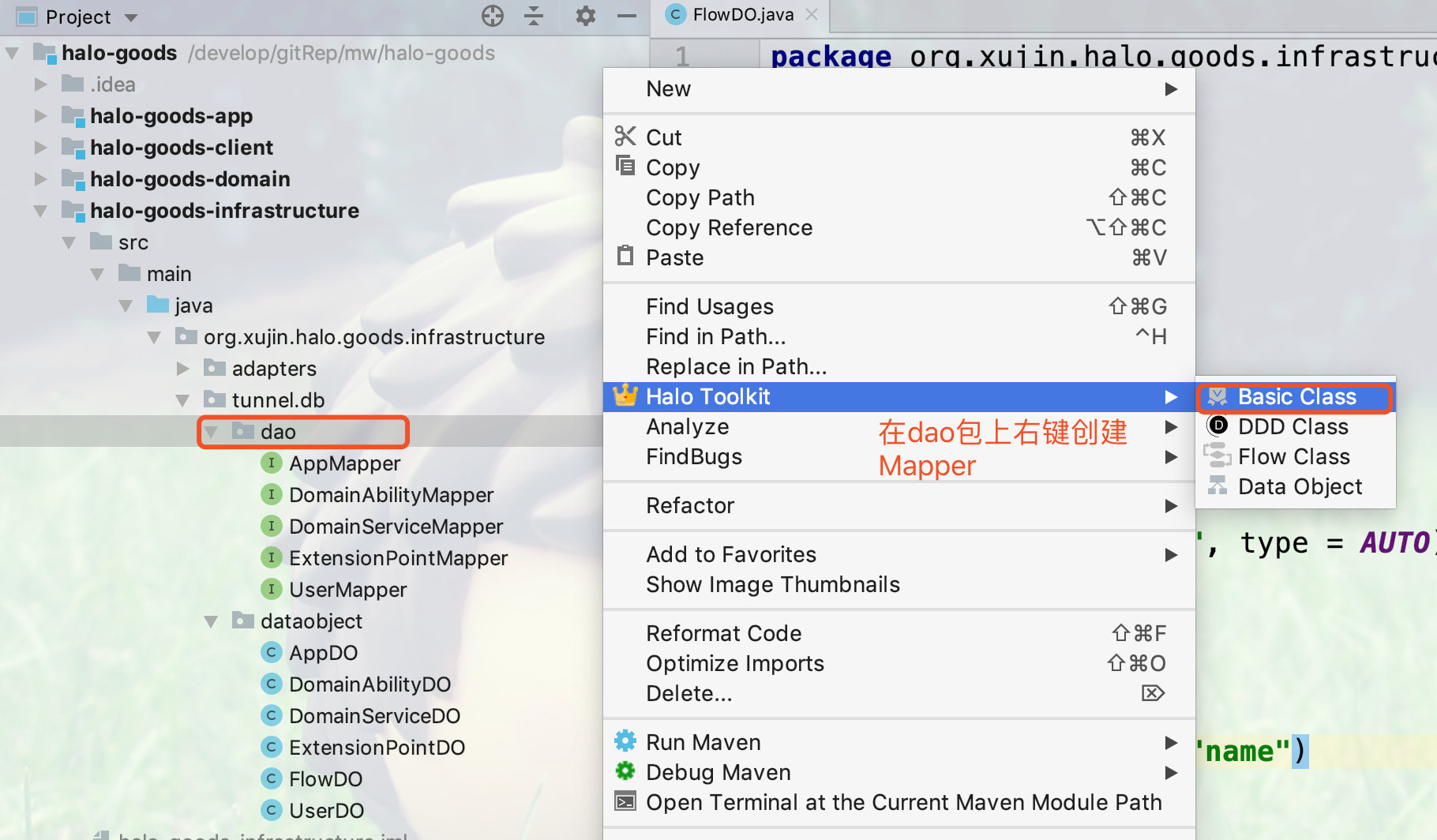
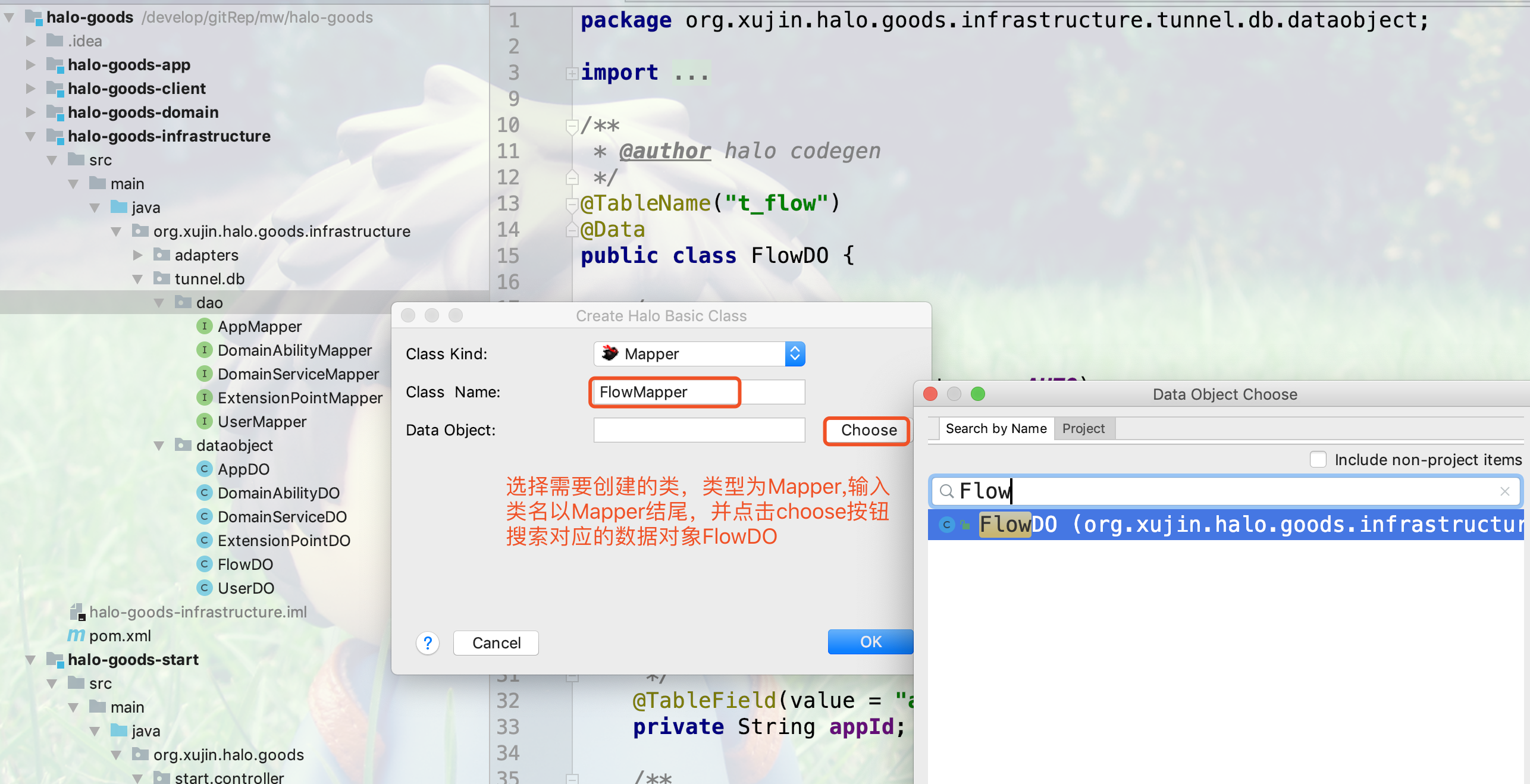
1.在基础设施层,右键点击dao包创建Mapper如下图所示:
2.输入Mapper对应的类名,选择对应的数据对象创建Mapper,如下图所示:
|
Mapper的类名必须用Mapper为后缀 |
3.选择数据对象之后,自动回填设置数据对象的名称
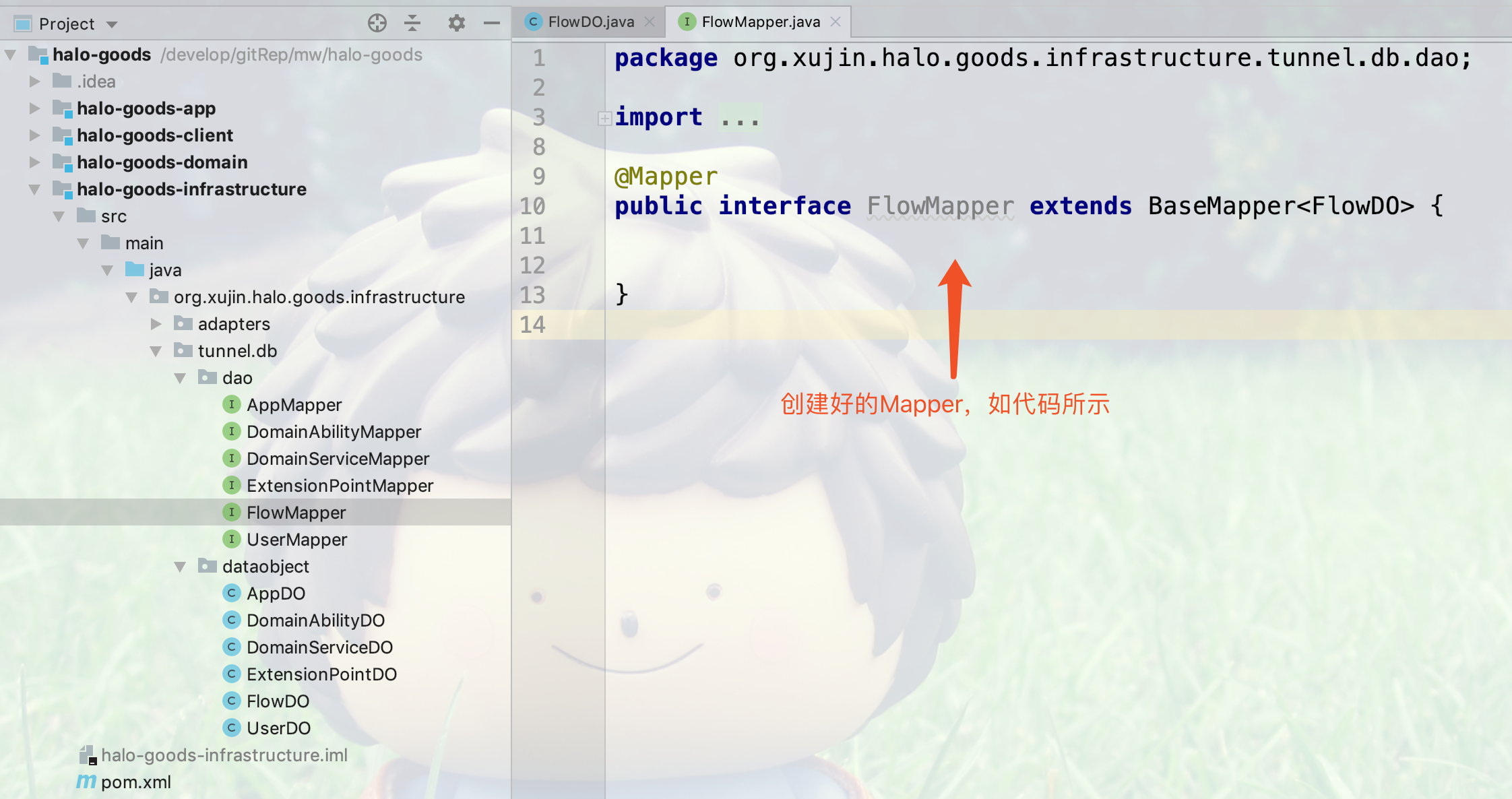
4.创建完的Mapper代码,如下图所示:
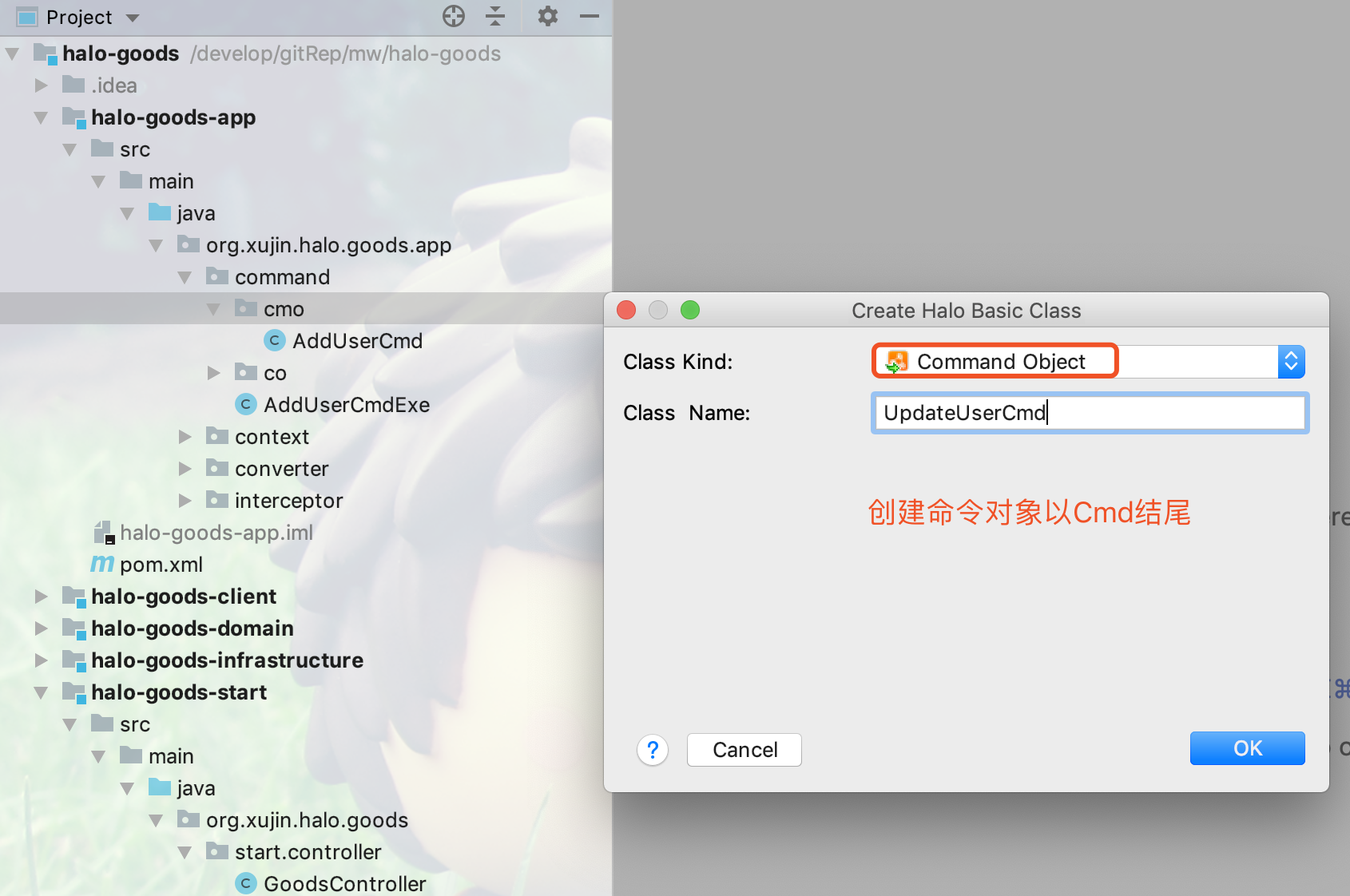
17.4.5. 创建(Command Handler)命令执行器
1.如下图所示,点击command包右键创建命令执行器
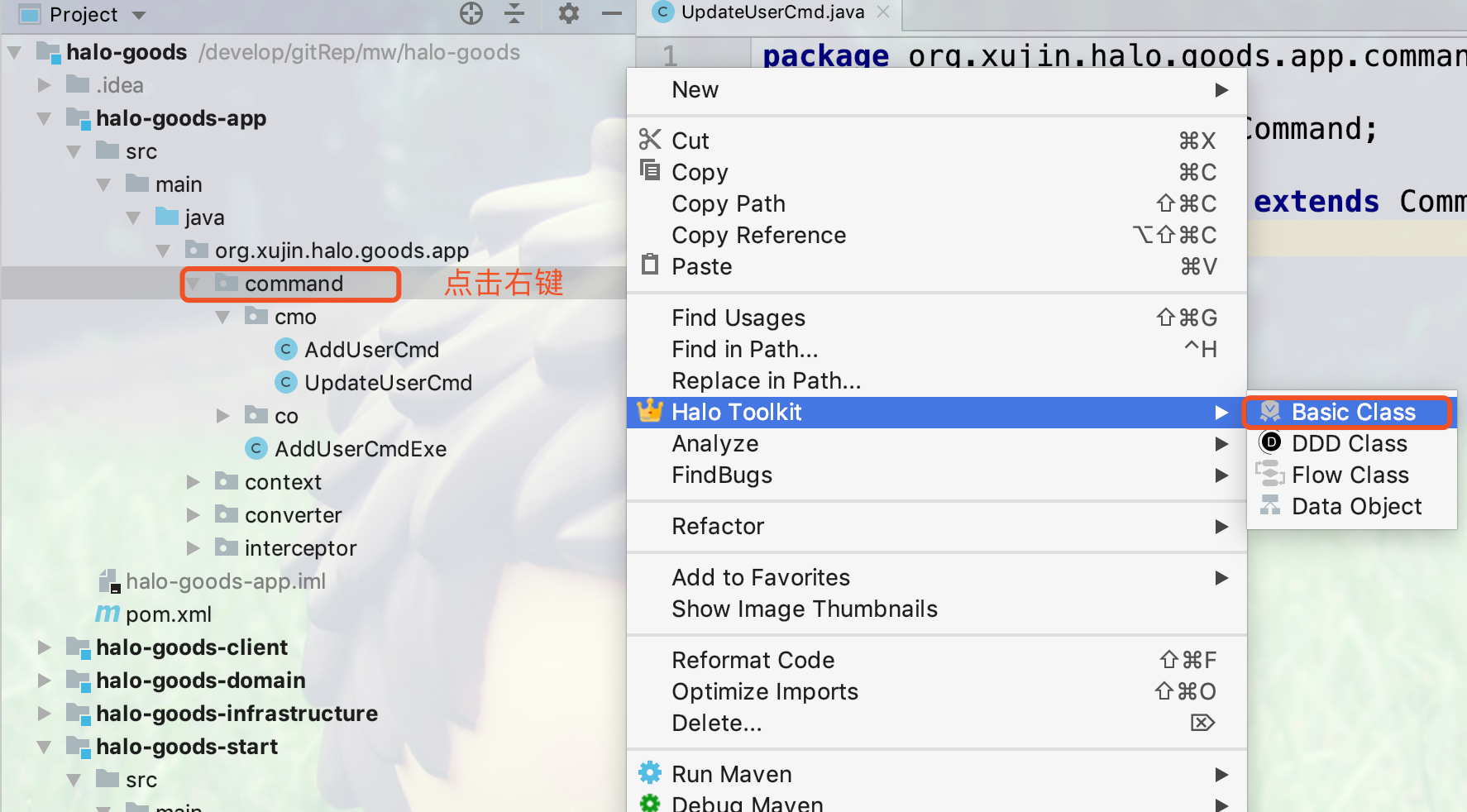
2.命令执行器以Exe结尾,选择命令对象,如下图所示:
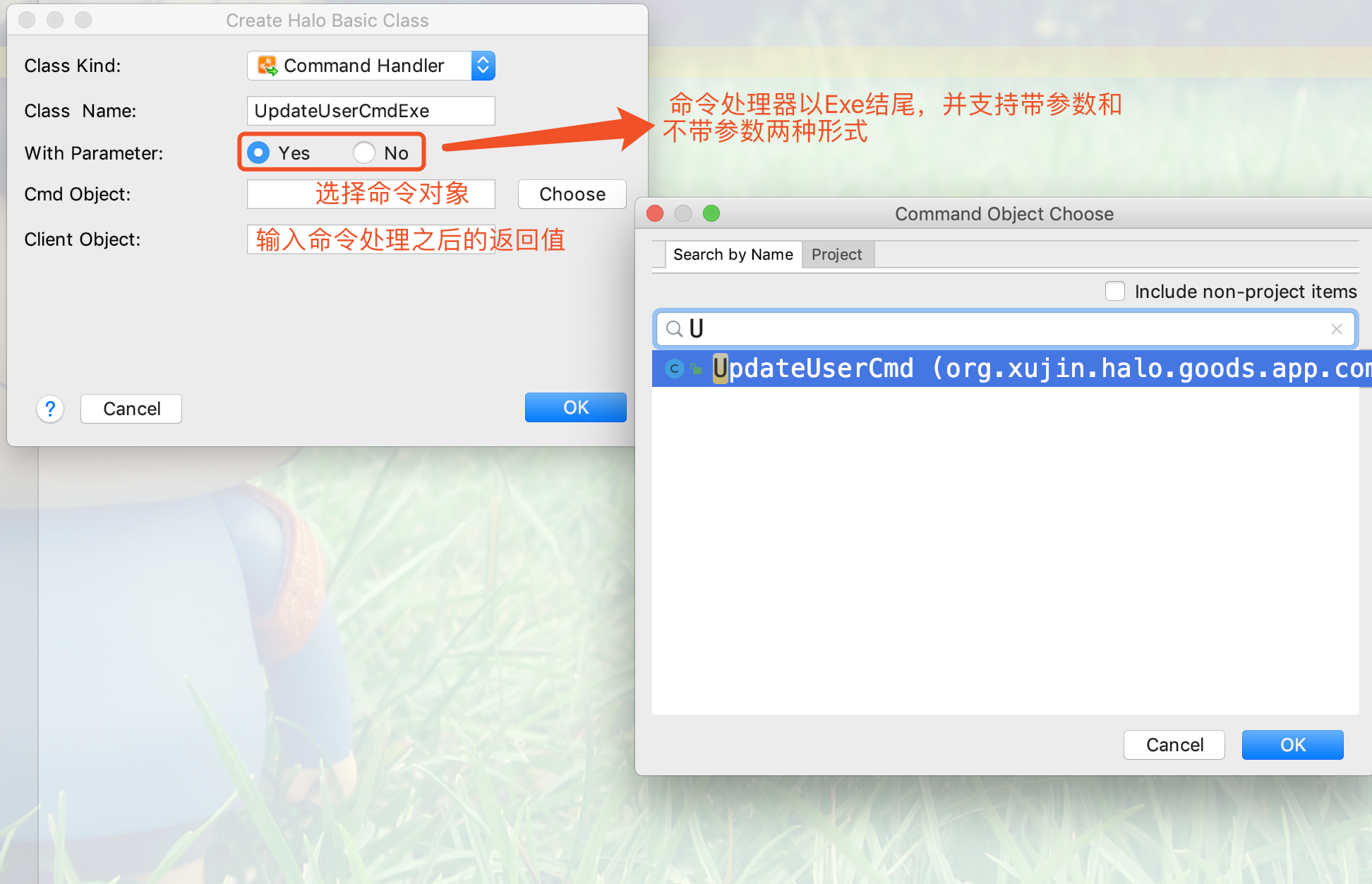
3.输入命令对象返回值的类型,可以是任意返回值的类型
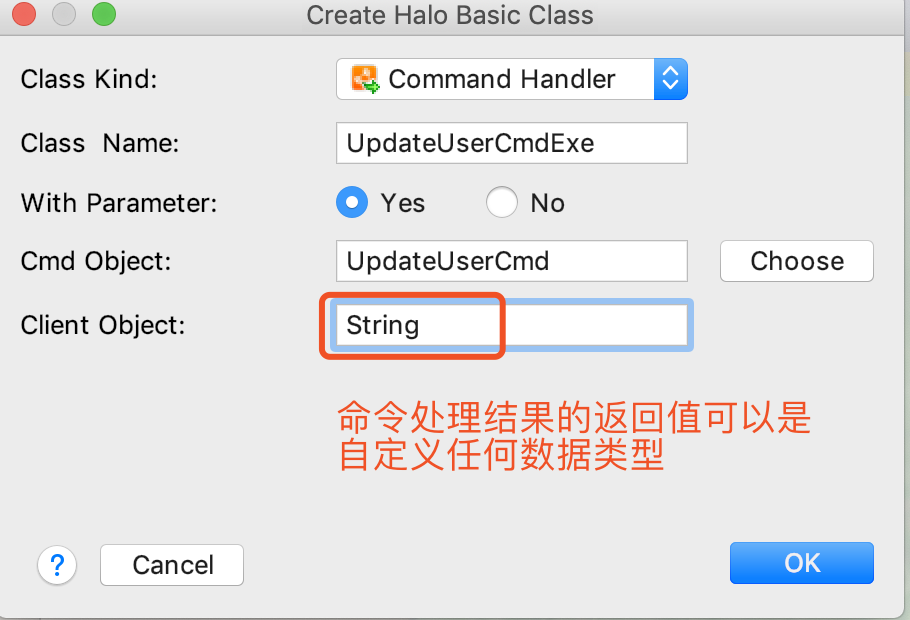
4.生成后的命令执行器代码如下所示:
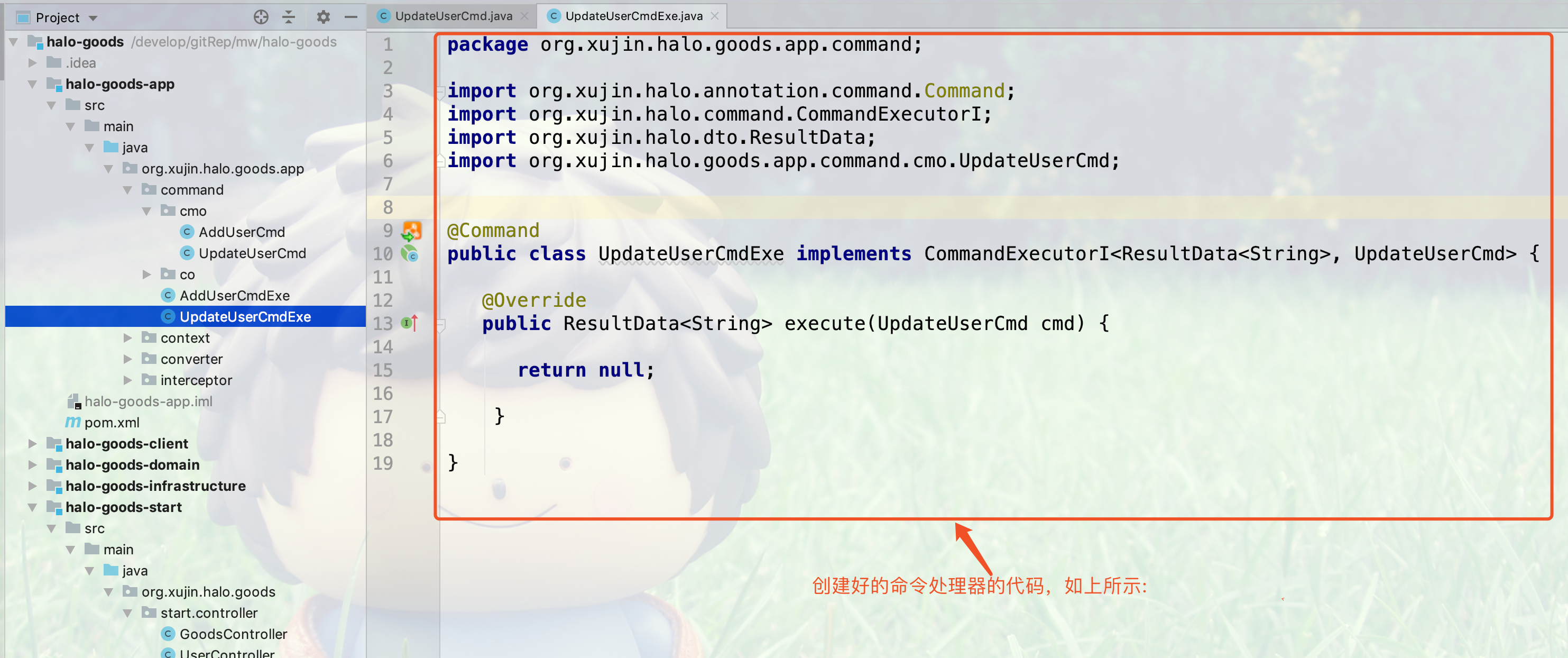
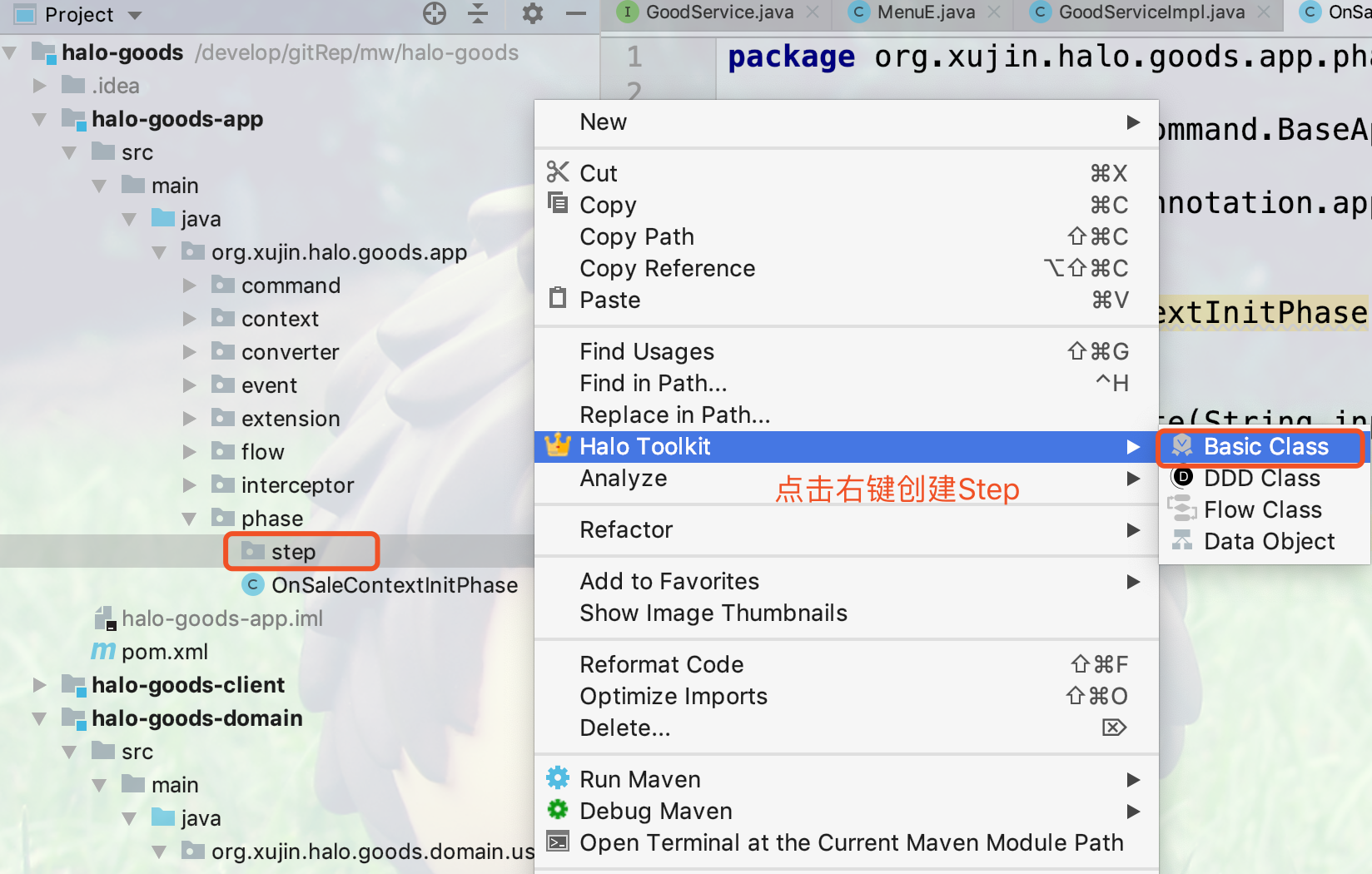
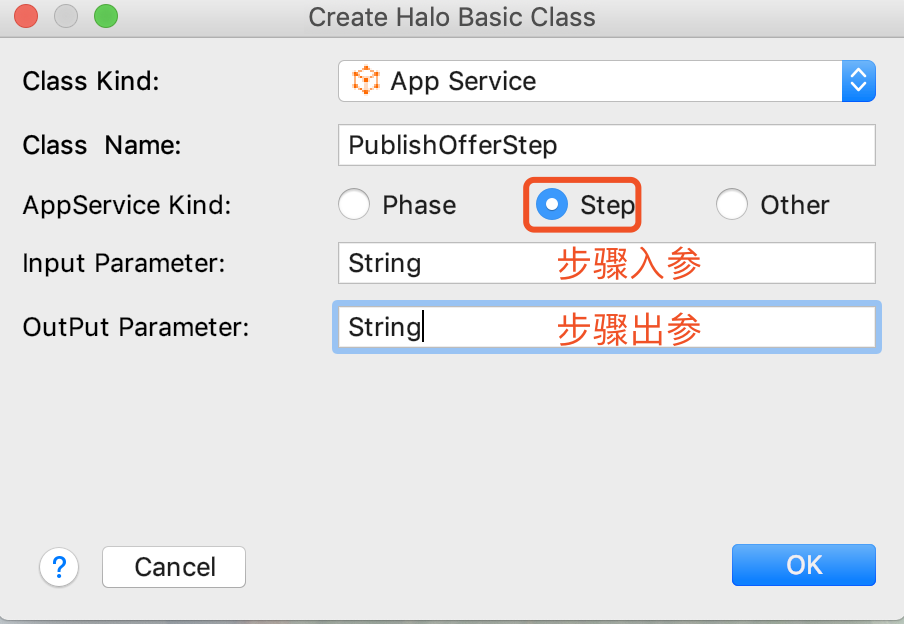
17.4.8. 创建应用服务
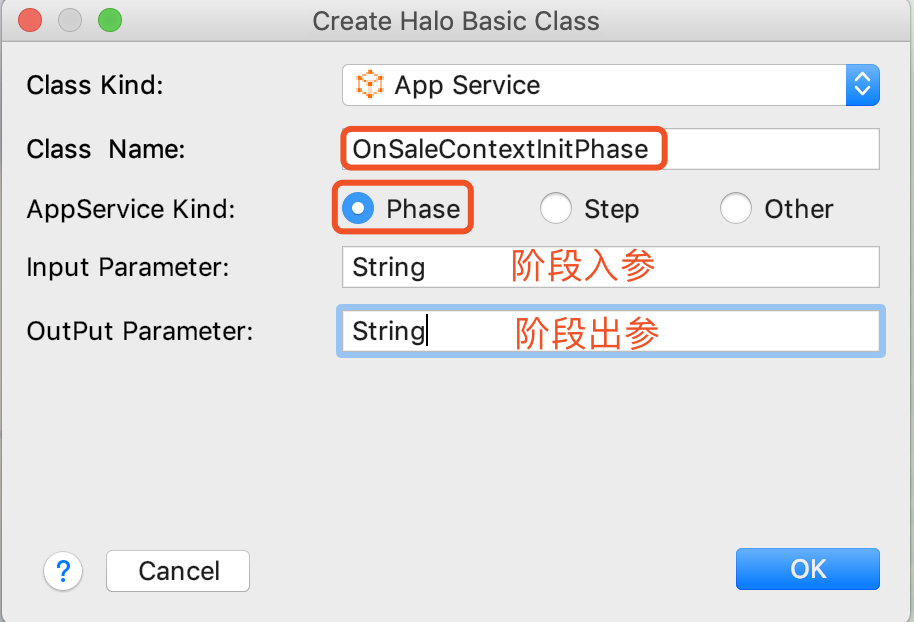
1.如下图所示,点击appservice包右键应用服务
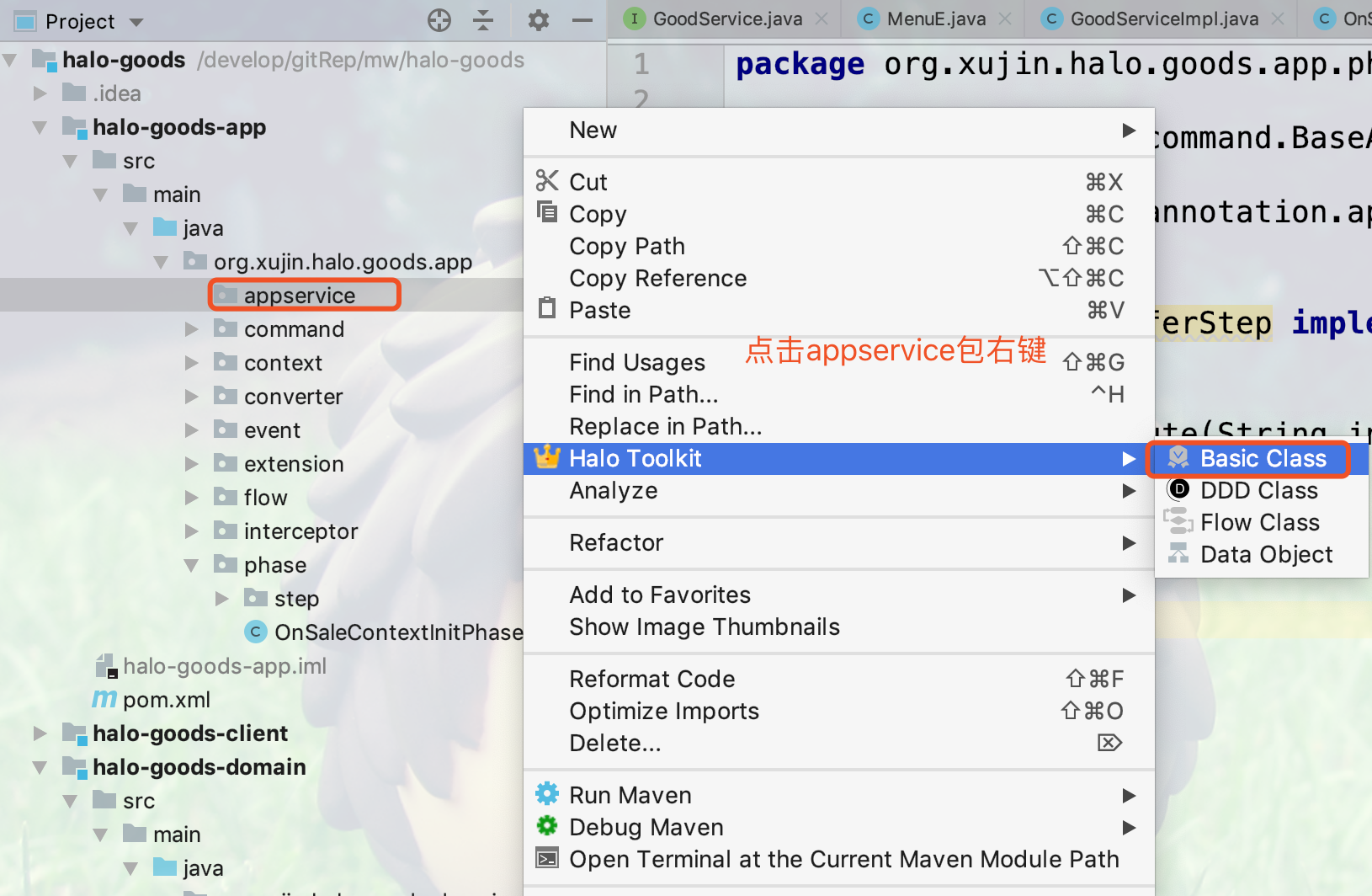
2.应用服务以AS结尾,如下图所示:
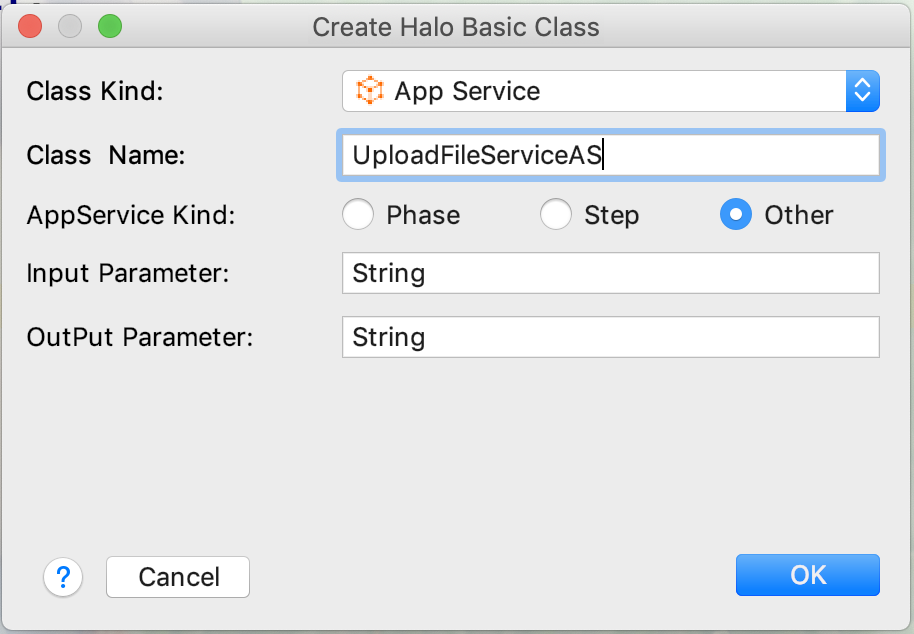
| 应用服务的入参和出参,可以是任意类型. |
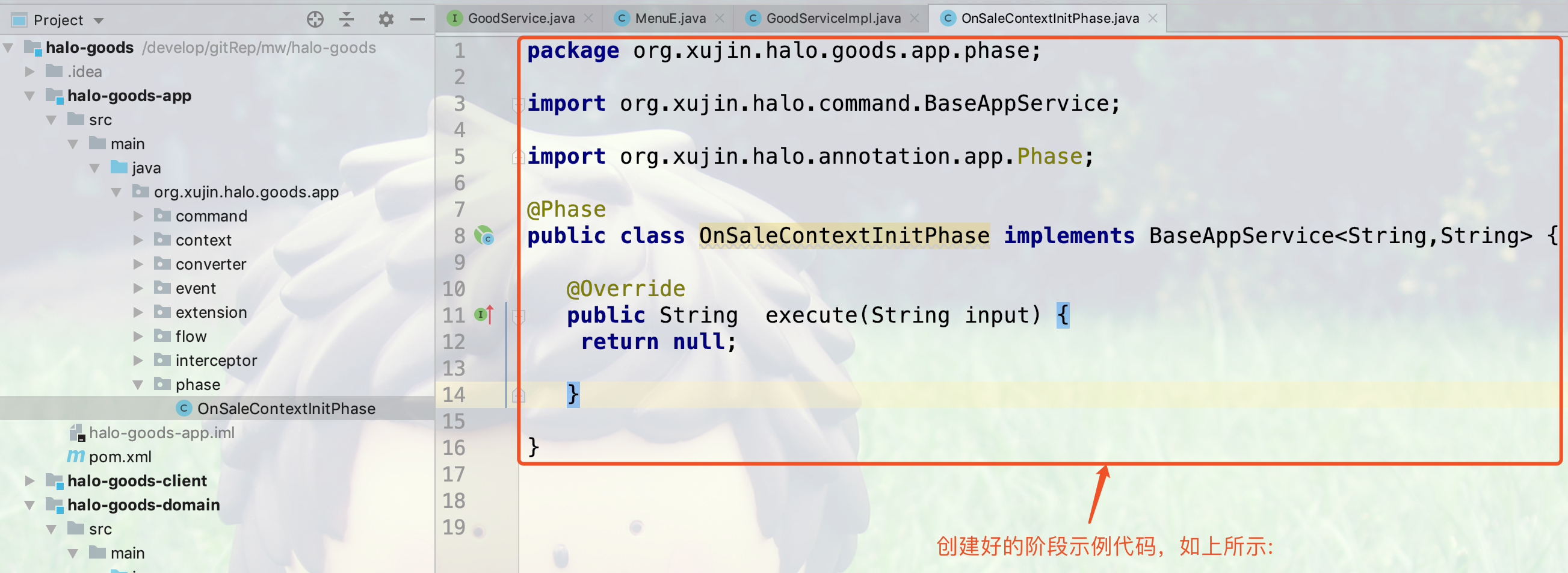
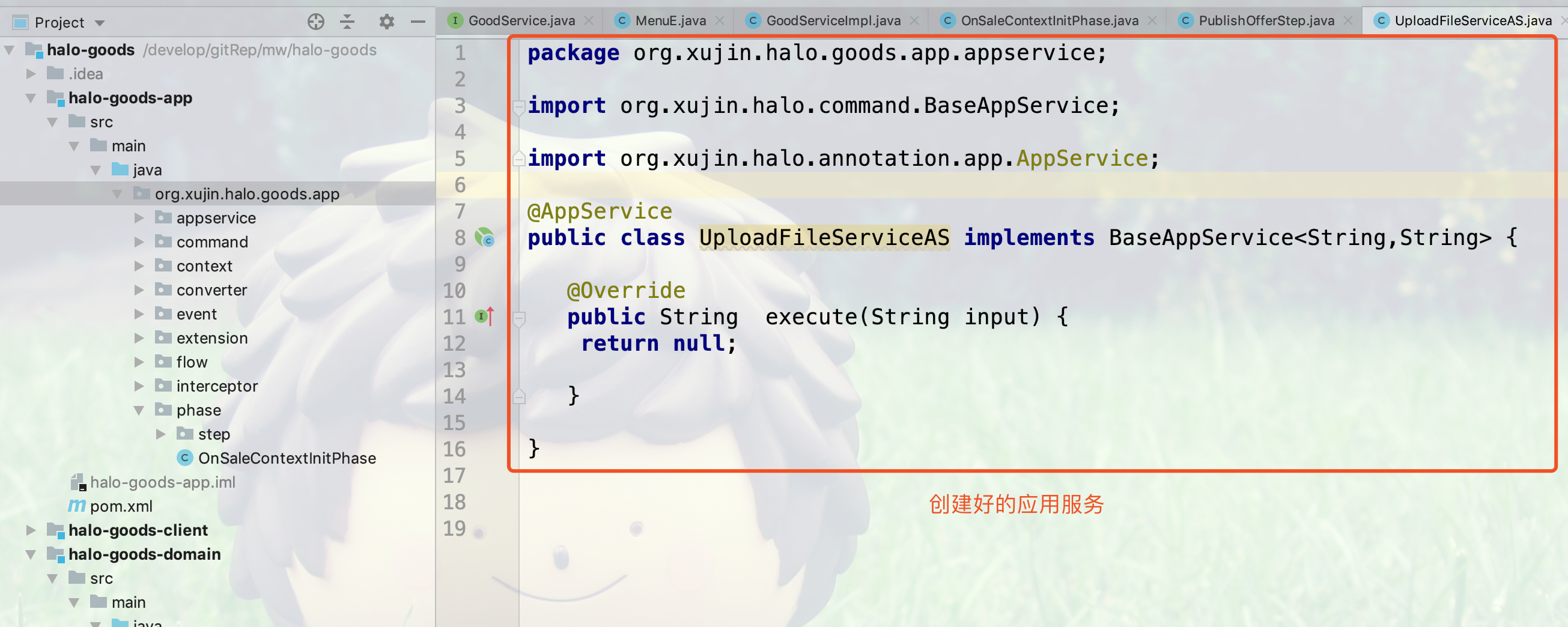
3.创建好的示例应用服务代码,如下图所示:
17.4.9. 创建Flow流程定义
1.点击flow包右键创建流程定义,如下图所示:
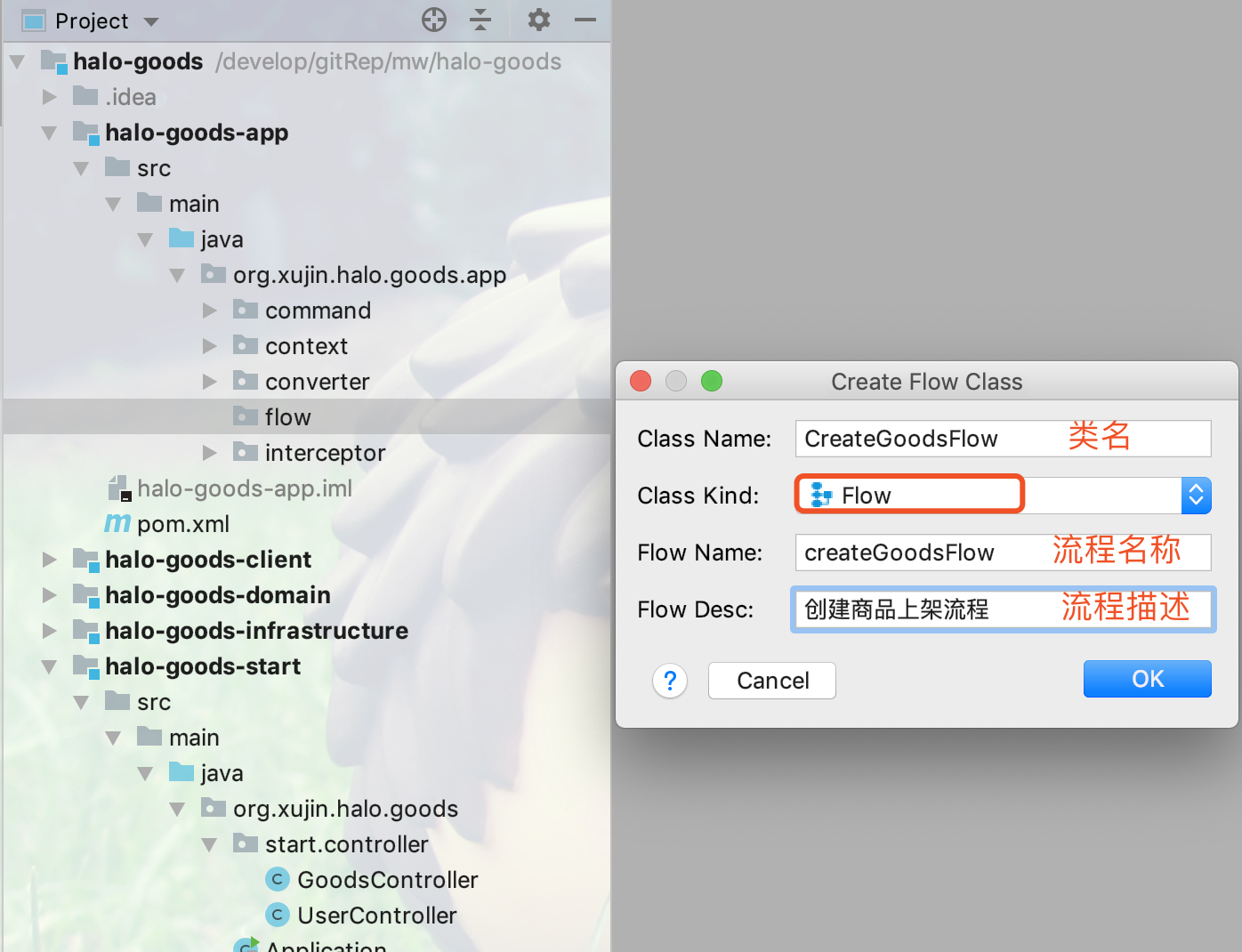
2.输入流程定义的的类名,流程名称和流程描述,如下图所示:
3.创建流程定义的示例代码,如下所示,需要根据实际情况修改
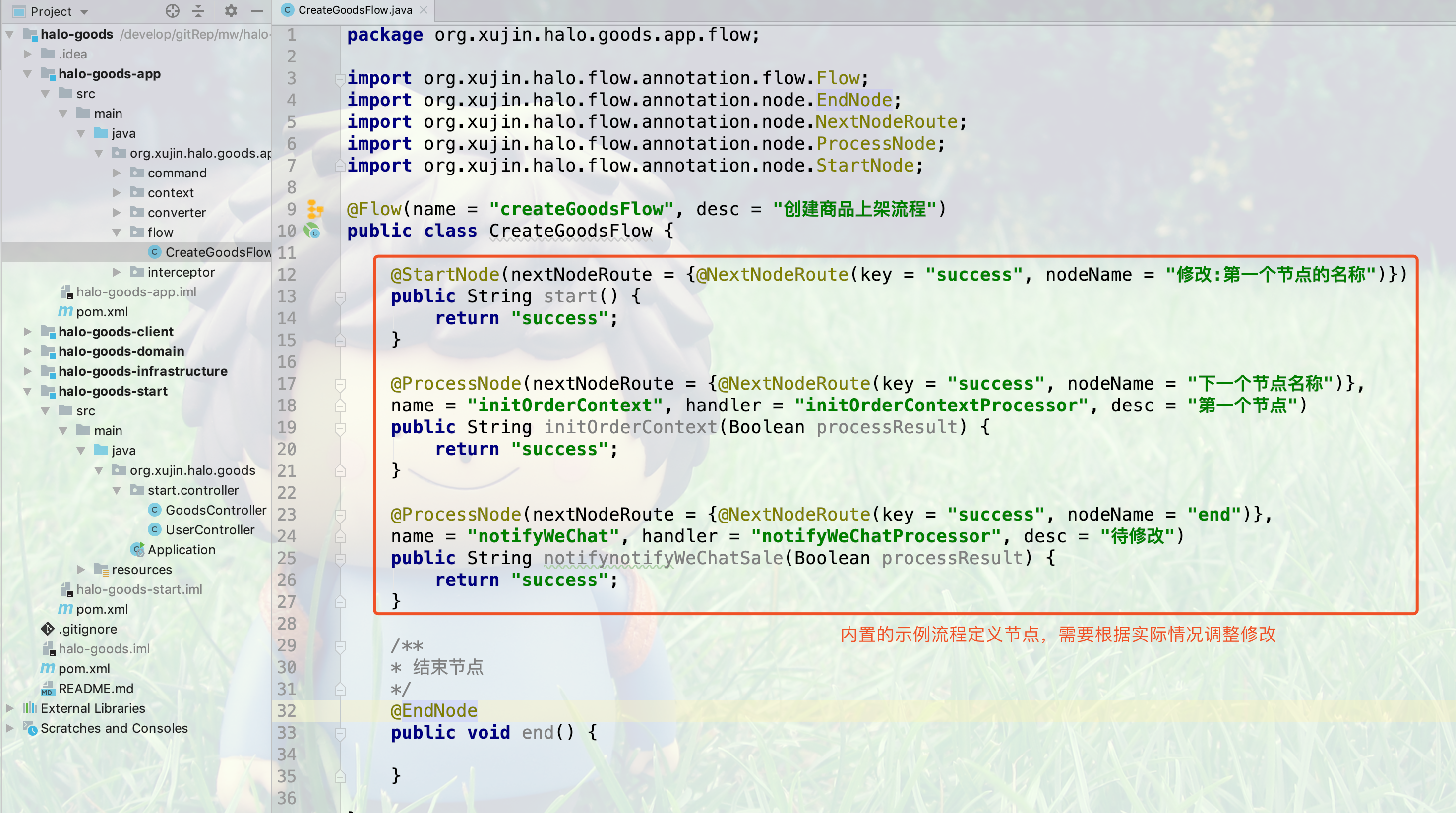
17.4.10. 创建节点执行器
1.点击processor包右键创建流程节点执行器,如下图所示:
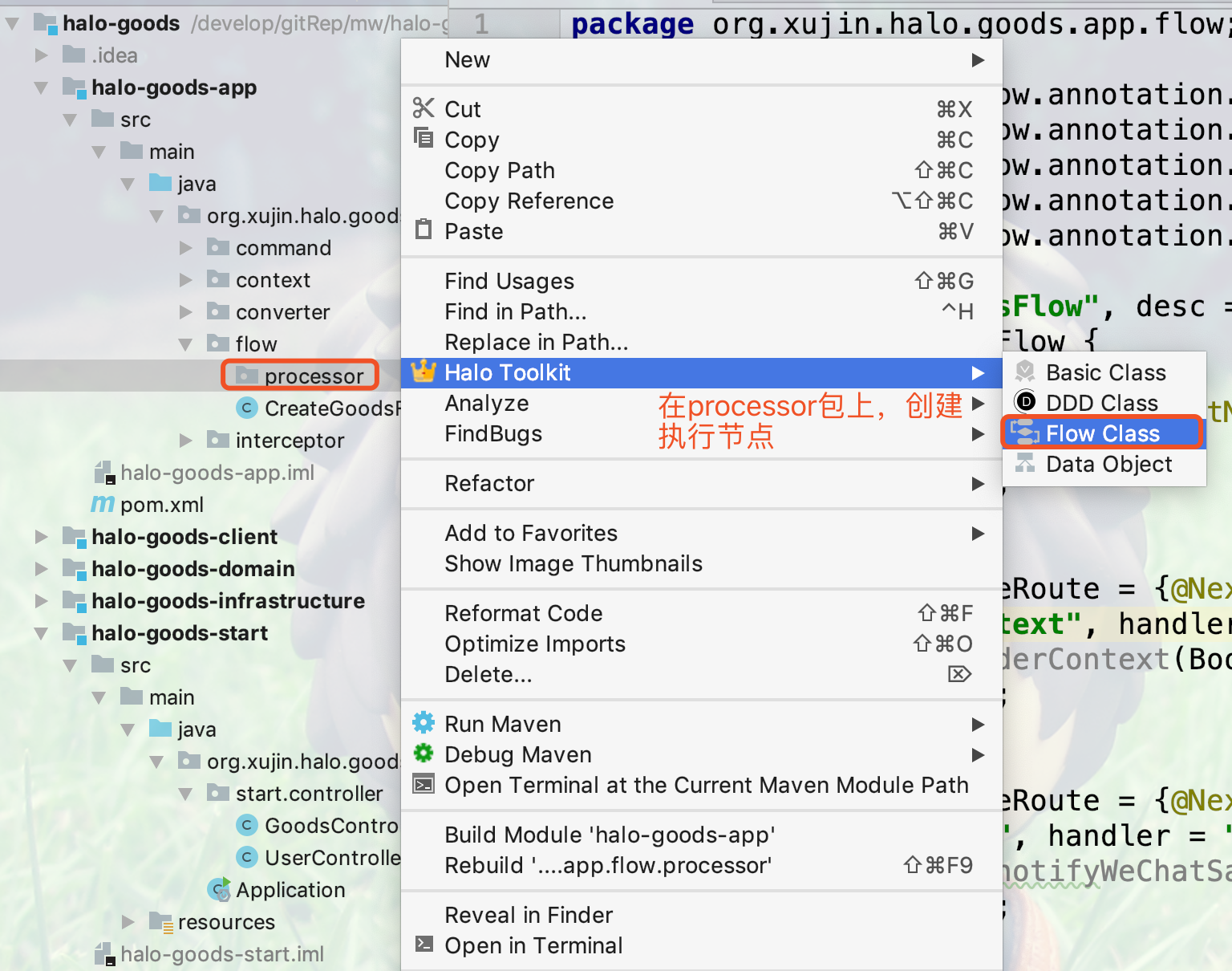
2.填写节点执行器的类名,如下图所示:
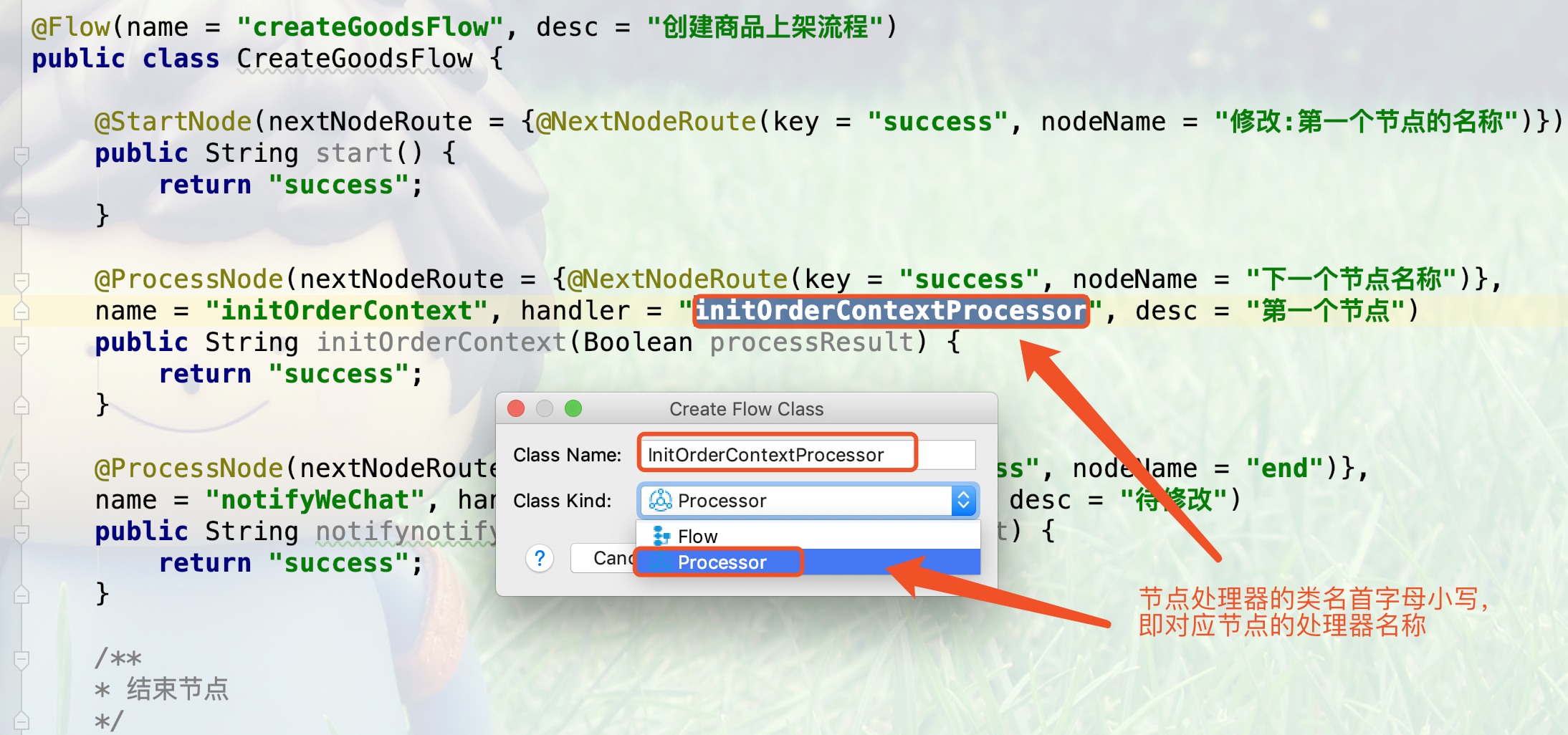
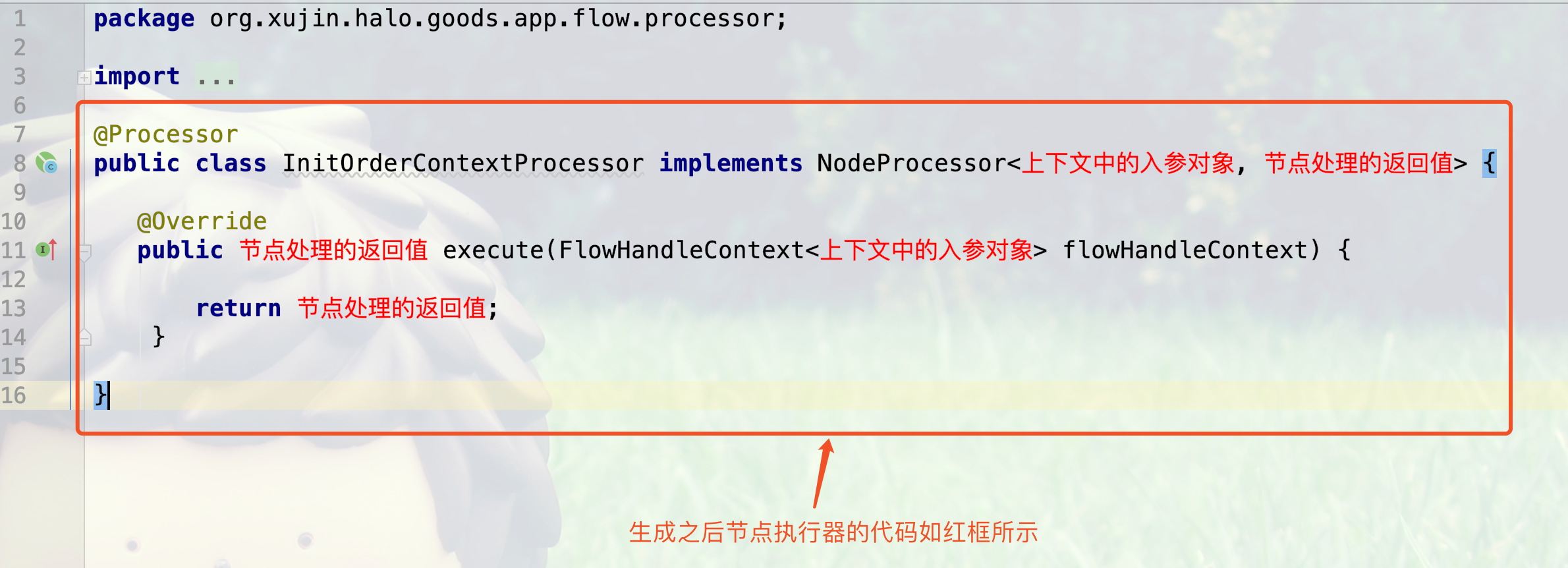
3.生成后的节点执行器的代码如下所示,需要根据实际情况修改,如下图所示:
17.4.11. 创建Extension Point(扩展点)
1.新建extension或者extensionpoint包,创建扩展点,如下图所示:
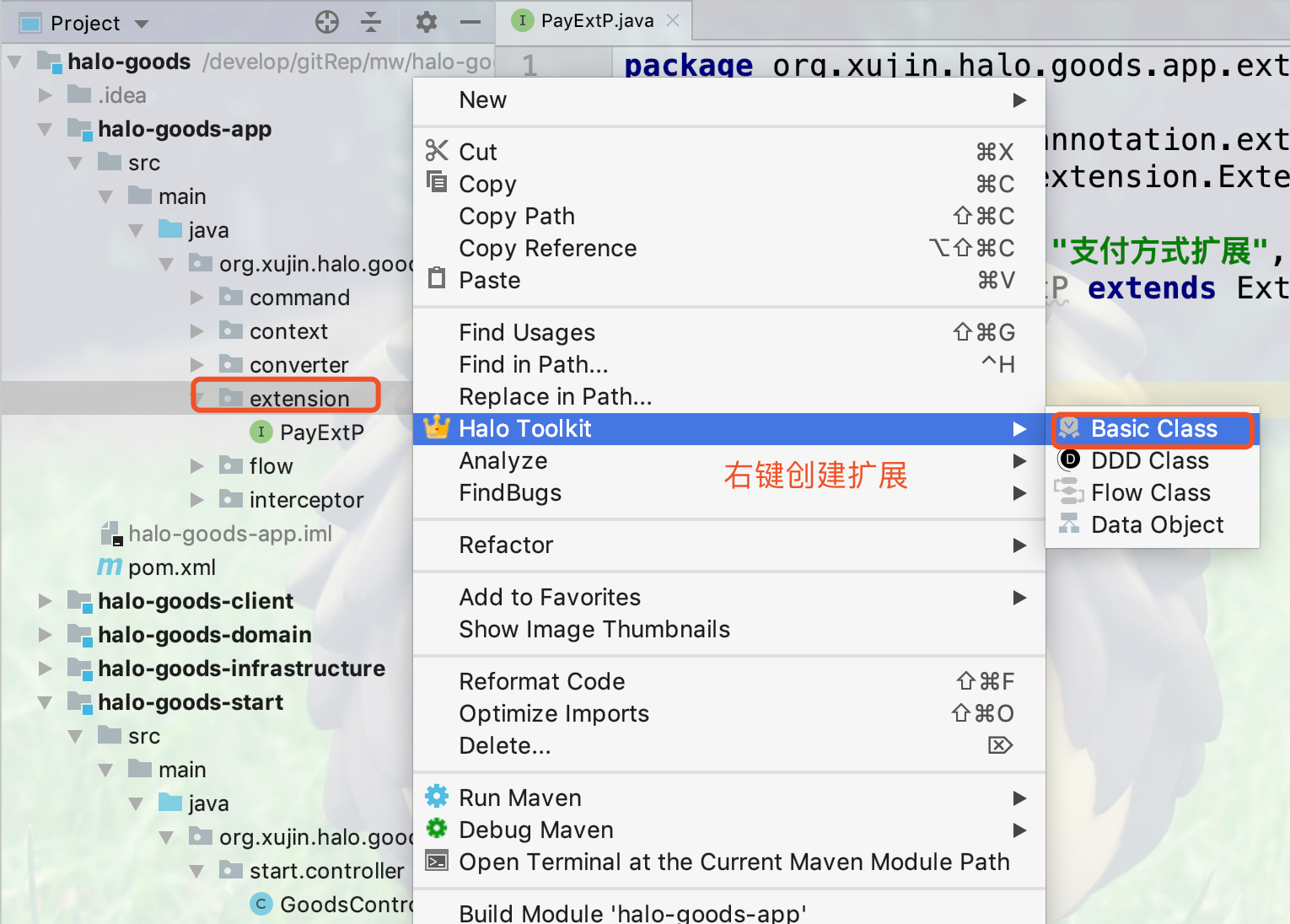
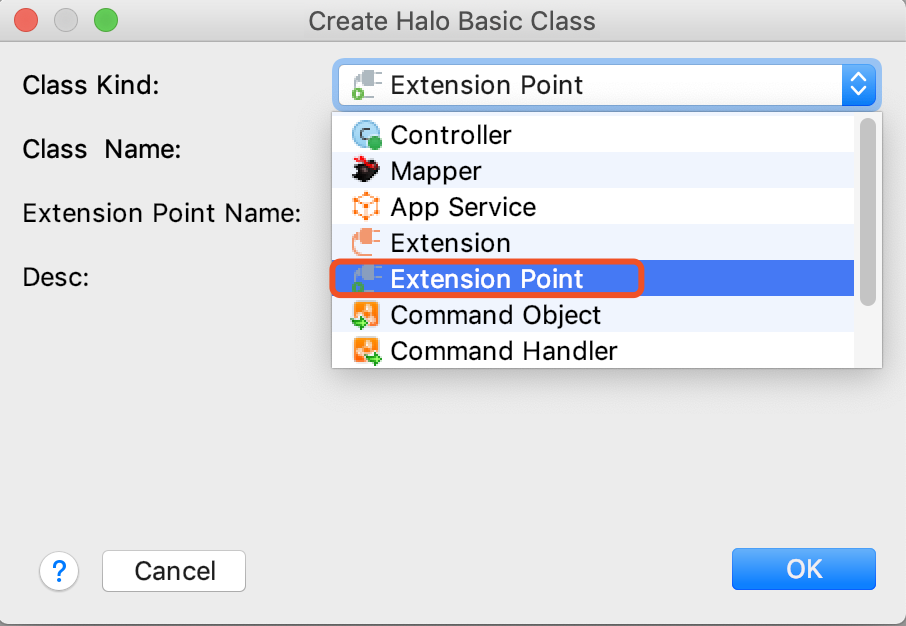
2.选择Class Kind为Extension Point开始创建扩展点
|
扩展点的类名必须用ExtP为后缀,否则会出现约束提示信息。 |
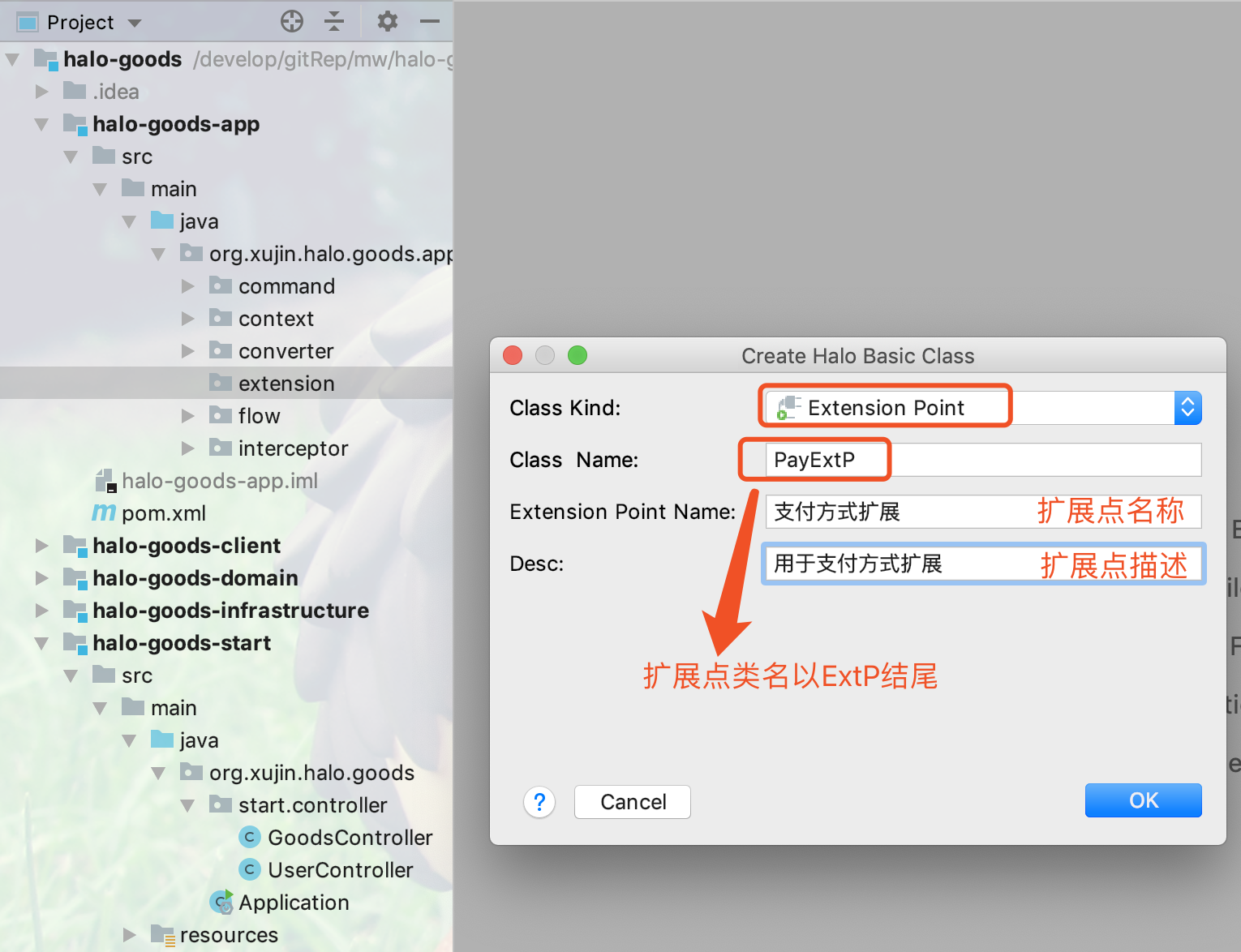
3.输入扩展点名称和扩展点描述,如下图所示:
-
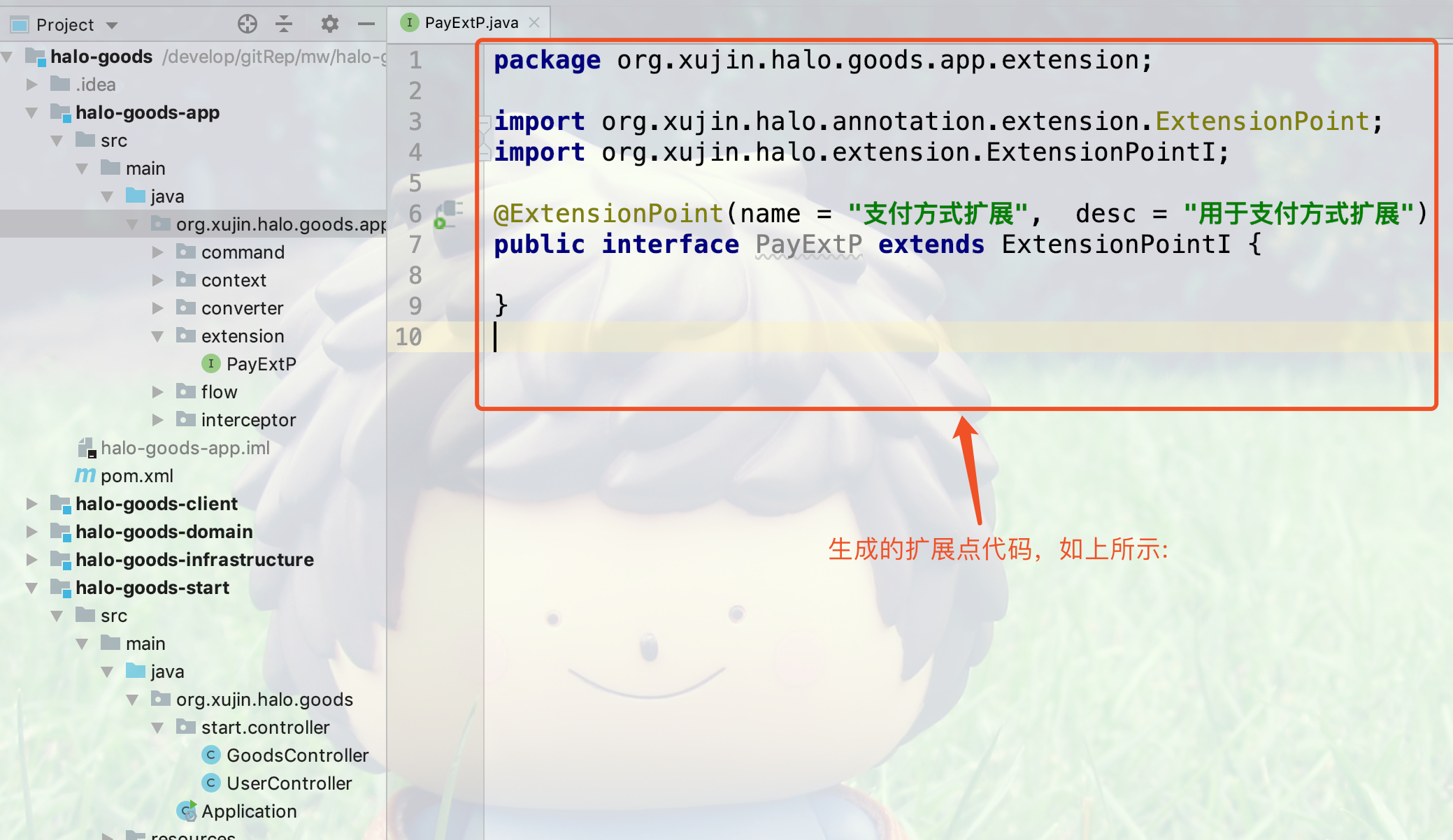
创建完的扩展点代码如下所示:
17.4.12. 创建Extension(扩展)
1.在extension包下面,创建扩展,如下图所示:
2.输入类名,选择Class Kind为Extension,如下图所示:
|
扩展的类名必须用Ext为后缀,否则会出现约束提示信息。 |
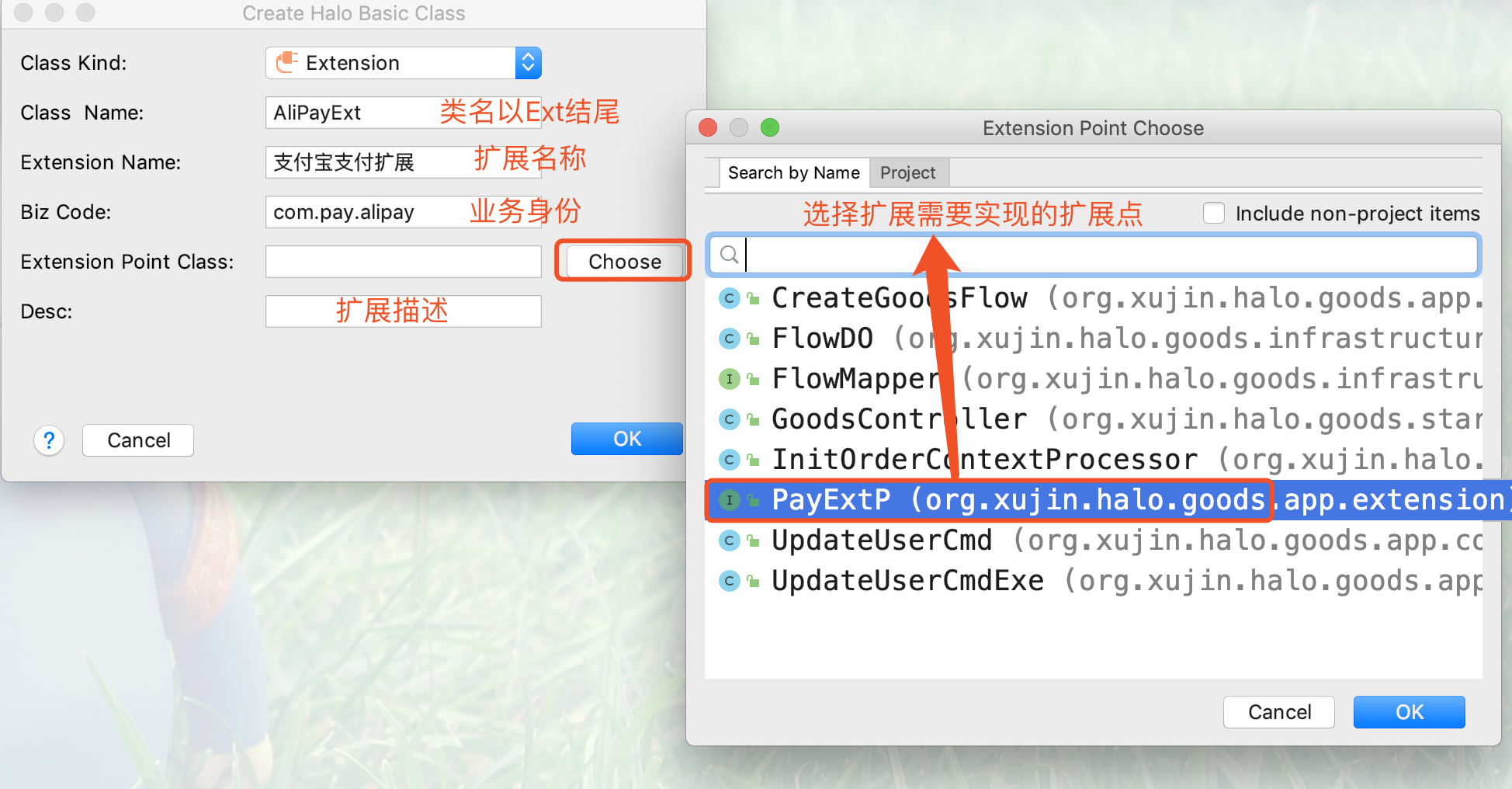
3.输入扩展名称,和业务身份,并选择扩展点,如下图所示:
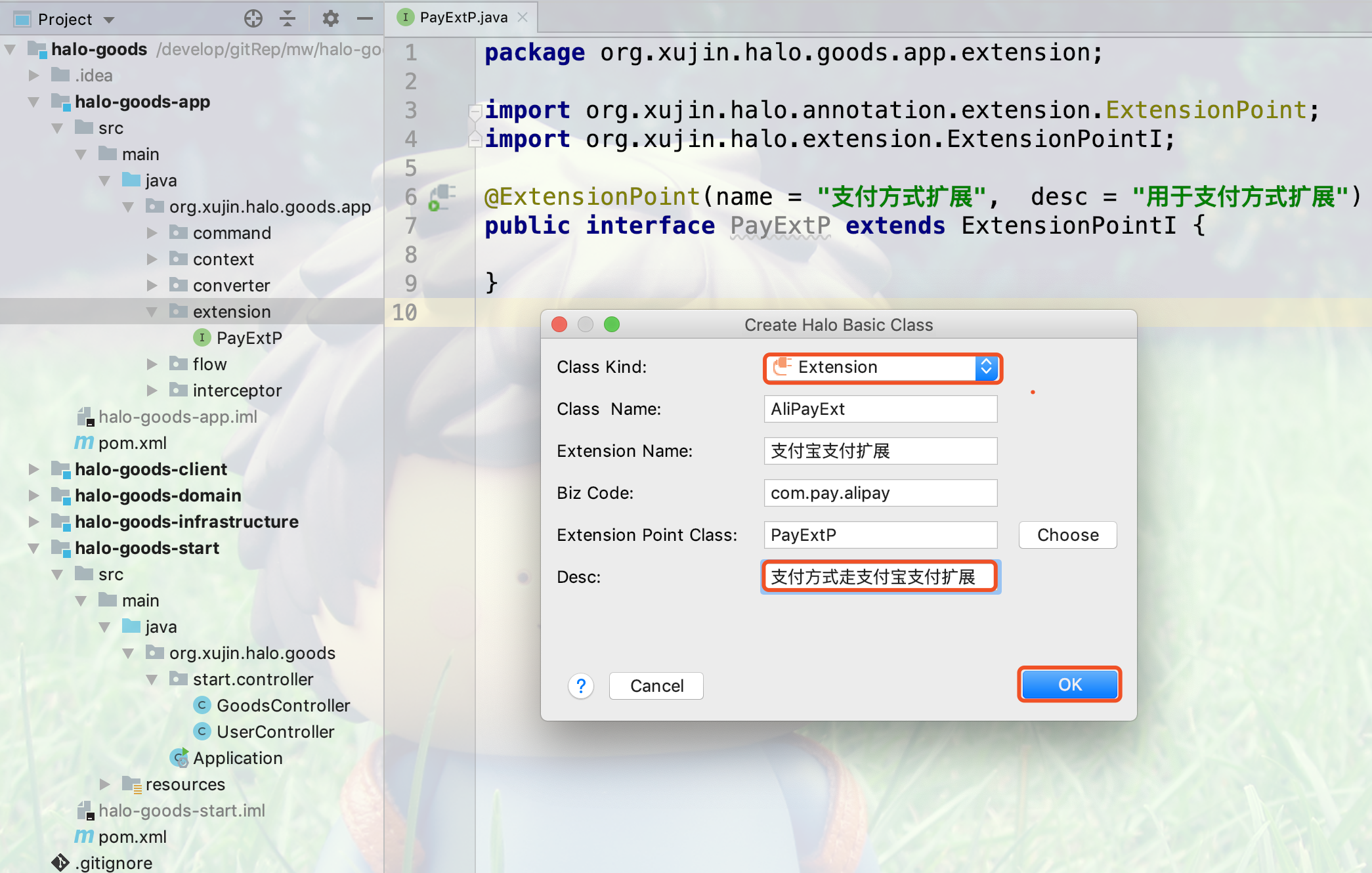
4.输入扩展点描述,如下所示:
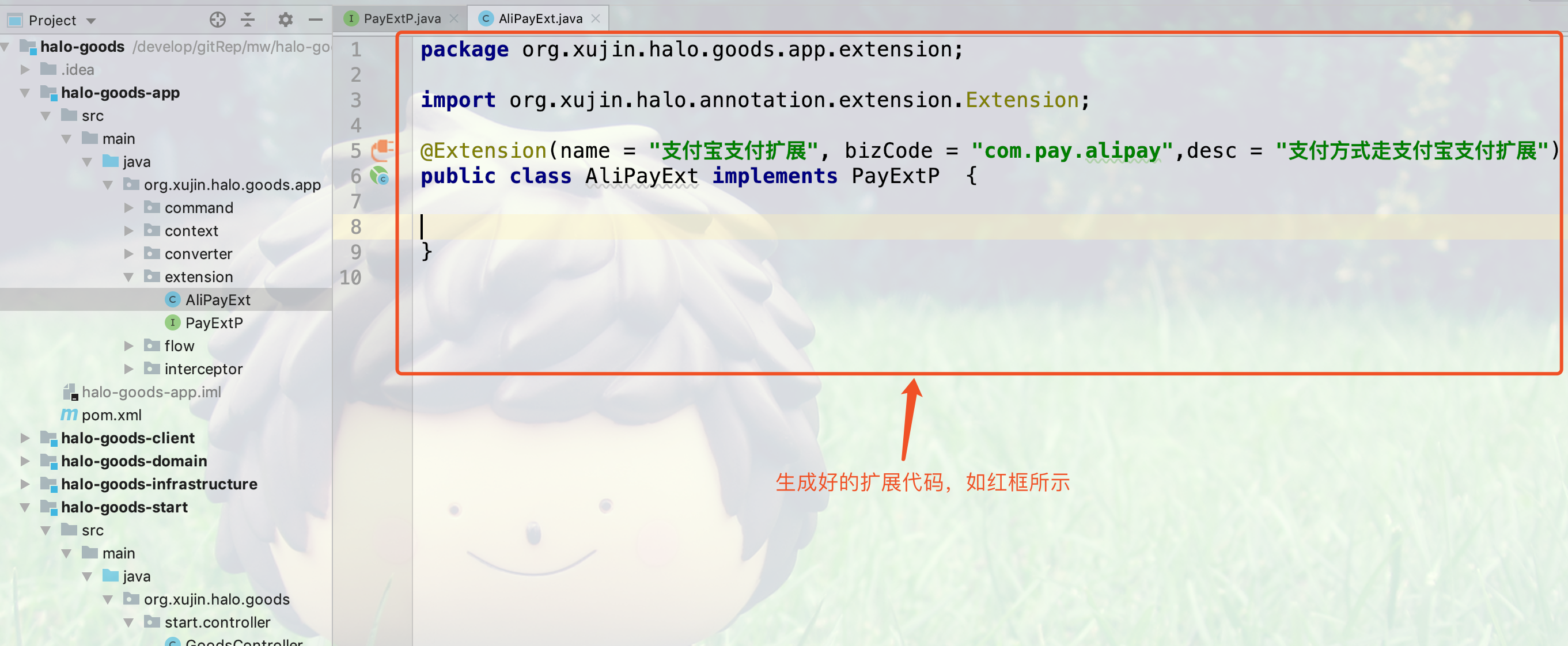
5.创建完的扩展代码如下所示:
17.4.13. 创建Event Object(事件对象)
-
在event的包下面,创建Event对象如下所示:
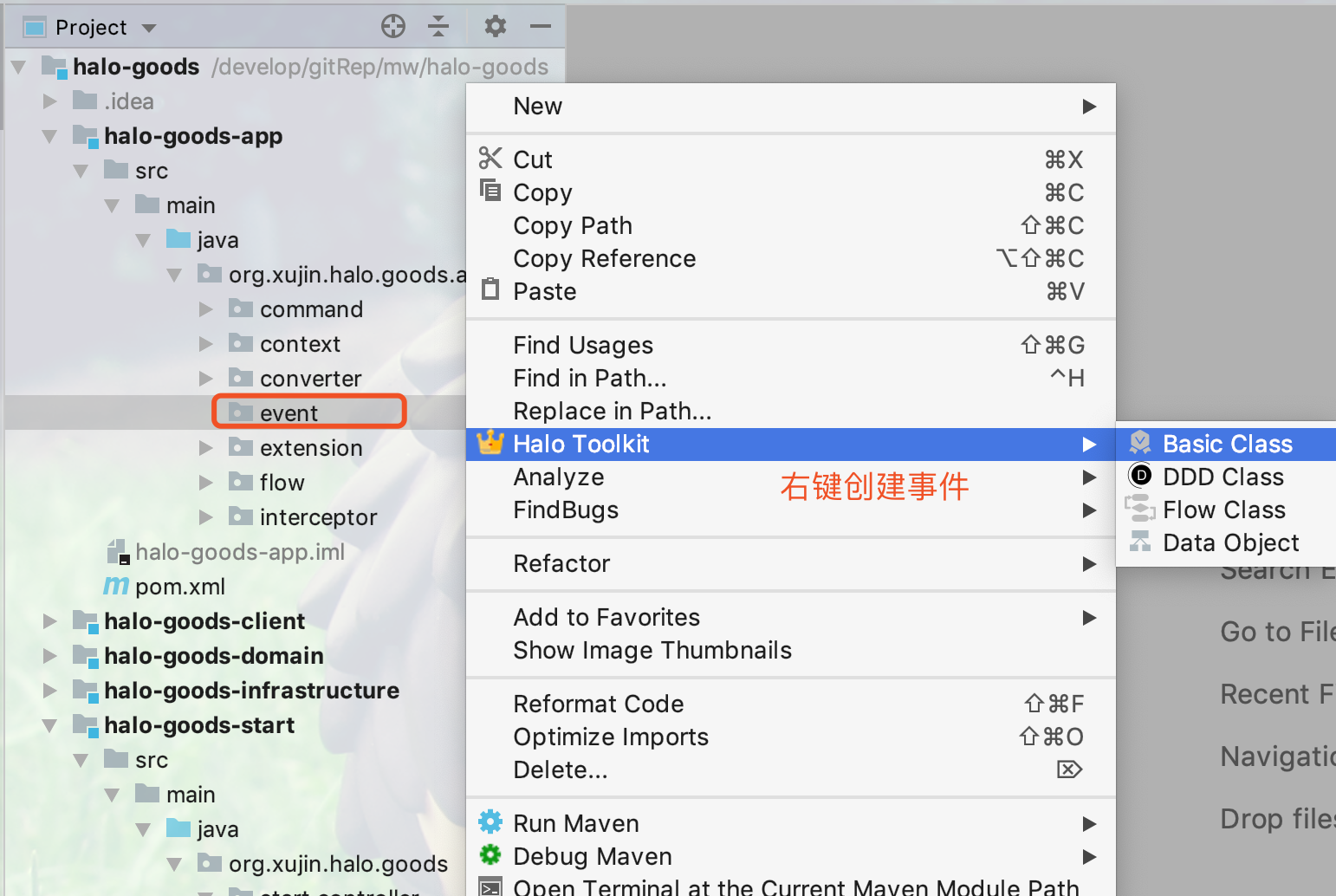
2.选择Class类型为Event Object,事件对象需要以Event结尾。
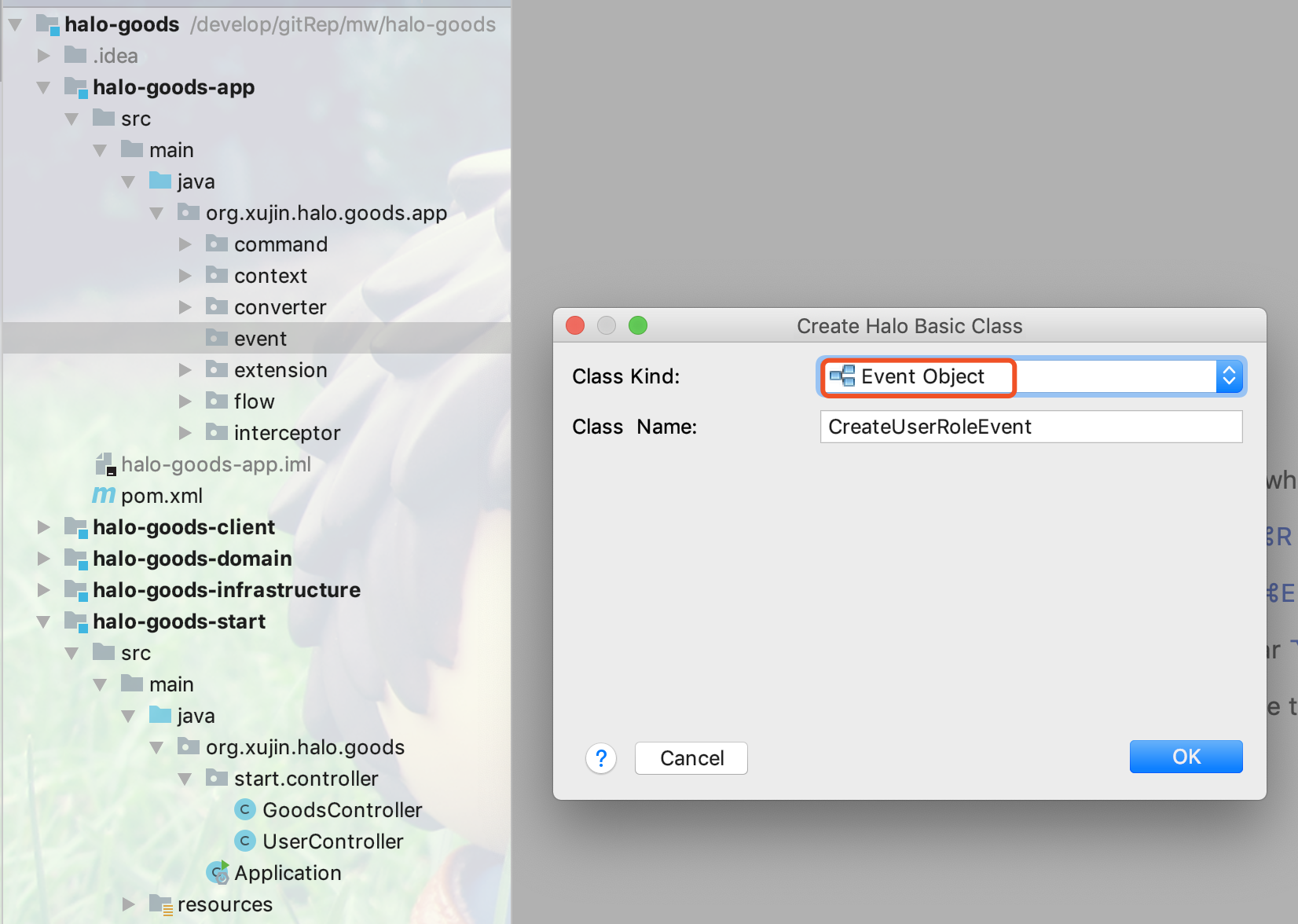
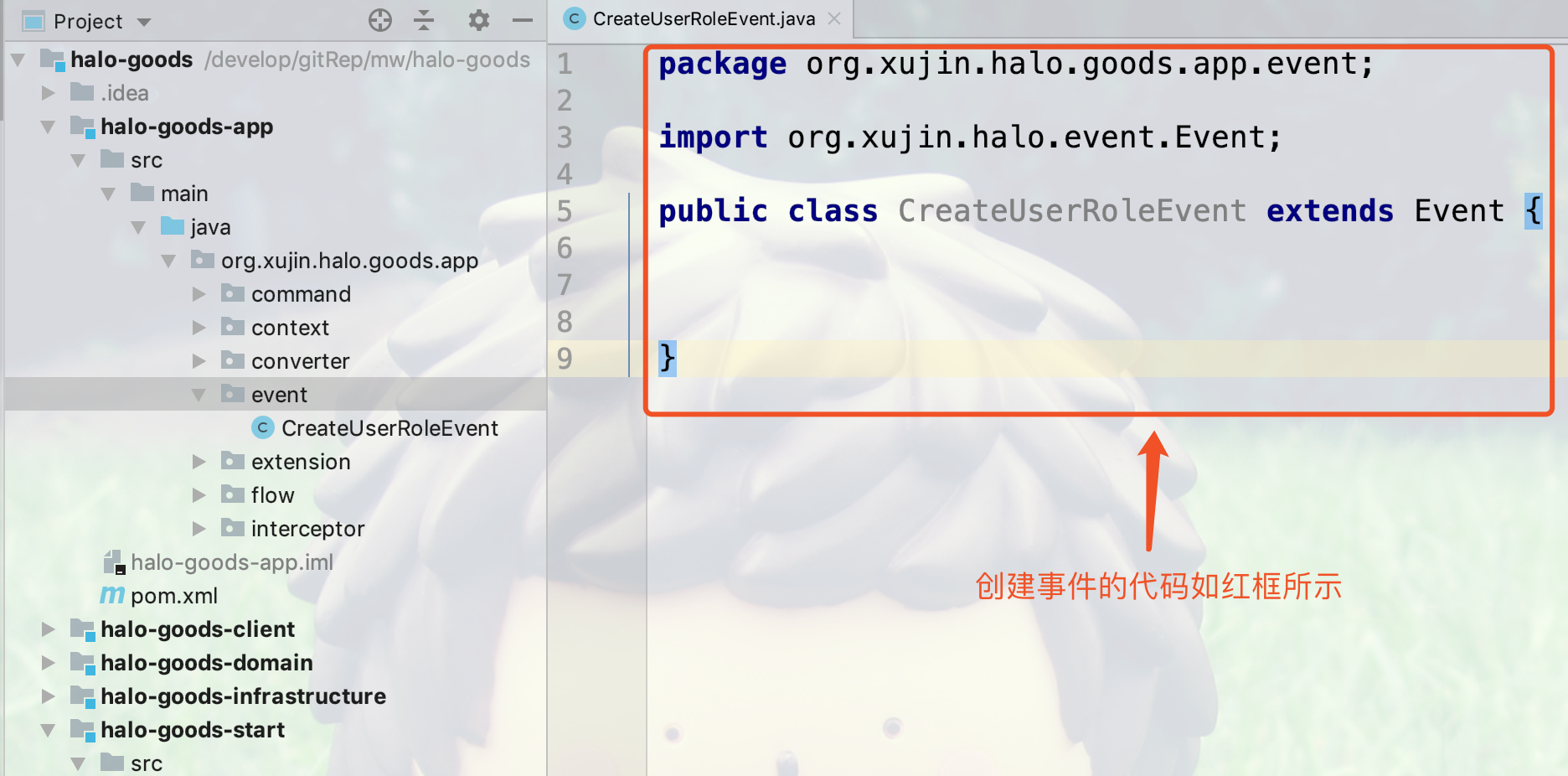
3.创建Event对象后的代码如下所示:
17.4.14. 创建 Event Handler(事件处理器)
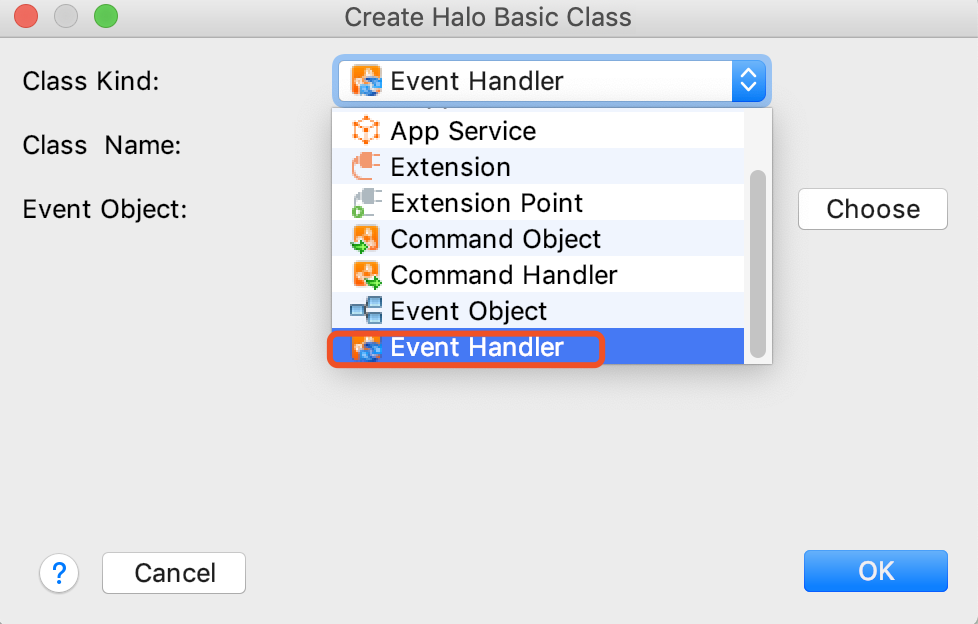
1.如下图所示,在event包下面右键创建事件处理器
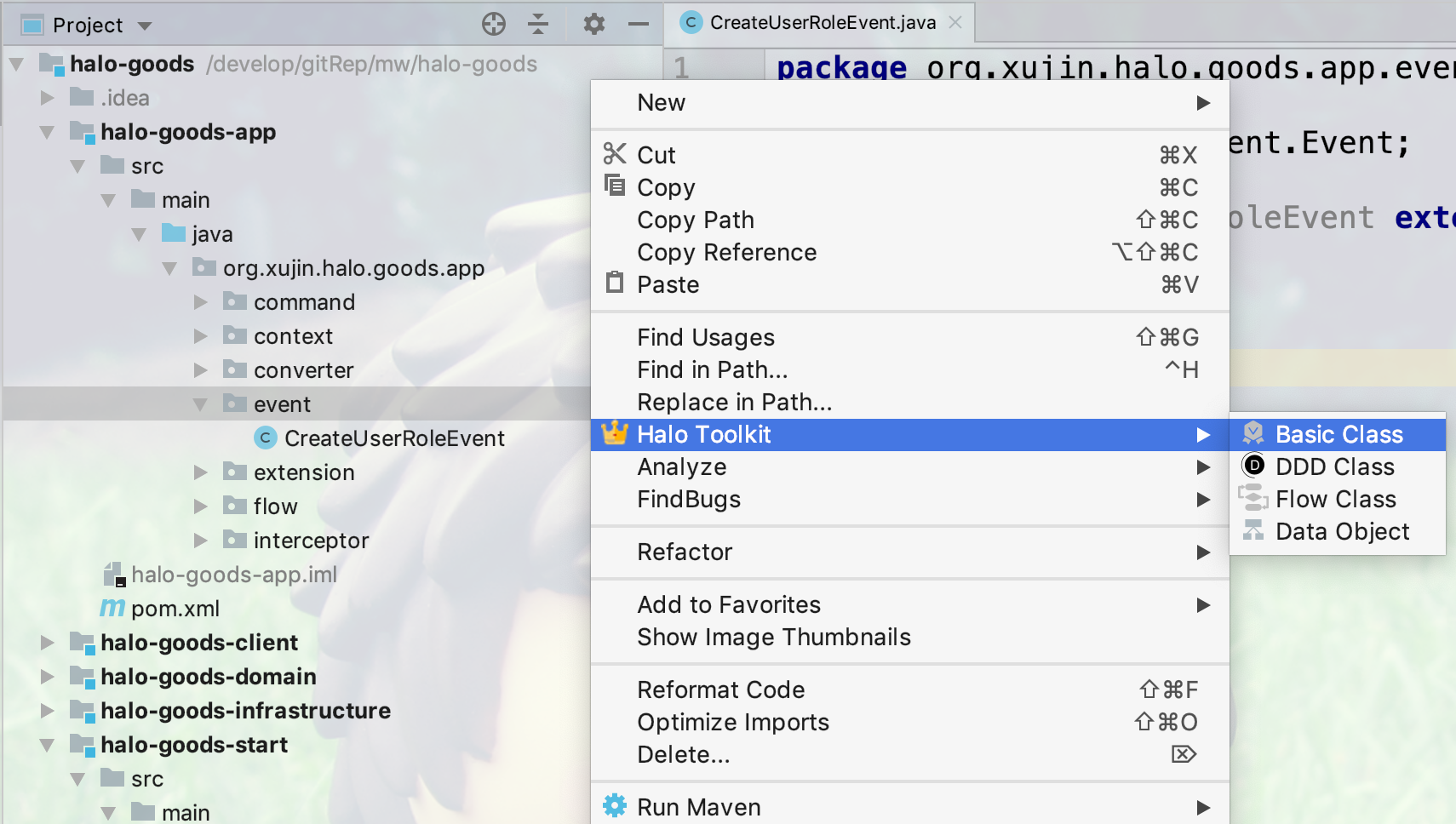
2.选择Class类型为Event Handler,如下图所示:
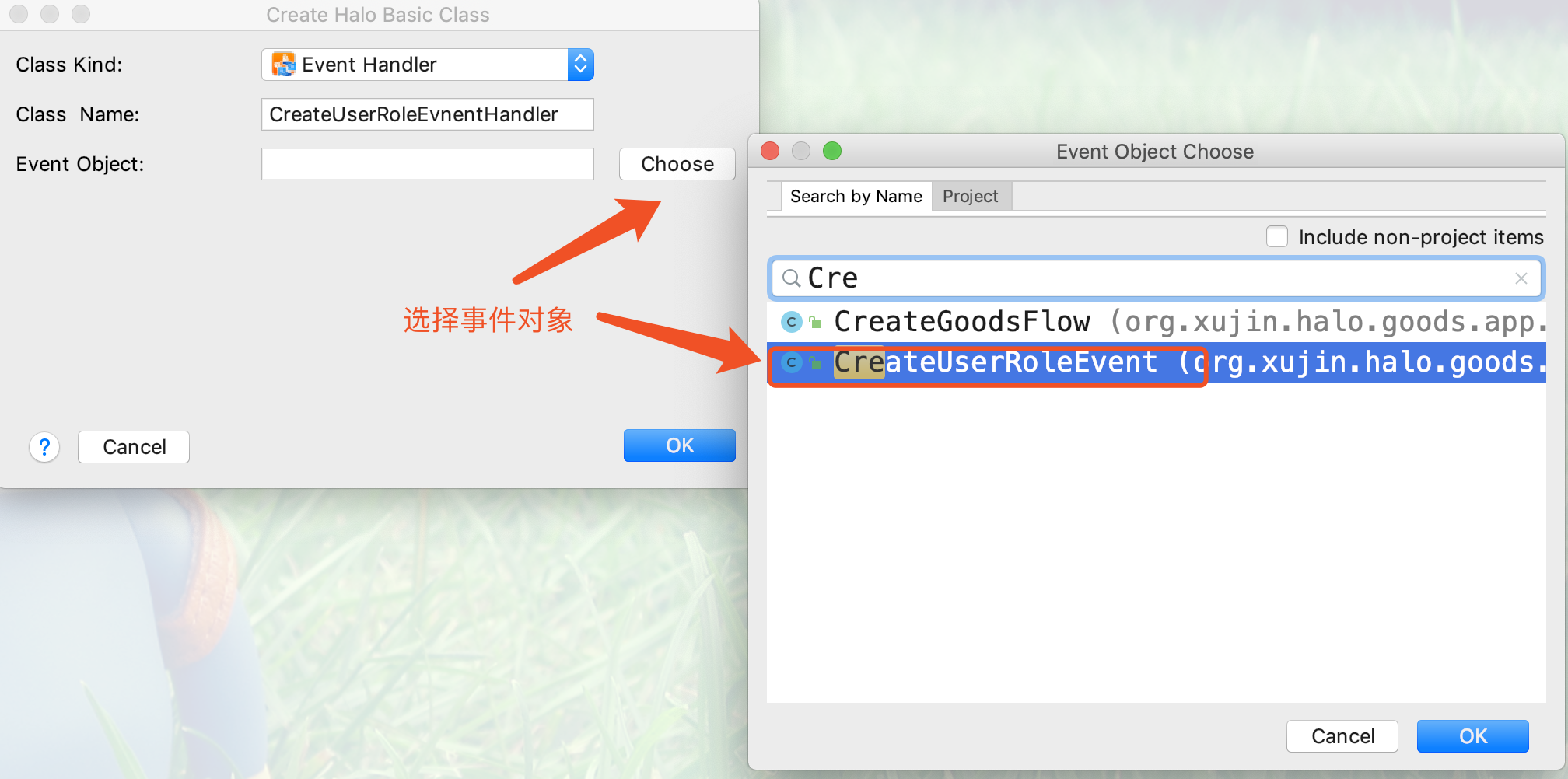
3.创建事件处理器,需要选择事件对象,如下图所示:
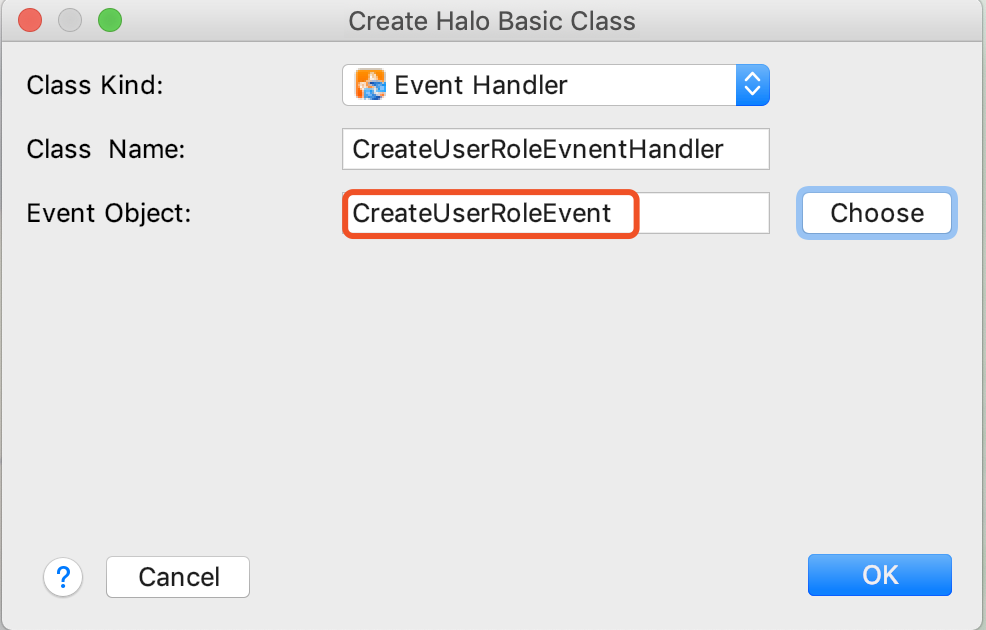
4.选择事件对象之后,自动回填设置数据对象。
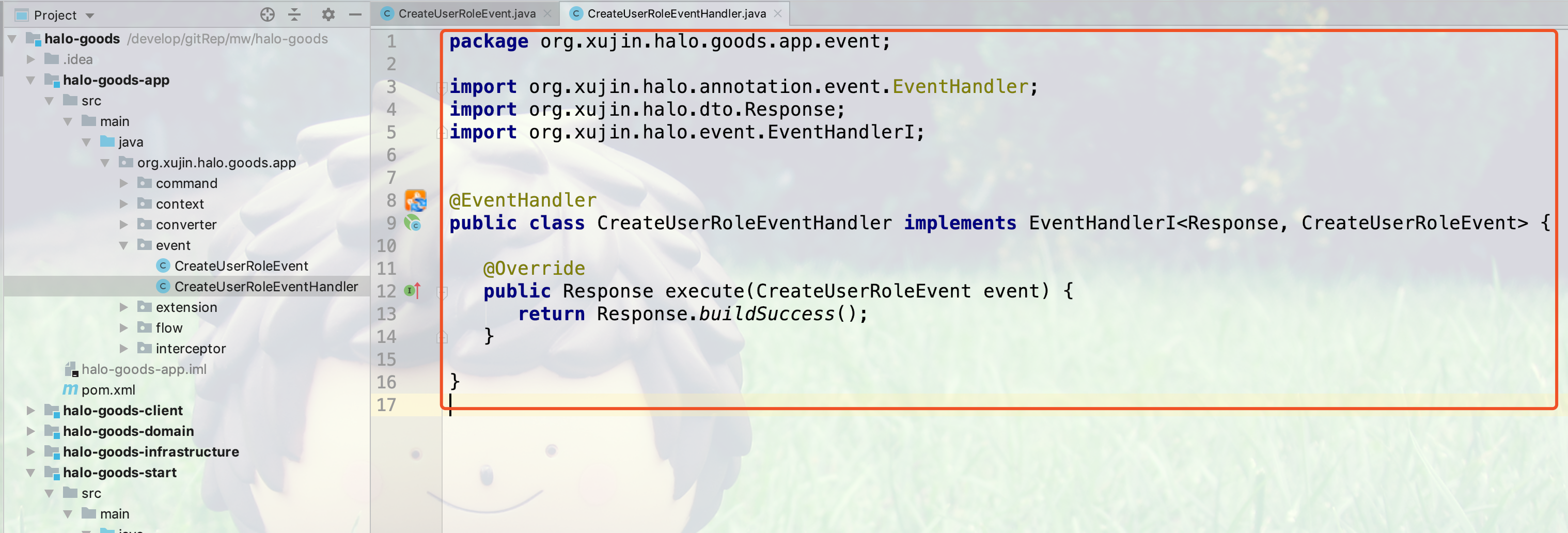
5.创建完的事件处理器的代码如下所示:
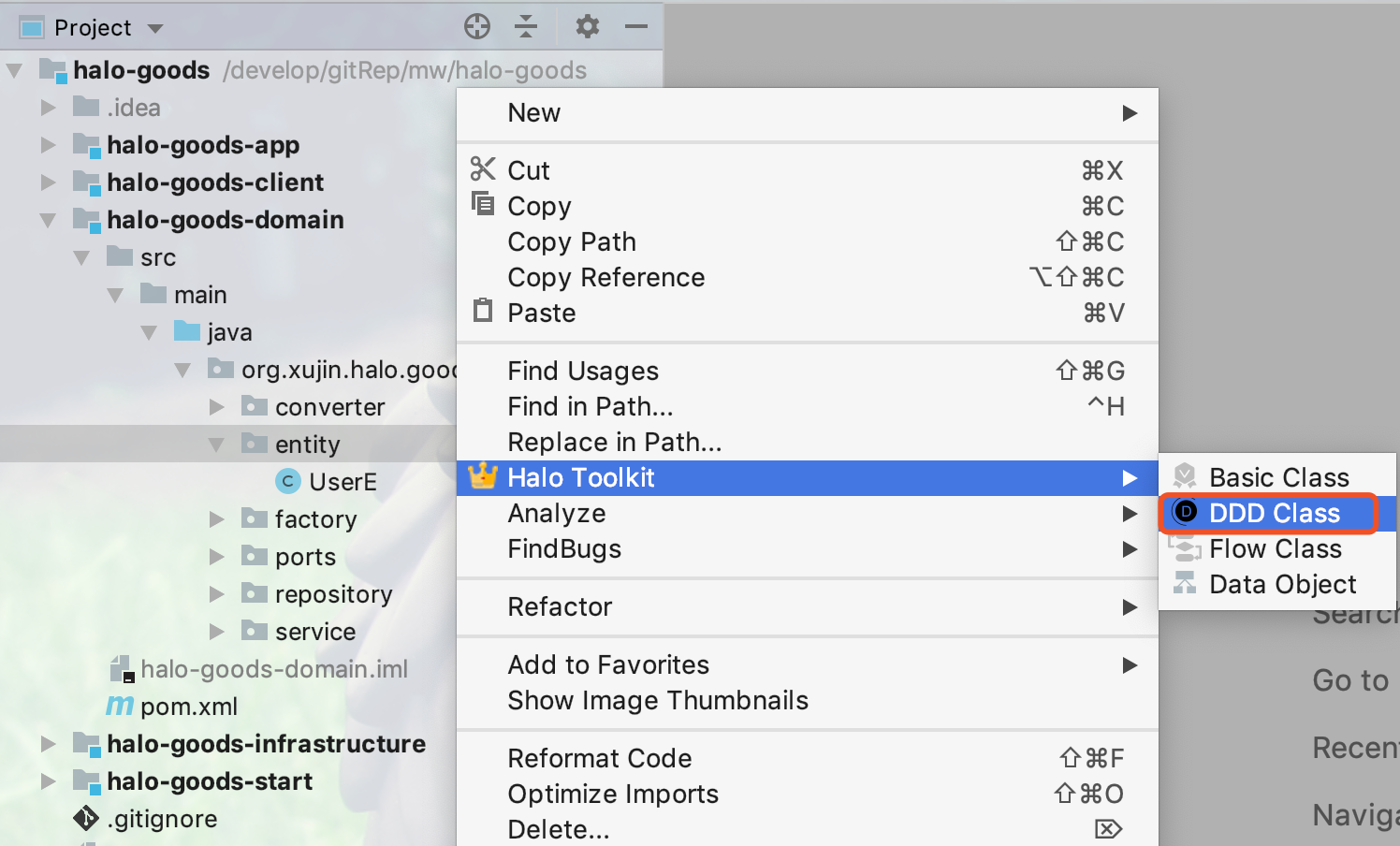
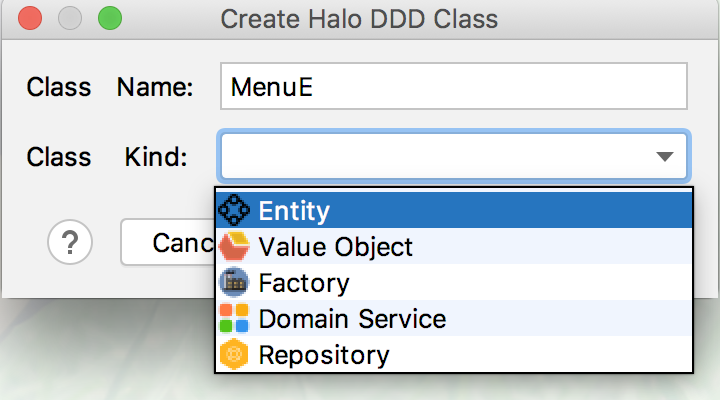
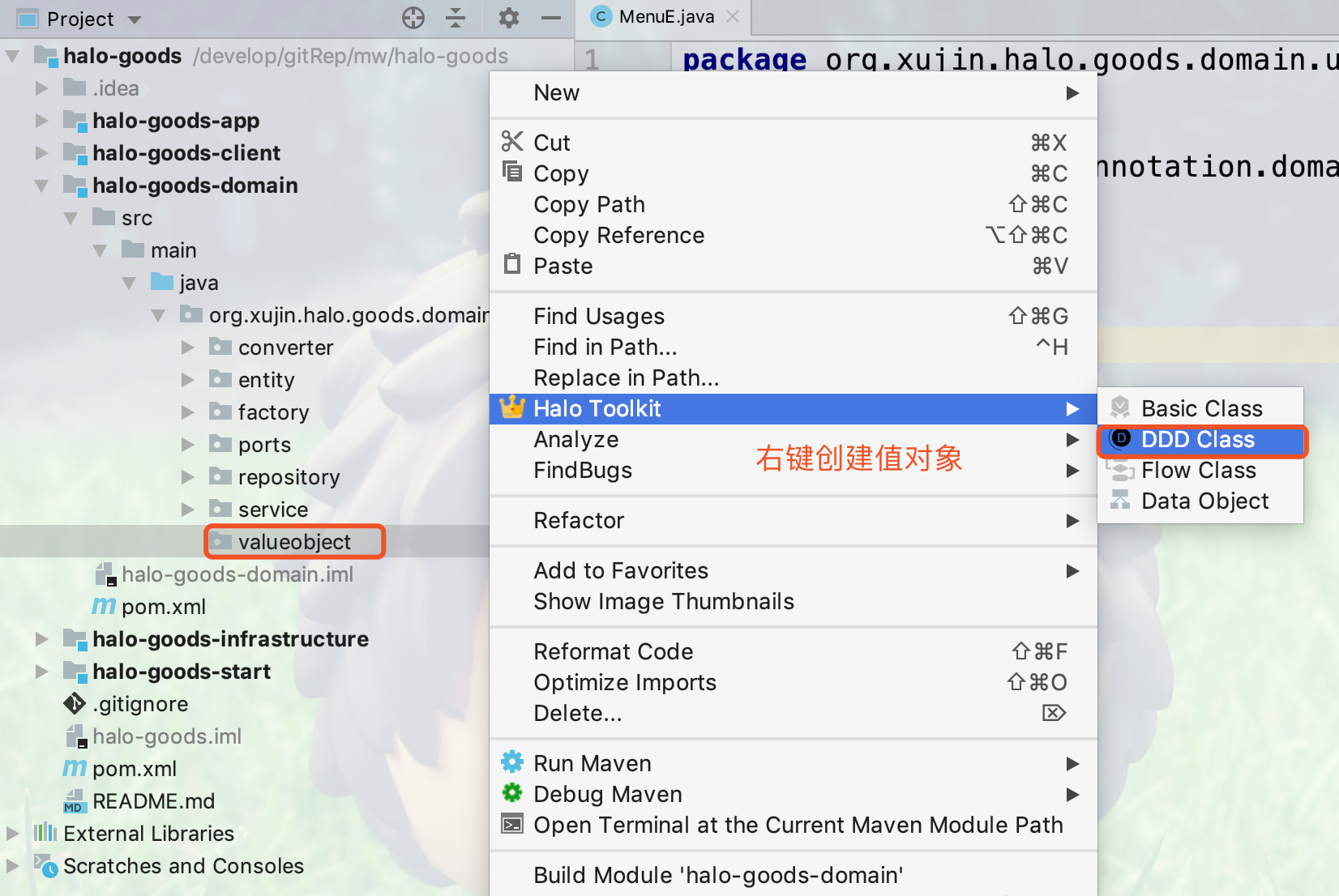
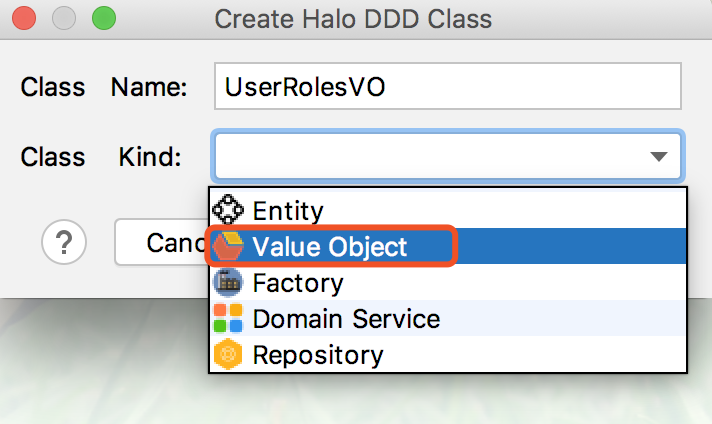
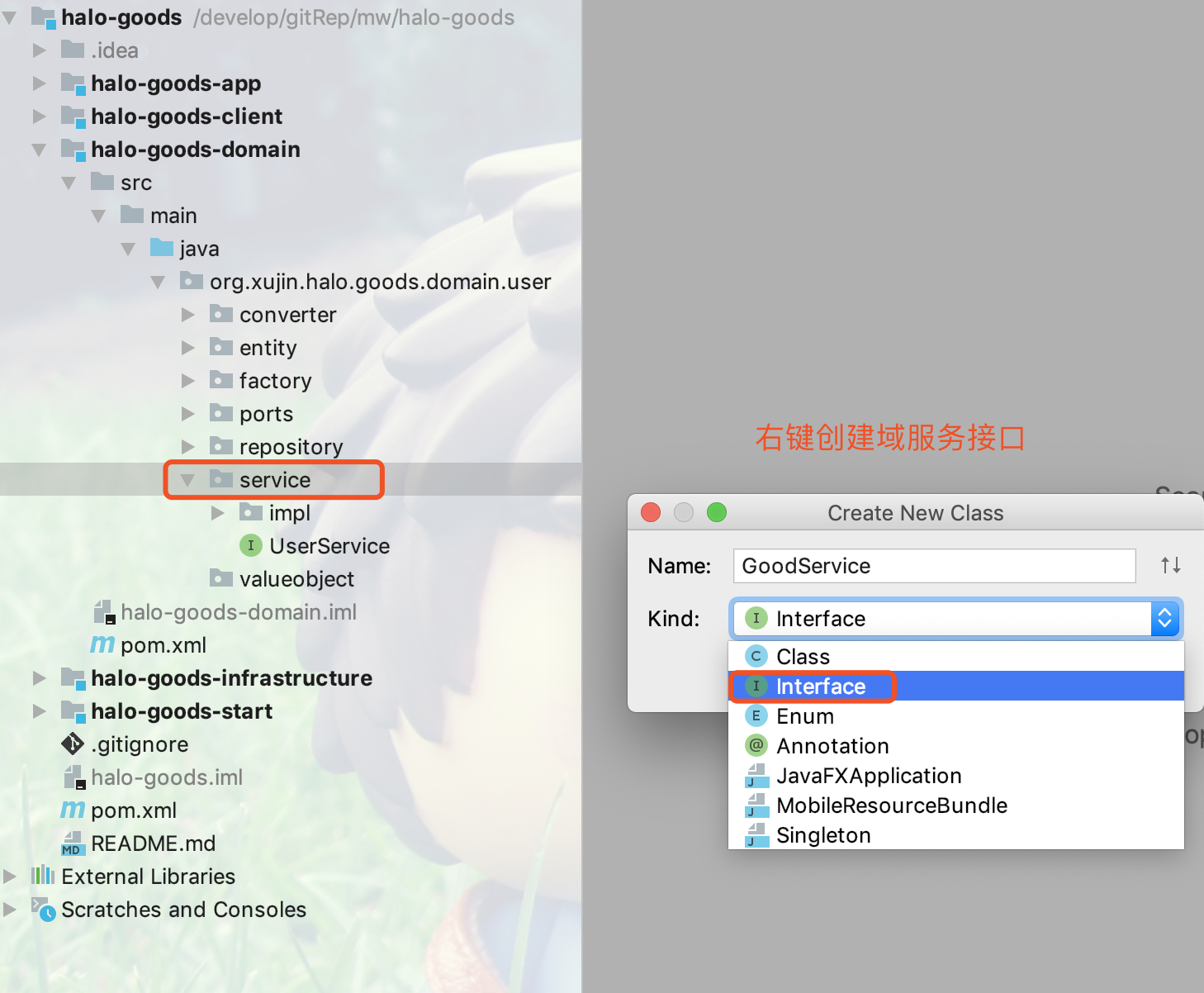
17.4.17. 创建Domain Service(领域服务)
1.点击service包右键,创建域服务接口如下图所示:
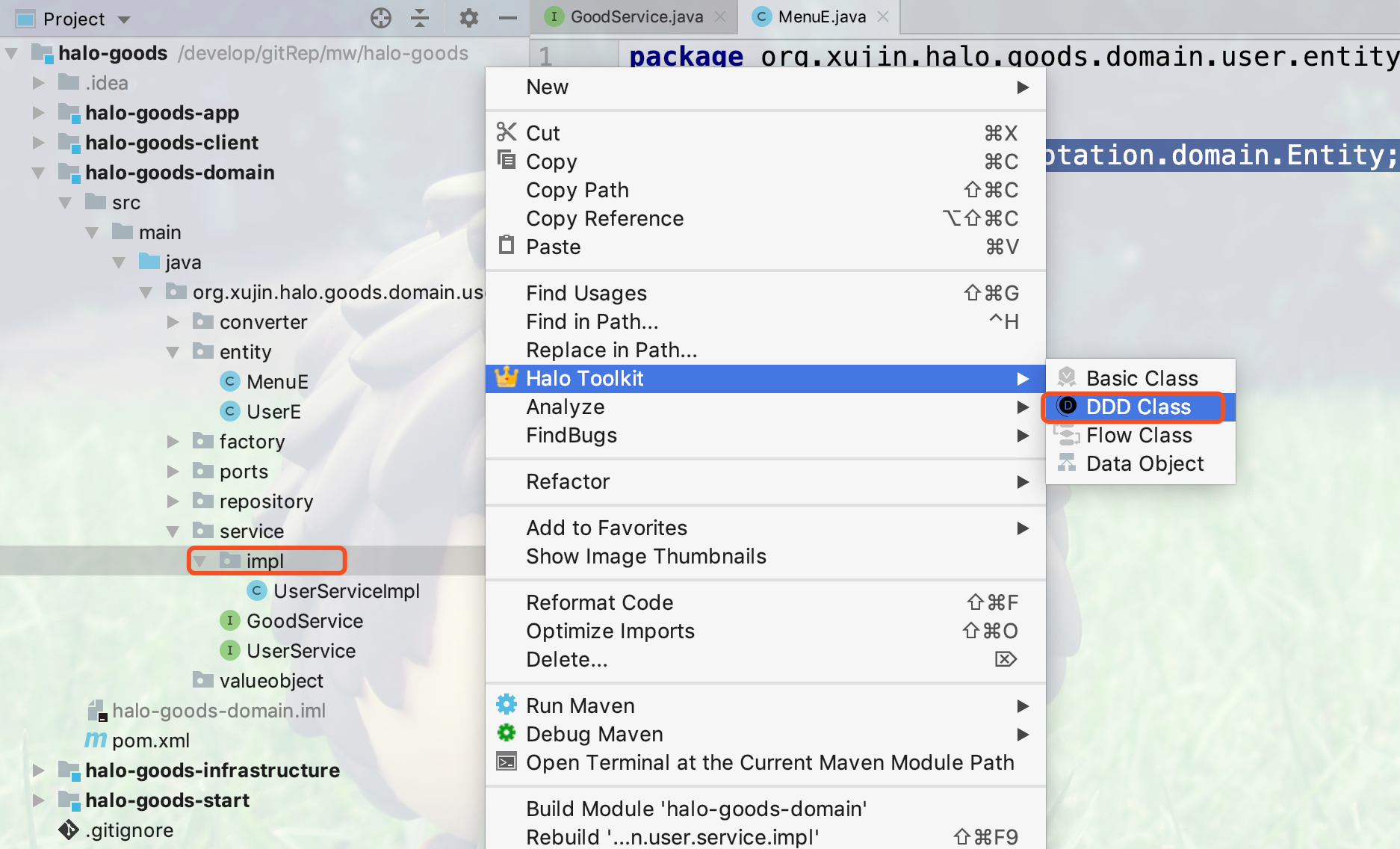
2.点击impl包右键,创建域服务接口的实现类,如下图所示:
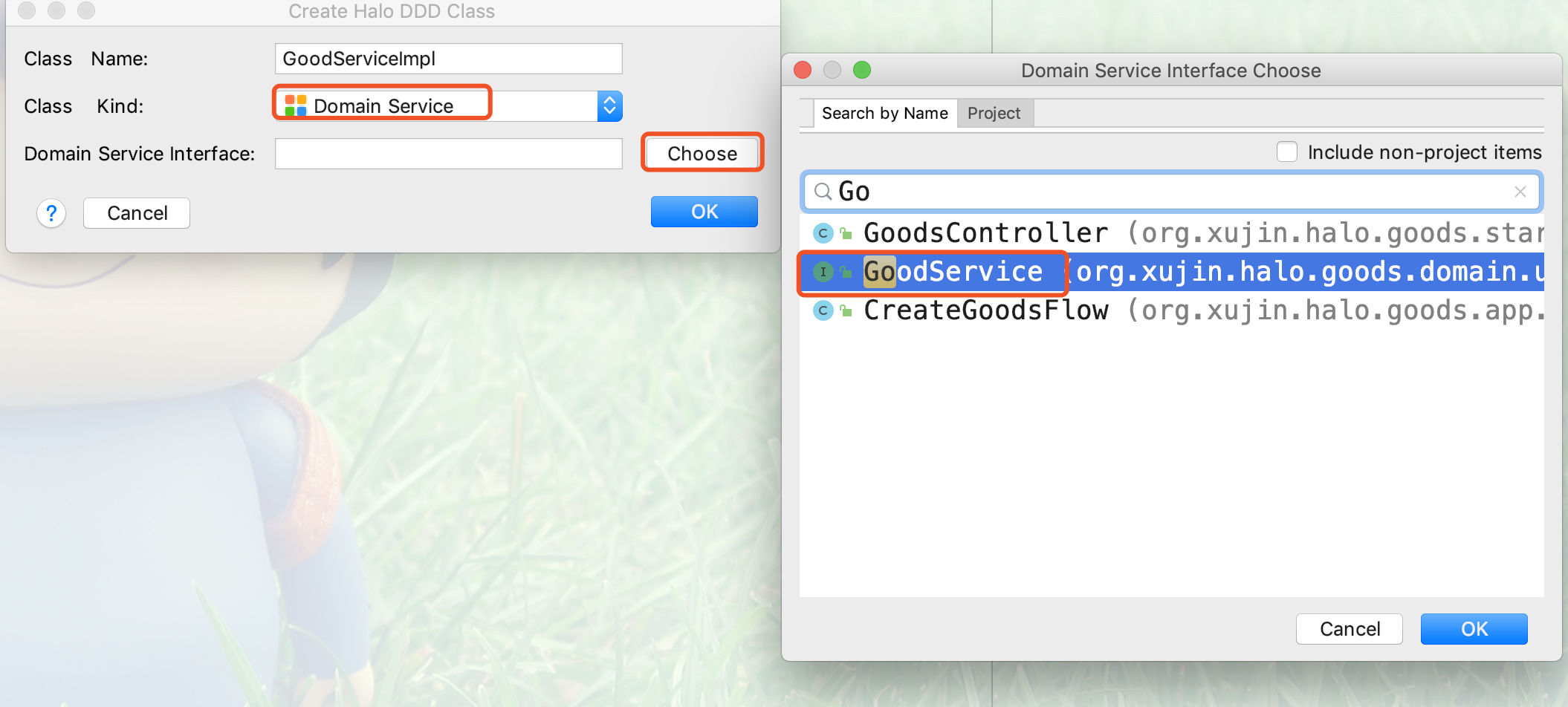
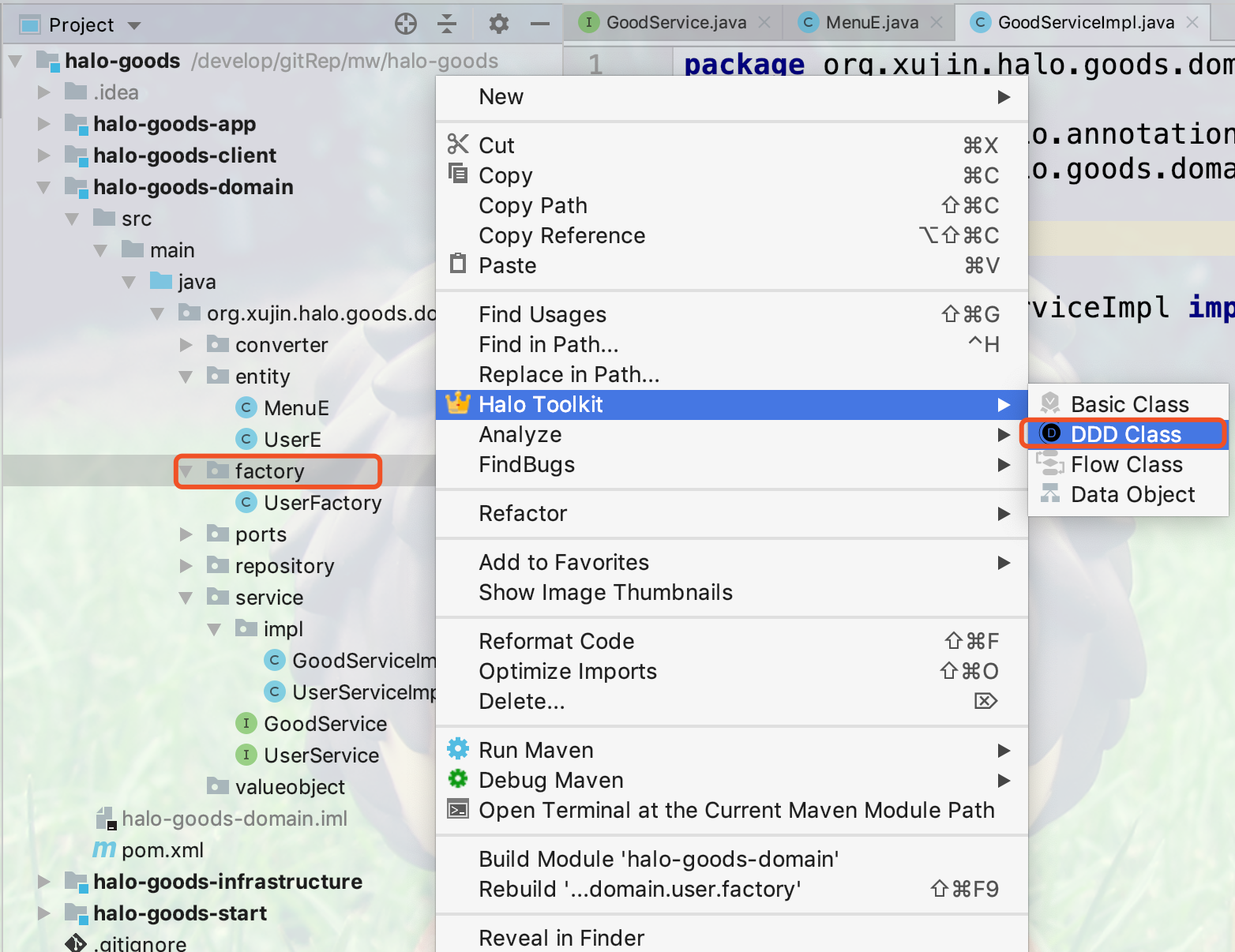
3.填写域服务的实现类名,点击Choose选择域服务接口,如下图所示:
V Halo Framework
18. Halo Framework概述
Halo Framework是基于 DDD+CQRS+扩展点+流程编排 的应用框架,致力于采用领域驱动的设计思想,规范控制程序员的随心所欲,从而解决软件的复杂性问题。
Halo设计原则简单,即在高内聚,低耦合,可扩展,易理解的指导思想下,尽可能的贯彻面向对象的设计思想和领域驱动设计的原则。
| Halo Framework是基于DDD+CQRS+扩展点的应用框架,业务系统使用之自带光环! |
Halo Framework的主要模块如下所示:
-
Halo主要模块
-
CQRS:读写分离架构-所有请求封装为命令对象,通过Command Bus分发到命令处理器执行,通过Event和Event Bus等实现读写分离。
-
halo-DDD: 根据领域驱动设计思想,自定义注解
@Entity(实体),@Factory(工厂),@DomainService(领域服务),@ValueObject(值对象),@DomainRepository(资源库),@DomainAbility(域能力)等进行战术设计,落地DDD,实现业务与业务隔离。 -
halo-extension:基于扩展点的设计思想,自定义
@ExtensionPoint(扩展点注解)和@Extension(扩展注解), 实现平台和插件隔离。 -
halo-flow:基于流程编排思想,开发业务组件,编排应用内部已有业务资产,快速响应前台需求,久而久之形成大量可复用的业务组件库。
-
-
Halo-tools
-
halo-codegen: 通过设计代码生成器, 快速生成最佳实践的基础代码和规范,提高开发效率和生产力,让业务开发人员专注于业务开发。
-
19. Halo Framework设计
19.1. Halo Core设计思想
Halo Core的主要思想是 流程组合节点,节点调用域服务,域服务包含若干域能力,域能力下若干个业务扩展。
-
业务包与平台分离的插件化架构: 平台提供插件包注册机制,实现业务方插件包在运行期的注册。业务代码只允许存在于插件包中, 与平台代码严格分离。业务包的代码配置库也与平台的代码库分离,通过二方包的方式,提供给容器加载
-
全链路统一的业务身份: 平台需要能有按“业务身份”进行业务与业务之间逻辑隔离的能力,而不是传统SPI架构不区分业务身份, 简单过滤的方式。如何设计这个业务身份,也成为业务间隔离架构的关键。
-
管理域与运行域分离: 业务逻辑不能依靠运行期动态计算,要能在静态期进行定义并可视化呈现。 业务定义中出现的规则叠加冲突,也在静态器进行冲突决策。在运行期,严格按照静态器定义的业务规则、冲突决策策略执行。

19.3. Halo中的概念

19.4. 统一应用名
Java工程有工程名,Spring Boot Appliaction Name,发布系统(云效,cmdb)有应用名,配置中心也有应用名,基于应用维度的服务注册和发现基于应用名注册,gitlab有仓库名等。这些应用名一般需要统一。
| 工程名 | 发布系统 | 配置中心 | 注册中心 | gitlab仓库名 | spring.appliaction.name | 备注 |
|---|---|---|---|---|---|---|
halo-demo |
halo-demo |
halo-demo,比如Apollo中的AppName |
halo-demo,比如Nacos中的应用名 |
halo-demo,比如gitlab中的仓库名为halo-demo |
halo-demo,设置spring.application.name为halo-demo |
19.5. Halo统一应用开发标准
在计算机世界,都是通过命令进行识别,计算输出结果。软件开发也是如此,一切皆为命令,从应用入口开始统一应用的开发模式。 不管是使用RPC框架,还是使用Spring Cloud统一应用的开发模式为
从controller层开始统一应用开发模式的示例代码,如下:
@RestController
@RequestMapping("/admin/user")
@Api("用户管理")
public class UserController {
@Autowired
protected CommandBus commandBus;
@GetMapping("/manage/allRole")
@ApiOperation(value = "查询所有角色")
@RequiresAuthentication
public ResultData<List<RoleCO>> getAllRole() {
return commandBus.send(QueryAllRoleCmdExe.class);
}
@PostMapping("/page")
@ApiOperation(value = "分页查询用户")
@RequiresPermissions("user:query")
public ResultData<PageResult<UserCO>> getUserPage(@RequestBody PageQueryUserCmd pageQueryUserCmd) {
return commandBus.send(pageQueryUserCmd);
}
@PostMapping("/add")
@ApiOperation(value = "增加用户")
@RequiresPermissions("user:add")
public ResultData<Void> addUser(@RequestBody AddUserCmd addUserCmd) {
return commandBus.send(addUserCmd);
}
@PostMapping("/update")
@ApiOperation(value = "更新用户")
@RequiresPermissions("user:update")
public ResultData<Void> updateUser(@RequestBody UpdateUserCmd updateUserCmd) {
return commandBus.send(updateUserCmd);
}
}| 如上述代码所示,所有的Java程序员写出来的Controller都是一个模板。 |
19.6. Halo统一Parent与版本
<!-- 使用halo-starter-parent 去统一管理所有jar的版本,统一基线-->
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<!--用如下方式去规范统一内部的或者第三方的jar版本,从而使业务框架升级无感知,实现1+1>3的效果 -->
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-swagger</artifactId>
</dependency>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-basic</artifactId>
</dependency>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-cloud-starter-nacos</artifactId>
</dependency>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>19.7. 统一基础组件环境的切换
每个公司有很多的基础组件(中间件),每个基础组件都有不同的环境,作为业务开发无需感知每个环境的URL等, 因此基础组件在设计开发时需要统一环境。Halo框架沿用Spring框架的-Dspring.profiles.active=dev的设计,统一切换环境。详细映射表如下所示:
| 英文缩写 | 英文 | 中文 |
|---|---|---|
dev |
development |
开发 |
fat |
Feature Acceptance Test |
测试 |
uat |
User Acceptance Test |
用户验收测试 |
pro |
production |
产品/正式/生产 |
19.8. 统一内外部基线
-
什么是基线(Baseline)?基线是软件或底层基础组件或源码(或其它产出物)的一个稳定版本,它是进一步开发上层建筑或软件应用平台的基础。对于平台化,服务化的大型IT技术公司,基线显得尤为重要,跟地基一样重要。
-
外部基线(第三方基线,最简单的理解就是Spring的版本,Spring Boot的版本,Nacos的版本等,或者外部中间件的客户端版本和服务端版本,
-
公司内部基线(内部的各中间件版本),比如Juno,Phenix等中间件的版本组成一个可用不冲突的,稳定套餐版本,用户体验好的基线就是内部中间件基线
19.9. 业务应用依赖标准化
通过发布系统,在应用构建的时候,进行打包构建。扫描规则如下:
-
Parent扫描,Halo应用pom文件中必须包含关键字:
-
halo-starter-parent
-
-
Halo应用pom中不允许出现,如下关键字
-
spring-boot-starter-parent
-
带有spring-cloud前缀的
-
spring-boot-starter-web
-
mybatis-plus-boot-starter
-
mybatis-spring
-
spring-boot-starter-test
-
spring-test
-
junit
-
HikariCP
-
mysql
-
spring-data-redis
-
redis.clients
-
spring-boot-starter
-
-
关键字对应的组件标准化
| 关键字 | 是否有 | 工程依赖则必须只能是 | 备注 |
|---|---|---|---|
mybatis或jdbc |
有 |
halo-boot-starter-mybatis |
两者必须有 |
skywalking |
有 |
halo-boot-starter-skywalking |
|
redis |
有 |
halo-boot-starter-jedis |
只能是其中一个 |
springfox |
有 |
halo-boot-starter-swagger |
|
web |
有 |
halo-boot-starter-web |
|
test |
有 |
halo-boot-starter-test |
-
Halo工程统一POM依赖check
-
Halo Check Case:所有Halo工程不允许,显示出现Mysql驱动:mysql-connector-java
-
[INFO]
_ ___ _ _
/\ /\__ _| | ___ / __\ |__ ___ ___| | __
/ /_/ / _` | |/ _ \ / / | '_ \ / _ \/ __| |/ /
/ __ / (_| | | (_) | / /___| | | | __/ (__| <
\/ /_/ \__,_|_|\___/ \____/|_| |_|\___|\___|_|\_\
[INFO] --------Halo Check Maven Pom------------
[INFO] start get project parent:halo-starter-parent
[INFO] start get project parent:halo-starter-parent
[INFO] start get project parent:halo-demo
[INFO] start get project parent:halo-demo
[INFO] start get project parent:halo-demo
[INFO] start get project parent:halo-demo
[ERROR] Internal error: java.lang.RuntimeException: Maven依赖不能包含:[mysql-connector-java] -> [Help 1]
org.apache.maven.InternalErrorException: Internal error: java.lang.RuntimeException:
Maven依赖不能包含:[mysql-connector-java]
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:120)
19.10. Halo CQRS 2.0设计
Halo的整体架构如下图所示:
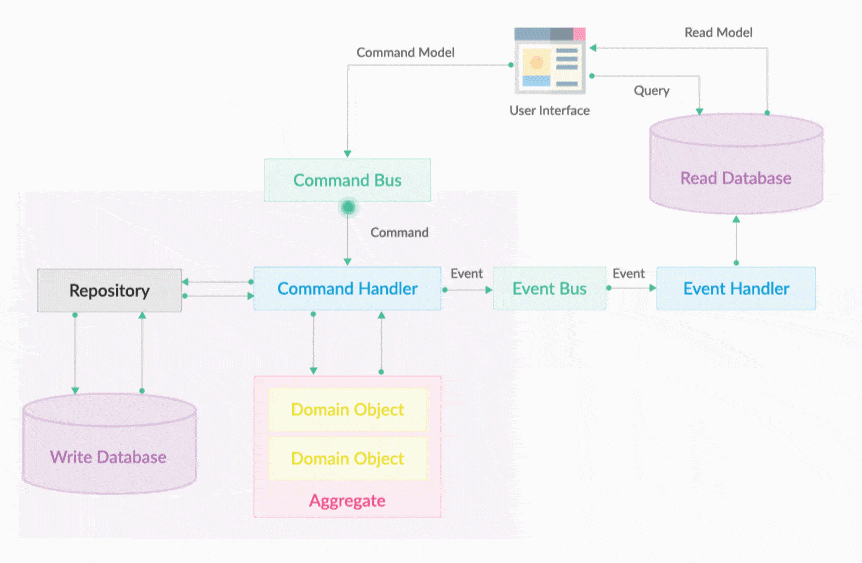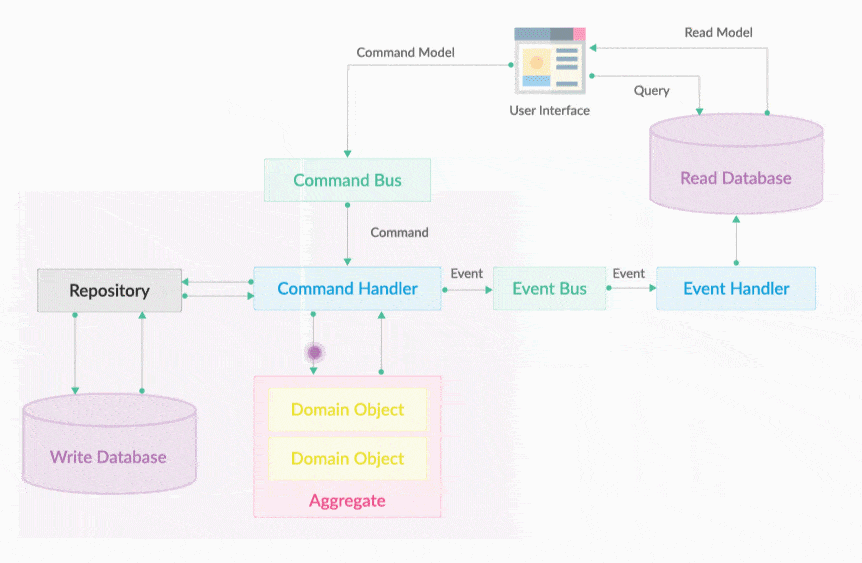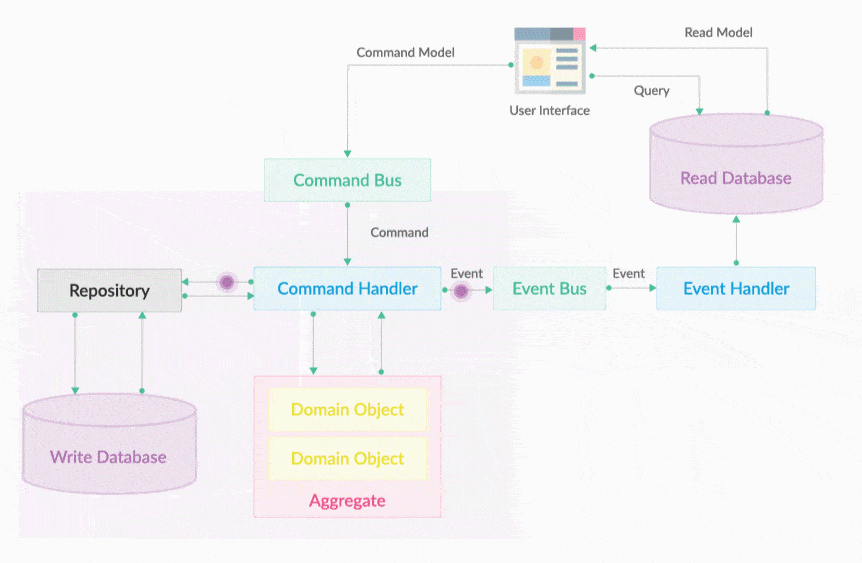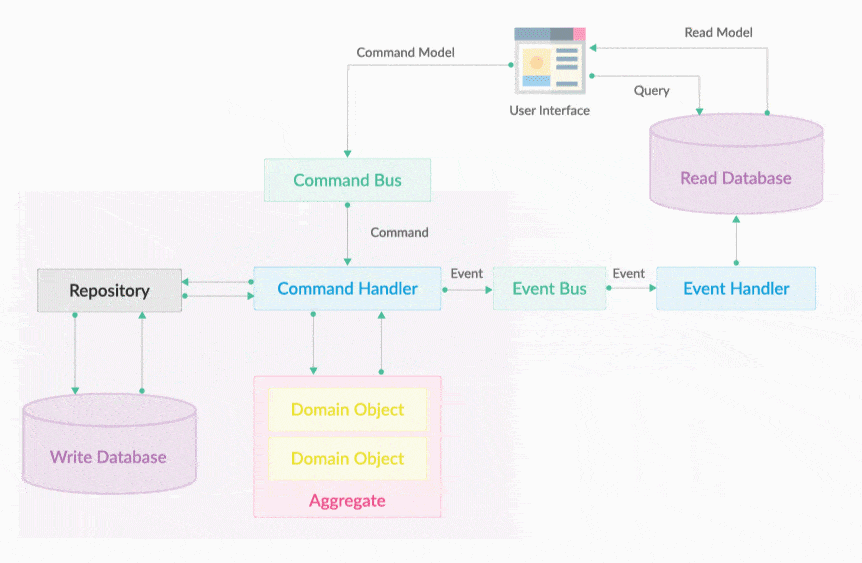
一切用户请求进来皆为命令,封装成命令对象通过Command Bus放送到Command Hub中路由通过命令执行器执行。
Halo CQRS 2.0架构图设计如下:
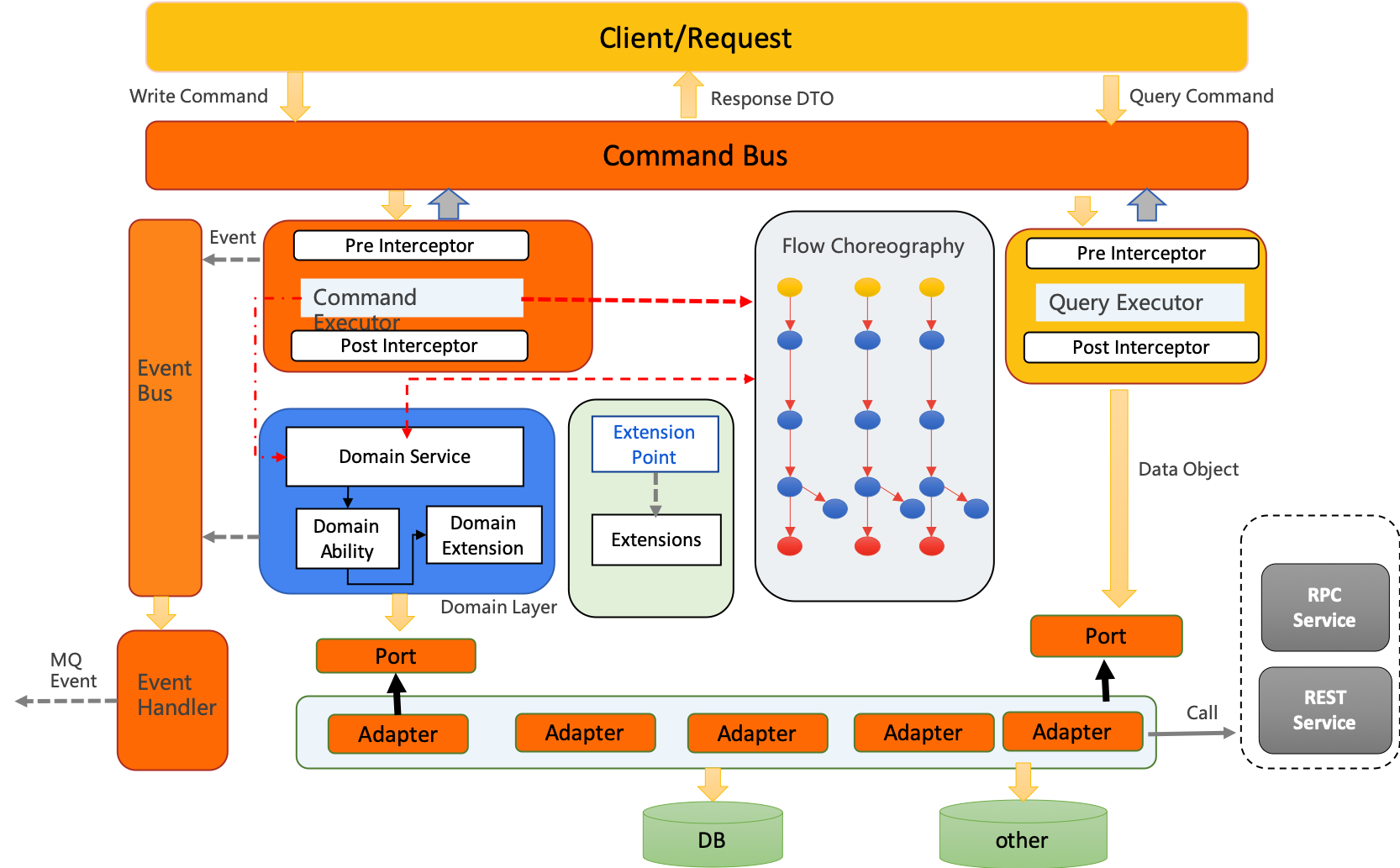
| Halo CQRS引入了端口和适配器模式,domain层与App层都是通过端口去访问基础设施层 |
Halo CQRS 1.0架构图设计如下:
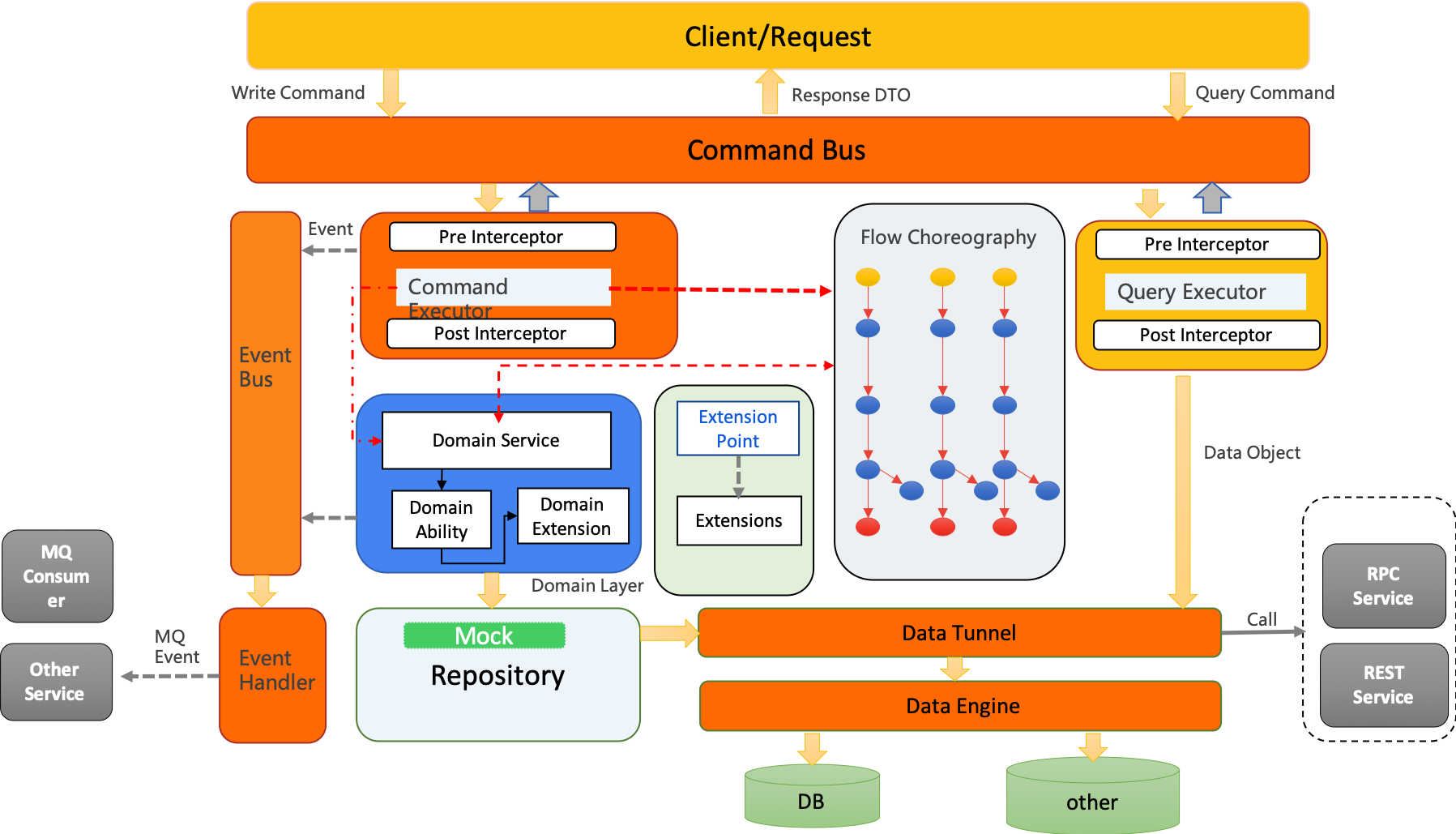
| Halo框架在应用启动的时候会通过扫描自定义的注解,通过高度抽象的RegisterFactory,将命令,命令拦截器,扩展点,流程编排等信息注册到 Spring容器中和应用的内存结构中。 |
19.11. Halo DDD同类产品
Axon Framework是国外的一款CQRS+DDD的框架,但是没有扩展点设计,流程编排,相对Halo Core来说比较复杂,无法自主可控, 并且已经转向商业模式。而国内建飞哥开源的Cola和Halo的扩展点思想,源于TMF设计思想,Halo DDD与Axon,Cola的对比表格如下所示:
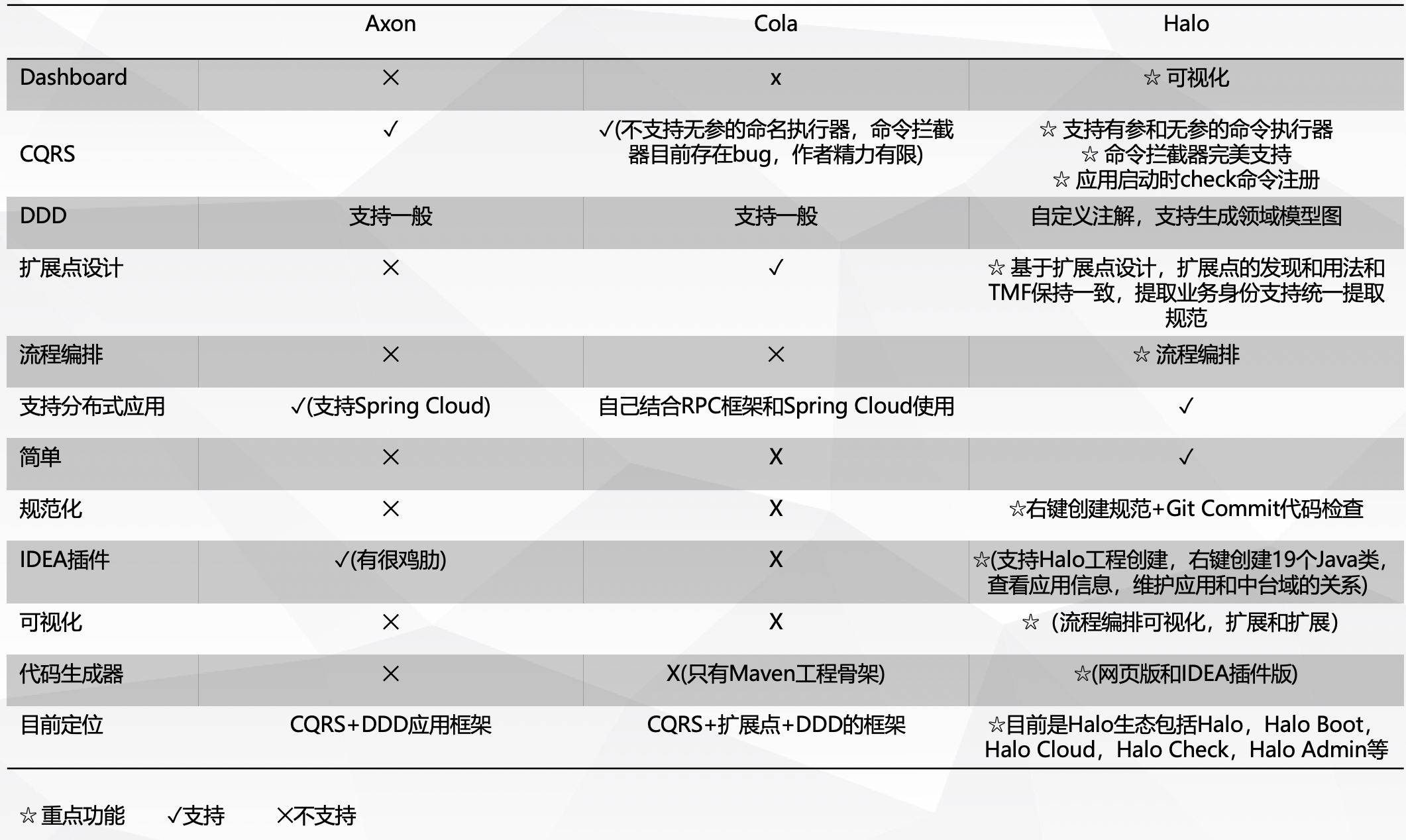
| 综合来讲Halo是比Axon,Cola更具有竞争力,是市面上所有产品媲美,更合适作为底层中间件支撑上层应用开发。 PS:感谢建飞哥在我阿里工作期间的指导与交流,让我对DDD有了更深刻的理解与认知。 |
20. Halo CQRS
20.1. CQRS概述
20.1.1. 什么是CQRS
CQRS(Command Query Responsibility Segregation)是一种简单的设计模式。它衍生与CQS,即 命令 和 查询分离,
CQS是由Bertrand Meyer所设计。按照这一设计概念,系统中的方法应该分为两种:改变状态的命令 和 返回值的查询。
Greg young将引入了这个设计概念,并将其应用于对象或者组件当中,即现在的CQRS。
CQRS的核心思想是将应用程序的查询部分和命令部分完全分离,这两部分可以用完全不同的模型和技术去实现。比如命令部分可以 通过领域驱动设计来实现;查询部分可以直接用最快的非面向对象的方式去实现,比如用SQL。
下面,将通一张图来说明应用程序中有关CQRS部分的组成结构:
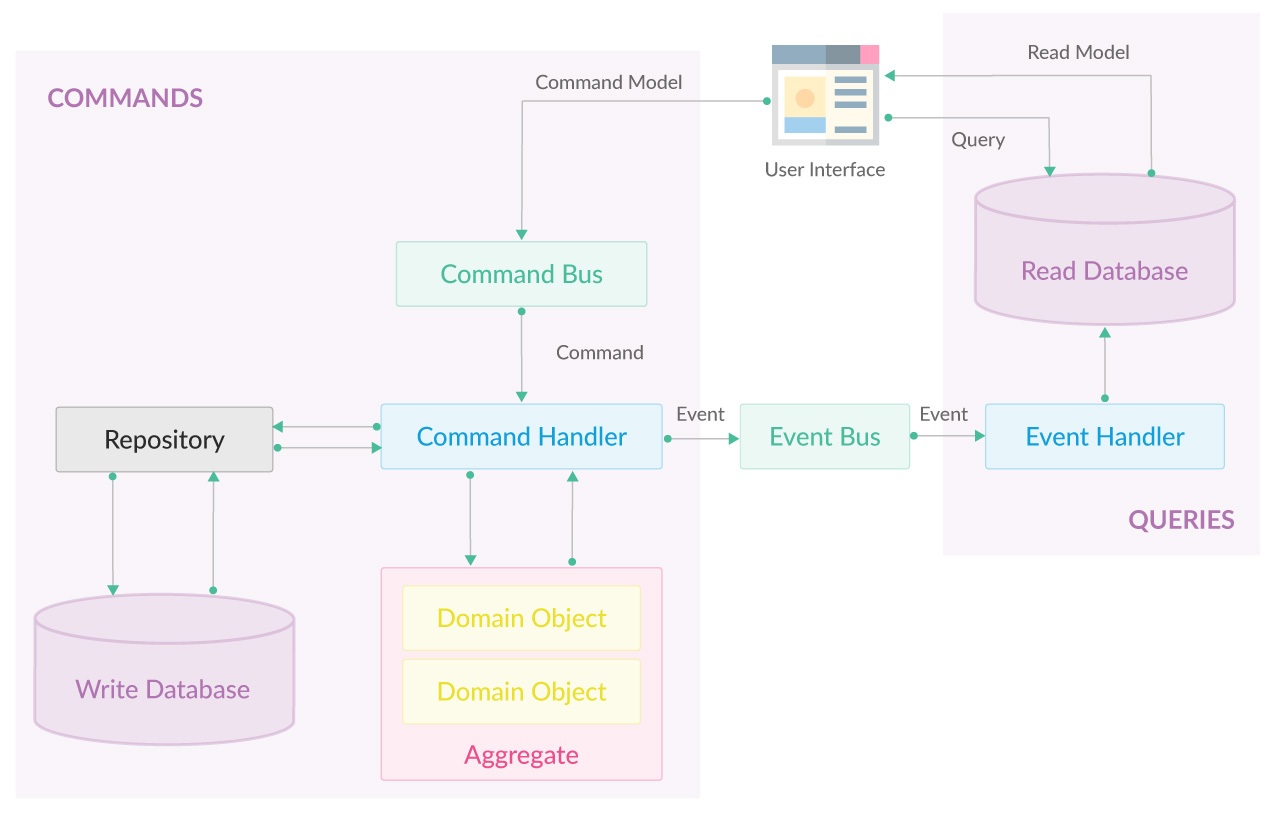
=== 下面介绍一下CQRS中主要的概念 ===
-
Commands(命令)—表示用户的操作意图。它们包含了与用户将要对系统执行操作的所有必要信息。
-
Command Bus(命令总线):是一种接收命令并将命令传递给命令处理程序的队列。
-
Command Handler(命令处理程序):包含实际的业务逻辑,用于验证和处理命令中接收到的数据。Command handler负责生成和传播域事件(Event)到事件总线(Event Bus)。
-
Event Bus(事件总线):将事件发布给订阅特定事件类型的事件处理程序。如果存在连续的事件依赖,事件总线可以使用异步或者同步的方式将事件发布出去。
-
Event Handler(事件处理程序):负责处理特定类型的事件。它们的职责是将应用程序的最新状态保存到读库中,并执行终端的相关操作,如发送电子邮件,存储文件等。
-
Query(查询):表示用户实际可用的应用程序状态。获取UI的数据应该通过这些对象完成。
20.2. Halo中CQRS的实现
CQRS的核心思想是将应用程序的查询部分和命令部分完全分离,这两部分可以用完全不同的模型和技术去实现。 比如命令部分可以通过领域驱动设计来实现;查询部分可以直接用最快的非面向对象的方式去实现,比如用SQL。
=== 这样的思想有很多好处: ===
-
实现命令部分的领域模型不用经常为了领域对象可能会被如何查询而做一些折中处理;
-
由于命令和查询是完全分离的,所以这两部分可以用不同的技术架构实现,包括数据库设计理论上都可以分开设计,每一部分可以充分发挥其长处;
-
高性能,命令端因为没有返回值,可以像消息队列一样接受命令,放在队列中,慢慢处理;处理完后,可以通过异步的方式通知查询端,这样查询端可以做数据同步的处理。
20.3. Command命令
什么是命令 (Command)? 用户界面/展现层的读取或者写入操作都将被封装为一个命令,Command中将不会带有具体的业务逻辑,业务逻辑将在领域层处理。
Command的实现涉及到三个东西,分别是 命令对象 (Command Object,简称cmo),命令执行器 (CommandExecutor),命令总线 (Command Bus)。
Q:命令该怎么命名?
| 关于命令的命名问题 在给Command类命名的时候,由于Command表示的是想要执行的命令,所以Command类的类名应当是动词的形式。例如RegisterCommand, ChangePasswordCommand等。其中的Command后缀则是可选的, 只要在系统中统一规范命名即可。 |
Q:命令可以复用吗?
| 在实际项目中,我们需要注意Command的类名的重要作用,每个Command类的名称都清晰地表达了一个意图,例如ChangePasswordCommand 清晰的表达了这个命令是要修改密码,所以千万不要随意"复用"Command。 |
这里的复用有两层含义,分别是:
-
看到某两个Command中有完全一样的属性,为了减少几行代码就觉得没有必要使用两个Command,而把它们合并成一个Command, 这样的"复用"会让系统变得越来越难以理解。
-
一个命令对应多个命令执执行器。
|
Halo Framework不允许复用命令,在命令注册的时候会统一check,如果发现复用会抛出异常。 |
20.3.1. Command的分类
命令分为两种命令,如下所示:
-
Command命令:增加,删除,修改等操作的写命令
-
Query命令: 主要用于查询的命令,由于是读写分离的架构,所以Query命令,可以直接访问数据库层。
20.4. Command拦截器
命令拦截器主要分为两种,分别是前置命令拦截器和后置命令拦截器。
-
前置命令拦截器: 被@PreInterceptor注解修饰的类并实现了CommandInterceptorI接口。
-
后置命令拦截器: 被@PostInterceptor注解修饰的类并实现了CommandInterceptorI接口。
如下所示的示例代码,通过前置命令拦截器和后置命令拦截器实现一个执行日志记录功能,
1.定义了一个前置命令拦截器
@PreInterceptor (1)
@Order(1) (2)
public class LoggerPreInterceptor implements CommandInterceptorI{ (3)
Logger logger = LoggerFactory.getLogger(LoggerPreInterceptor.class);
private ThreadLocal<Long> startTimeLocal=new ThreadLocal<>();
@Override
public void preIntercept(Command command) {
logger.debug("Begin to process %s", command);
startTimeLocal.set(System.currentTimeMillis());
}
public Long getStartTime() {
return startTimeLocal.get();
}
}| 1 | @PreInterceptor是前置命令拦截器注解 |
| 2 | @Order(1)是Spring的注解,可以指定前置拦截器的执行顺序,数字越小越优先执行。 |
| 3 | LoggerPreInterceptor必须实现CommandInterceptorI接口。 |
2.定义了一个后置命令拦截器
@Order(100)
@PostInterceptor (1)
public class LoggerPostInterceptor implements CommandInterceptorI{
Logger logger = LoggerFactory.getLogger(LoggerPostInterceptor.class);
@Autowired
private LoggerPreInterceptor logPreInterceptor;
@Override
public void postIntercept(Command command, Response response) {
logger.debug("Finished processing %s Response:%s", command.getClass(), response);
//记录监控日志
handleMonitorLog(command, response);
}
private void handleMonitorLog(Command command, Response response){
Thread th = Thread.currentThread();
boolean status = false;
Long threadId = 0L;
if(th != null){
threadId = th.getId();
}
//操作人
String operator = StringUtils.EMPTY;
//处理状态
if(response != null && response.isSuccess()){
status = true;
}
Boolean cacheEnabled = false;
String params = StringUtils.EMPTY;
if(!status){
params = command.toString();
}
//status=true 情况下默认关闭参数输出
else if(cacheEnabled != null && cacheEnabled){
params = command.toString();
}
//毫秒
long cost = System.currentTimeMillis() - logPreInterceptor.getStartTime();
//|threadId|Command|操作人|处理状态|耗时|ip|params
logger.info("[MonitorLog] |%s|%s|%s|%s|%s|%s", threadId, command.getClass(), operator, status, cost, params);
}
}| 1 | @PostInterceptor是后置命令拦截器注解 |
20.4.1. 命令拦截器Filter
通过命令拦截器注解的cmdFilterList字段,可以配置该拦截器只拦截指定的命令类型,以便缩小拦截范围,实现对特殊类型命令的拦截。 该字段适用于@PreInterceptor,@PostInterceptor。
通过cmdFilterList字段指定的期望拦截命令类型,必须是目标命令类型及其子类。否则,Halo应用启动时会进行check出现报错提示。
指定后,只有指定的命令类型及其子类会被拦截,其它命令不会被拦截。
使用示例:
@PreInterceptor(
cmdFilterList = DeleteAppCmd.class (2)
)
public class LoggerPreInterceptor implements CommandInterceptorI<Command> { (1)
@Override
public void preIntercept(Command command) {
log.info("before process DeleteAppCmd");
}
}| 1 | Command:目标命令类型。 |
| 2 | DeleteAppCmd.class:需要拦截的命令类型,该类型必须是需要拦截的命令类型或其子类,即DeleteAppCmd及其子类都会该拦截器被拦截。 |
20.5. Command对象
20.5.1. 什么是Command对象
Command对象的作用是用来封装命令数据,所以这类对象以属性为主,少量简单方法。但注意这些方法中不能包含业务逻辑。 在Halo框架中我们高度抽象了一个Command对象继承了DTO。代码如下所示:
public abstract class Command extends DTO{
private static final long serialVersionUID = 1L;
private Context context;
public Context getContext() {
return context;
}
public void setContext(Context context) {
this.context = context;
}
}Halo框架中的Command继承了DTO,里面有一个属性为Context context,主要用于统一传递命令需要的上下文,比如业务身份,或者其它业务参数。
实际项目开发中,会创建一个CommonCommand,由于承载共用的属性,示例CommonCommand如下所示:
public class CommonCommand extends Command {
private String operater;
private boolean needsOperator;
public String getOperater() {
return this.operater;
}
public void setOperater(String operater) {
this.operater = operater;
needsOperator = true;
}
public boolean isNeedsOperator(){
return needsOperator;
}
}20.6. Command Bus
Command Bus 就是一个命令执行总线。执行Command的是命令执行器,但CommandExecutor的调用不是通过在用户界面层直接依赖注入调用, 会把所有请求转变为Command对象,然后把它放入到CommandBus中即可。Command Bus的作用是将一个Command分发给对应的CommandExecutor 去执行,如下图所示。CommandBus的出现提供统一的编程入口,开发不需要关心Command会被哪个Executor执行,Commandbus屏蔽了底层的细节。 让分工协作开发更加独立明确。
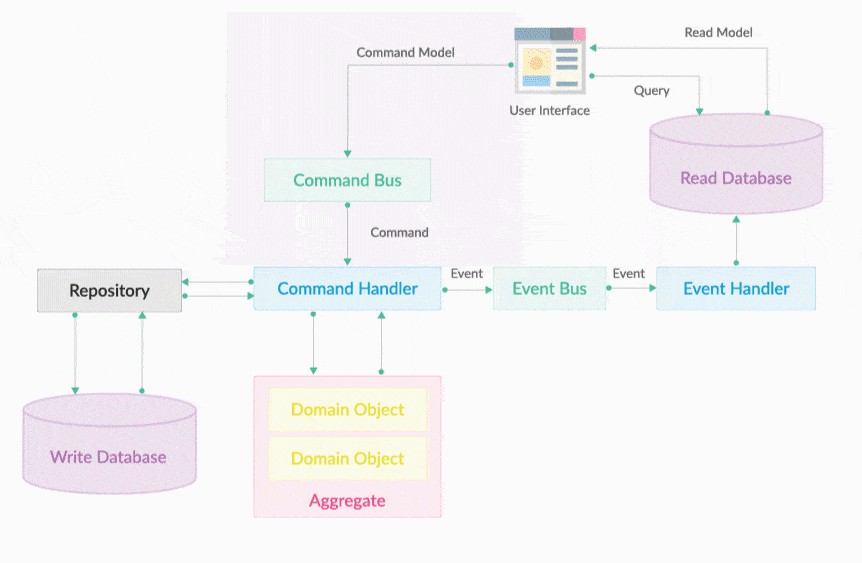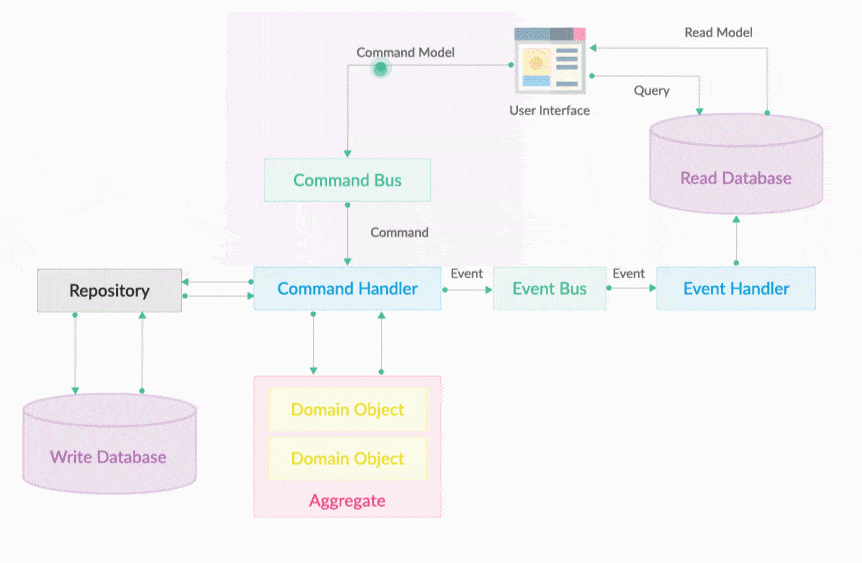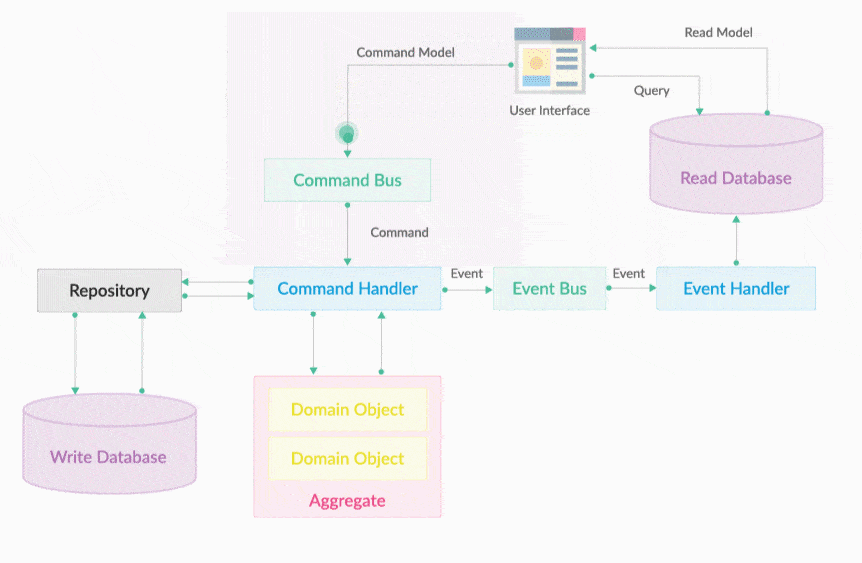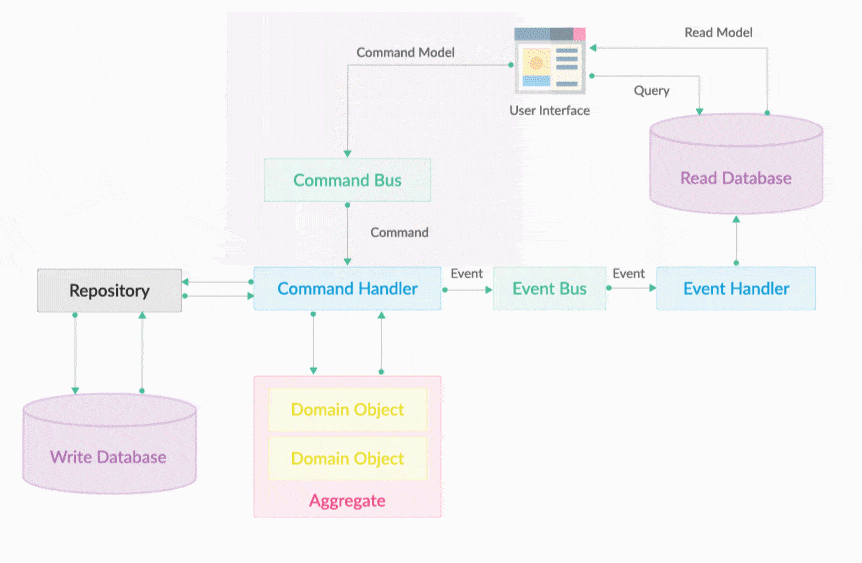
20.6.1. Command Bus发送命令对象
在Controller中Command Bus分发命令的示例代码如下所示:
@RestController
@RequestMapping("/admin/app")
@Api(description = "应用管理")
public class AppController {
@Autowired
private CommandBus commandBus; (1)
@PostMapping("")
@ApiOperation(value = "增加应用")
public ResultData<Long> addApp(@RequestBody AddAppCmd addAppCmd) {
return commandBus.send(addAppCmd); (2)
}
}| 1 | 在应用层,依赖注入CommandBus |
| 2 | commandBus.send发送命令对象 |
| 在上述代码中,从Controller进来的请求统一为命令,只将命令扔到CommandBus中即可。 |
20.6.2. Command Bus发送命令执行器
在Controller中发送命令执行器的代码,如下所示:
/**
* 查询域树型结构
* @return
*/
@GetMapping("/domain/queryAllDomain")
public ResultData<List<DomainCO>> getAllDomain() {
return commandBus.send(QueryIdeaDomainListCmdExe.class); (1)
}| 1 | 其中commandBus.send(QueryIdeaDomainListCmdExe.class)发送的就是命令执行器,当命令中没有入参的时候,可以直接发送命令执行器。 |
20.7. Command执行器
CommandExecutor就是一个命令执行器,它的作用是执行一个命令。CommandExecutor中主要有两部分工作,分别是
-
一是验证传入的Command对象是否合法,
-
二是调用领域服务完成操作。Command和CommandExecutor是一一对应的。
也就是说,一个Command只会对应一个CommandExecutor。
20.7.1. 有入参的Command执行器
下面是增加一个App的命令,代码如下所示:
public class AddAppCmdExe implements CommandExecutorI<ResultData<Long>, AddAppCmd>{ (1)
@Autowired
AppService appService; (2)
@Autowired
AppClientConvertor appClientConvertor; (3)
@Override
public ResultData<Long> execute(AddAppCmd addAppCmd) {
AppE appE = appClientConvertor.clientToEntity(addAppCmd);(4)
ResultData<Long> resultData = ResultData.builder(null);
if (!check(appE, resultData)) {
return resultData;
}
try {
appE.save();
resultData.setData(appE.getId());
} catch (Exception ex) {
log.error(String.format("add app failed, appE=%s", appE), ex);
resultData.setSuccess(false);
resultData.setCode(500);
resultData.setMsgContent("添加失败");
}
return resultData;
}
protected boolean check(AppE appE, ResultData<Long> resultData) { (5)
try {
Preconditions.checkNotNull(appE, "appE不能为null");
Preconditions.checkArgument(!appService.containsAppId(appE.getAppId()), "appId不能重复");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getAppId()), "appId不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getName()), "name不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getOwnerName()), "ownerName不能为空");
Preconditions.checkNotNull(appE.getOwnerId(), "ownerId不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getDescription()), "description不能为空");
Preconditions.checkArgument(StringUtils.isNotEmpty(appE.getSpringApplicationName()), "springApplicationName不能为空");
} catch (Exception ex) {
resultData.setSuccess(false);
resultData.setMsgContent(ex.getMessage());
return false;
}
return true;
}
}以下介绍命令执行器的注意事项:
| 1 | AddAppCmdExe需要实现CommandExecutorI接口,其中CommandExecutorI<ResultData<Long>, AddAppCmd>的ResultData<Long>是命令返回的结果,AddAppCmd是命令对象。 |
| 2 | appService是示例的领域服务 |
| 3 | appClientConvertor是转换防腐层,从App层进入Domain层需要转换防腐。 |
| 4 | 把客户端对象转换为实体 |
| 5 | 验证传入的addAppCmd命令对象是否合法 |
20.7.2. 无入参的Command执行器
在Halo中一切请求皆为命令,但是有些命令没有入参,Halo提供统一的编程方式解决。命令执行器只需实现CommandExecutorWithoutInputI接口即可。
@CmdHandler
public class QueryAllMenuCmdExe implements CommandExecutorWithoutInputI<ResultData<List<UserMenuCO>>> { (1)
@Autowired
private MenuMapper menuMapper;
@Autowired
private MenuClientConverter menuClientConverter;
@Override
public ResultData<List<UserMenuCO>> execute() {
List<MenuDO> allMenu = menuMapper.getAllMenu();
List<UserMenuCO> allMenus = menuClientConverter.dataToClient(allMenu);
return ResultData.success(allMenus);
}
}以下介绍无入参命令执行器的注意事项:
| 1 | QueryAllMenuCmdExe需要实现CommandExecutorWithoutInputI接口, 其中CommandExecutorWithoutInputI<ResultData<List<UserMenuCO>>>的ResultData<List<UserMenuCO>>是命令返回的结果。 |
20.8. Command执行结果
命令执行器会执行命令,经过一系列的命令处理之后,会返回的命令处理结果。Halo框架为了统一规范,对返回的命令处理结果进行封装处理,目前支持不带返回值的Response 和支持ResultData泛型支持。如果需要定义返回结果的包装类型,类似默认ResultData的实现需要继承Response。
/**
* 统一的结果返回包装类型
* @author xujin
*/
@Builder
public class ResultData <T> extends Response {
@Tolerate
public ResultData(){}
/** 返回的数据 **/
private T data;
public static <T> ResultData<T> builder(T data) {
ResultData<T> resultData= new ResultData();
resultData.setData(data);
return resultData;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}20.9. Event
领域事件是最近几年才加入DDD生态系统的,通过领域事件的方式达到各个组件之间的数据一致性。领域事件的额外好处在于它可以记录发生 在软件系统中所有的重要修改,这样可以很好地支持程序调试和商业智能化。
在CQRS架构的软件系统中,领域事件还用于写模型和读模型之间的数据同步,或者异步处理。
20.9.1. Event Bus
EventBus是Java的发布/订阅事件总线。Event Bus将事件发送者和接收处理者分离。EventBus提供两个方法来发布事件。
public interface EventBus {
/**
* Send event to EventBus to publish all corresponding handlers synchronously
* 同步:发送事件到事件总线,触发相应的事件处理器
*
* @param event 事件
*/
public void publishEvent(Event event); (1)
/**
* Send event to EventBus to publish all corresponding handlers asynchronously
* 异步:发送事件到事件总线,触发相应的事件处理器
*
* @param event 事件
*/
public void asyncPublishEvent(Event event); (2)
}| 1 | 单线程同步事件消费, |
| 2 | 异步事件消费 |
20.9.2. 同步事件处理
通过EventBus的publishEvent方法,同步发送事件,EventBus会逐个遍历该事件的所有处理器,并在当前线程中执行。
| 由于事件发布方只负责产生事件,并不关心事件订阅方如何处理该事件,因此,publishEvent方法不会抛出订阅方处理事件时产生的异常, 但会把异常信息记录到error日志。 |
在实现事件处理器时,由开发人员自行捕获异常,以保证事件处理器执行逻辑。
20.9.3. 异步事件处理
异步发送事件可以通过EventBus的asyncPublishEvent方法,EventBus会将该事件的所有处理器提交到线程池中执行,asyncPublishEvent会在调用后立即返回。 使用方如果没有定义线程池,会使用Halo框架为EventBus提供的默认线程池,也就是说所有事件处理程序都会提交到Halo Event中默认的线程池中执行,
-
Halo Event默认线程池设计
@PostConstruct
public void init() {
defaultHandlerExeThreadPoll = new ThreadPoolExecutor(0,
Runtime.getRuntime().availableProcessors() + 1,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000), (1)
new ThreadFactoryBuilder().setNameFormat("event-bus-pool-%d").build());
}| 1 | 该线程池默认使用长度为1000的有界阻塞队列(BlockingQueue),如果某些事件处理程序比较耗时,在异步事件发送量比较大时, 会造成队列溢出的情况。 |
在线程池满的时候,新产生的异步事件无法提交到默认线程池中,会产生RejectedExecutionException异常。 为保证业务正常执行,该异常由EventBus捕获,并把异常信息记录到error日志。
-
Halo Event Handler提供可定制线程池接口
为满足使用方线程池自定义需求以及防止出现有界队列溢出,在事件处理器接口(EventHandlerI)中增加了定制线程池方法 (org.xujin.halo.event.EventHandlerI#getExecutor),代码如下所示:
public interface EventHandlerI<R extends Response, E extends Event> {
/**
* 使用方可以根据自己的业务使用场景,可定制线程池来处理
* @return
*/
default public ExecutorService getExecutor(){
return null;
}
public R execute(E e);
}通过该方法,开发人员可以为事件处理程序提供专用的线程池,以做到事件处理之间的隔离。如果开发人员为事件处理器实现了该方法, EventBus会用指定的线程池,否则,使用默认线程池。
|
需要注意的是事件对象和事件处理器之间的1对N关系,不要太多,尽量控制一定数量。 |
20.9.4. Event对象
在 Halo Framework中,发布事件到Event Bus时,需要构建事件对象,事件对象本质是一个DTO
@Data
@Accessors(chain = true)
public class CreateUserRoleEvent extends Event { (1)
private String userName;
private String role;
}| 1 | CreateUserRoleEvent继承Event是一个创建用户角色的一个事件对象,而其中的属性就是传递的值 |
20.9.5. Event处理器
事件处理器需要实现EventHandlerI接口中execute方法,EventHandlerI<R extends Response, E extends Event>中的R是事件处理的返回值,E是事件对象。
@EventHandler
public class CreateUserRoleEventHandler implements EventHandlerI<Response, CreateUserRoleEvent> {
@Autowired
private UserRoleService userRoleService;
@Override
public Response execute(CreateUserRoleEvent event) {
if (StringUtils.isNotEmpty(event.getRole()) && StringUtils.isNotEmpty(event.getUserName())) {
userRoleService.createUserRole(event.getUserName(), event.getRole());
}
return Response.buildSuccess();
}
}在处理异步事件时,如果需要为该事件处理器提供专用线程池,需要实现EventHandlerI中提供的getExecutor方法, 如下所示:
default public ExecutorService getExecutor(){
return null;
}|
在实现getExecutor方法时,一定要小心线程池资源泄漏,EventBus在将事件处理器提交到线程池时,会调用该方法, 以确定该事件处理器是否有专用线程池。也就意味着,该方法会被反复调用,严禁在该方法中直接new线程池! |
20.9.6. 发送Event事件到Event Bus
我们在使用过程中只需依赖注入EventBus即可,示例发送代码如下所示:
@Autowired
private EventBus eventBus; (1)
CreateUserRoleEvent event = new CreateUserRoleEvent(); (2)
event.setRole("USER");
event.setUserName(userName);
eventBus.asyncPublishEvent(event); (3)| 1 | 依赖注入eventBus |
| 2 | 构建事件对象 |
| 3 | 发布事件 |
21. Halo DDD
Halo DDD是Halo框架根据领域驱动设计的思想,战略设计和战术设计等实战经验,提供的一套方法论,帮助项目或业务中台快速落地DDD.
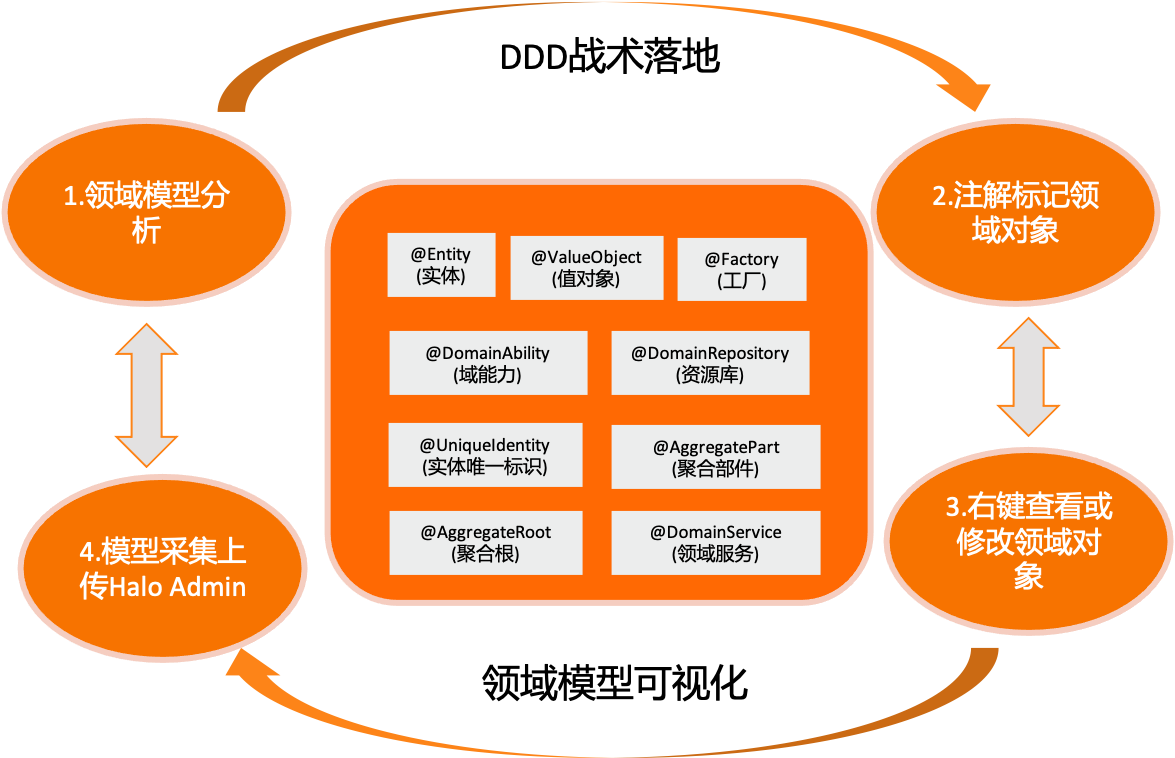
Halo DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。而业务中台或微服务追求业务层面的复用,设计出来的系统架构和业务一致; 在技术架构上则系统模块之间充分解耦,可以自由地选择合适的技术架构,去中心化地治理技术和数据。使用Halo DDD落地思路如下所示:
21.1. 软件的复杂性应对之道
解决复杂和大规模软件的武器可以被粗略地归为三类:抽象、分治和知识。
-
分治 把问题空间分割为规模更小且易于处理的若干子问题。分割后的问题需要足够小,以便一个人单枪匹马就能够解决他们;其次,必须考虑如何将分割后的各个部分装配为整体。分割得越合理越易于理解,在装配成整体时,所需跟踪的细节也就越少。即更容易设计各部分的协作方式。评判什么是分治得好,即高内聚低耦合。
-
抽象 使用抽象能够精简问题空间,而且问题越小越容易理解。举个例子,从北京到上海出差,可以先理解为使用交通工具前往,但不需要一开始就想清楚到底是高铁还是飞机,以及乘客他们需要注意什么。
-
知识 顾名思义,DDD可以认为是知识的一种。
DDD提供了这样的知识手段,让我们知道如何抽象出限界上下文以及如何去分治。
21.2. 企业应用开发范式
在开发企业应用的时候,典型的开发范式基本上可以总结为三种:
-
数据驱动:认为企业应用就是数据的存储和展示。其典型开发方式是“以数据库为中心的增删改查(CRUD)”,或者是Martin Fowler的《企业应用架构模式》中的“表模块”模式。
-
特性驱动:认为企业应用是系统功能的集合,这些功能基本上是独立实现的。其典型的开发方式是Martin Fowler的《企业应用架构模式》中的“事务脚本”模式。
-
领域驱动:认为企业应用像机器一样,由多个具有不同能力的零件(对象)组成,这些零件相互配合实现系统的功能。其典型的开发方式是Martin Fowler的《企业应用架构模式》中的“领域模型”模式。
| 数据驱动 | 特性驱动 | 领域驱动 | |
|---|---|---|---|
软件世界观 |
软件就是数据的存储和展示 软件是功能特性的集合 |
软件是由相互协作的智能零件组成的一台能动的机器 |
核心关注点 |
数据 |
功能特性 |
领域对象 |
核心模型 |
数据模型 /关系模型 |
用例模型 |
领域模型 |
业务逻辑组织典型模式 |
CRUD或表模块 |
事务脚本 |
领域模型 |
业务逻辑实现典型位置 |
数据库、表示层或缺失业务逻辑 |
应用层 |
领域层 |
重用价值 |
低 |
较低 |
高 |
扩展成本 |
极高 |
高 |
低 |
问题域/解决方案域语义距离 |
| 1.在三种开发范式中,数据驱动最差,领域驱动最好,特性驱动介于两者之间。 2.领域驱动的应用开发模式,能解决软件的复杂性问题. 3.很可悲的是:在当前企业应用开发中,数据驱动的CRUD方式占了统治地位。 |
21.2.1. 问题域简介
一个系统(或者一个公司)的业务范围和在这个范围里进行的活动,被称之为领域,领域是现实生活中面对的问题域, 和软件系统无关,领域可以划分为子域,比如电商领域可以划分为商品子域、订单子域、发票子域、库存子域 等, 在不同子域里,不同概念会有不同的含义,所以我们在建模的时候必须要有一个明确的边界, 这个边界在 DDD 中被称之为限界上下文,它是系统架构内部的一个边界。
| 《整洁之道》这本书里提到:系统架构是由系统内部的架构边界,以及边界之间的依赖关系所定义的,与系统中组件之间的 调用方式无关。所谓的服务本身只是一种比函数调用方式成本稍高的,分割应用程序行为的一种形式,与系统架构无关。 |
21.2.2. 数据库驱动范式
数据驱动设计范式的软件世界观认为:软件是用于处理数据的虚拟机器。软件开发的核心关注点应该是数据,软件的设计和构建应该围绕数据的存储、检索和展现来开展。
数据驱动设计范式以数据模型为核心和出发点来进行开发。如果采用关系数据库为数据存储媒介,软件的核心就是关系模型,通常表示为E-R图(实体-关系图)的形式。
数据驱动设计范式认为,对数据只有四种可能的操作:增(Create)、删(Delete)、改(Update)、查(Retrieve),简称CRUD。
21.3. Halo DDD的目标
采用 DDD(领域驱动设计)作为微服务设计指导思想,通过事件风暴建立领域模型,合理划分领域逻辑和物理边界,建立领域对象及服务矩阵和服务架构图, 定义符合 DDD 分层架构思想的代码结构模型,保证业务模型与代码模型的一致性。通过上述设计思想、方法和过程,指导团队按照 DDD 设计思想完成微服 务设计和开发。
通过领域模型和 DDD 的分层思想,屏蔽外部变化对领域逻辑的影响,确保交付的软件产品是边界清晰的微服务,而不是内部边界依然混乱的小单体。 在需求和设计变化时,可以轻松的完成微服务的开发、拆分和组合,确保微服务不易受外部变化的影响,并稳定运行。
21.4. 领域驱动设计
微服务系统的设计自然离不开DDD(Domain-Driven Design),它由Eric Evans提出,是一种全新的系统设计和建模方法。
领域驱动设计事实上是针对面向对象的分析和设计的一个扩展和延伸,对技术架构进行了分层规划,同时对每个类进行了策略和类型的划分。
领域模型是领域驱动的核心。领域模型通过聚合(Aggregate)组织在一起,聚合间有明显的业务边界,这些边界将领域划分为一个个限界上 下文(Bounded Context)。
采用DDD的设计思想,业务逻辑不再集中在几个大型的类上,而是由大量相对小的领域对象(类)组成,这些类具 备自己的状态和行为,每个类是相对完整的独立体,并与现实领域的业务对象映射。领域模型就是由这样许多的细粒度的类组成。基于领域驱动 的设计,保证了系统的可维护 性、扩展性和复用性,在处理复杂业务逻辑方面有着先天的优势。
21.5. Halo DDD中的注解
Halo中的DDD,通过注解的方式对Domain层类的定义进行打标记,主要的注解如下所示:
| 分类 | 说明 | 备注 |
|---|---|---|
领域 |
切分的服务。领域就是范围。范围的重点是边界。领域的核心思想是将问题逐级细分来减低业务和系统的复杂度,这也是 DDD 讨论的核心 |
|
子域 |
映射概念:子服务。领域可以进一步划分成子领域,即子域。这是处理高度复杂领域的设计思想,它试图分离技术实现的复杂性。 |
|
核心域 |
核心服务,在领域划分过程中,会不断划分子域,子域按重要程度会被划分成三类:核心域、通用域、支撑域。决定产品核心竞争力的子域就是核心域,没有太多个性化诉求 |
桃树的例子,有根、茎、叶、花、果、种子等六个子域,不同人理解的核心域不同,比如在果园里,核心域就是果是核心域,在公园里,核心域则是花。有时为了核心域的营养供应,还会剪掉通用域和支撑域(茎、叶等)。 |
通用域 |
映射概念:中间件服务或第三方服务。被多个子域使用的通用功能就是通用域,没有太多企业特征,比如权限认证 |
|
支撑域 |
映射概念:企业公共服务。对于功能来讲是必须存在的,但它不对产品核心竞争力产生影响,也不包含通用功能,有企业特征,不具有通用性,比如数据代码类的数字字典系统。 |
|
统一语言 |
映射概念:统一概念。 |
|
限界上下文 |
映射概念:服务职责划分的边界。定义上下文的边界。领域模型存在边界之内。对于同一个概念,不同上下文会有不同的理解,比如商品,在销售阶段叫商品,在运输阶段就叫货品。 |
|
实体 |
被@Entity注解标记的类 |
表示实体 |
值对象 |
被@ValueObject注解标记的类 |
值对象 |
聚合根 |
被@AggregateRoot注解标记的类 |
代表是聚合根 |
聚合部分 |
被@AggregatePart注解标记的类 |
表示参与聚合的部分 |
资源库 |
被@DomainRepository注解标记的类 |
表示资源库 |
工厂 |
被@Factory标记的类 |
表示工厂 |
领域服务 |
被@DomainService标记的类 |
表示领域服务 |
领域能力 |
被@DomainAbility标记的方法 |
在实体或者值对象中被@DomainAbility标记的方法表示领域能力 |
21.6. 领域对象
领域对象区分实体(Entity)和值对象(Value Object),下面介绍一下实体和值对象。
21.6.1. 实体
实体(Entity):实体就是领域中需要唯一标识的领域概念。因为我们有时需要区分是哪个实体。有两个实体,如果唯一标识不一样, 那么即便实体的其他所有属性都一样,我们也认为它们两个是不同的实体;因为实体有生命周期,实体从被创建后可能会被持久化到数 据库,然后某个时候又会被取出来。所以,如果我们不为实体定义一种可以唯一区分的标识,那我们就无法区分到底是这个实体还是那个实体。
另外,不应该给实体定义太多的属性或行为,而应该寻找关联,发现其他一些实体或值对象,将属性或行为转移到其他关联的实体或值对象上。 比如Customer实体,他有一些地址信息,由于地址信息是一个完整的有业务含义的概念,所以,我们可以定义一个Address对象,然后把 Customer的地址相关的信息转移到Address对象上。如果没有Address对象,而把这些地址信息直接放在Customer对象上,并且如果 对于一些其他的类似Address的信息也都直接放在Customer上,会导致Customer对象很混乱,结构不清晰,最终导致它难以维护和理解。
| 使用@Entity注解标记一个类是一个实体。 |
@Entity
public class CampaignE {
/**
* 营销渠道ID
*/
private String channelId;
/**
* 渠道类型
*/
private String channelType;
/**
* 活动名字
*/
private String name;
/**
* 活动描述
*/
private String description;
/**
* 活动开始时间
*/
private CampaignTimerV startTime;
/**
* 活动选择的模板Id
*/
private String templateId;
/**
* 活动反馈
*/
private CampaignFeedbackE campaignFeedback;
private CampaignRepository campaignRepository;
private MailChannelRepository mailChannelRepository;
/**
* 做营销活动
*/
@DomainAbility
public void doCampaign() {
//代码省略
}
/**
* 活动开始
*/
@DomainAbility
public void start(){
if(!isEnabled){
return;
}
this.campaignState = CampaignState.RUNNING;
this.setModifier("message");
campaignRepository.save(this);
//更新定时器
startTime.setFire(true);
startTime.setFireTime(new Date());
campaignRepository.updateTimerMsgStatus(this.id, startTime);
}
/**
* 活动结束
*/
@DomainAbility
public void finish(){
//省略代码
}
/**
* 活动生效
*/
@DomainAbility
public void enable(){
//省略代码
}
/**
* 取消活动
*/
@DomainAbility
public void disable(){
//省略代码
}
/**
* 移除活动
*/
@DomainAbility
public void remove(){
//省略代码
}
/**
* 更新活动
*/
@DomainAbility
public void update(){
//省略其它
campaignRepository.save(this);
}
}| 领域对象具有了行为,对象更加丰满。同时比起将这些逻辑写在服务内(例如 Service),领域功能的内聚性更强, 职责更加明确。 |
21.6.2. 值对象
在领域中,并不是每一个事物都必须有一个唯一标识,也就是说我们不关心对象是哪个,而只关心对象是什么。以对象Address 为例,如果有两个Customer的地址信息是一样的,我们就会认为这两个Customer的地址是同一个。也就是说只要地址信息一样,我们就认为 是同一个地址。
用程序的方式来表达就是,如果两个对象的所有的属性的值都相同,我们会认为它们是同一个对象的话,那么我们就可以把这种对象设计为值对象。 因此,值对象没有唯一标识,这是它和实体的最大不同。
实体和值对象的对比如下表所示:
| 概念 | 区别 | 举例说明 | |
|---|---|---|---|
实体 |
实体表示那些具有生命周期并且会在其生命周期中发生改变的东西 |
实体是有唯一标识的,只要唯一标识不同就是两个不同的实体 |
比如:央行发行了一些100元的钞票,每个钞票都有唯一识别的标识,此时两张100元的钞票就是不同的实体。 |
值对象 |
值对象则表示起描述性作用的并且可以相互替换的概念 |
值对象是没有唯一标识的,只是数据传输的载体。描述性属性字段来实现 |
比如:我们花了100元买了一本书,我们只是关心货币的数量而已,而不是关心具体使用了哪一张100元的钞票,即两张100元的钞票是可以互换的,此时的钞票就是值对象 |
值对象带来的价值
在领域驱动设计中,我们提倡的实践是尽量定义值对象来替代基本类型,原因在于基本类型无法体现统一语言中的领域概念 。此外,在多数语言中,我们无法对基本类型做封装,意味着一个领域概念缺乏领域行为来支持。
假设一个实体定义了许多属性,如果这些属性都是基本类型,就会导致与这些属性相关的领域行为都要放到实体中,导致实体的职责变得不够单一。
引入值对象后,情况就不同了,因为我们可以利用合理的职责分配,将这些职责(领域行为)按照内聚性分配到各个值对象中,这个领域模型就能变得协作良好。
21.7. 聚合与聚合根
聚合中可以包含多个实体和值对象,因此聚合也被称为根实体。如下图所示,就是一个聚合,Customer是聚合根也是实体,address是值对象, ContactInfo也是值对象。
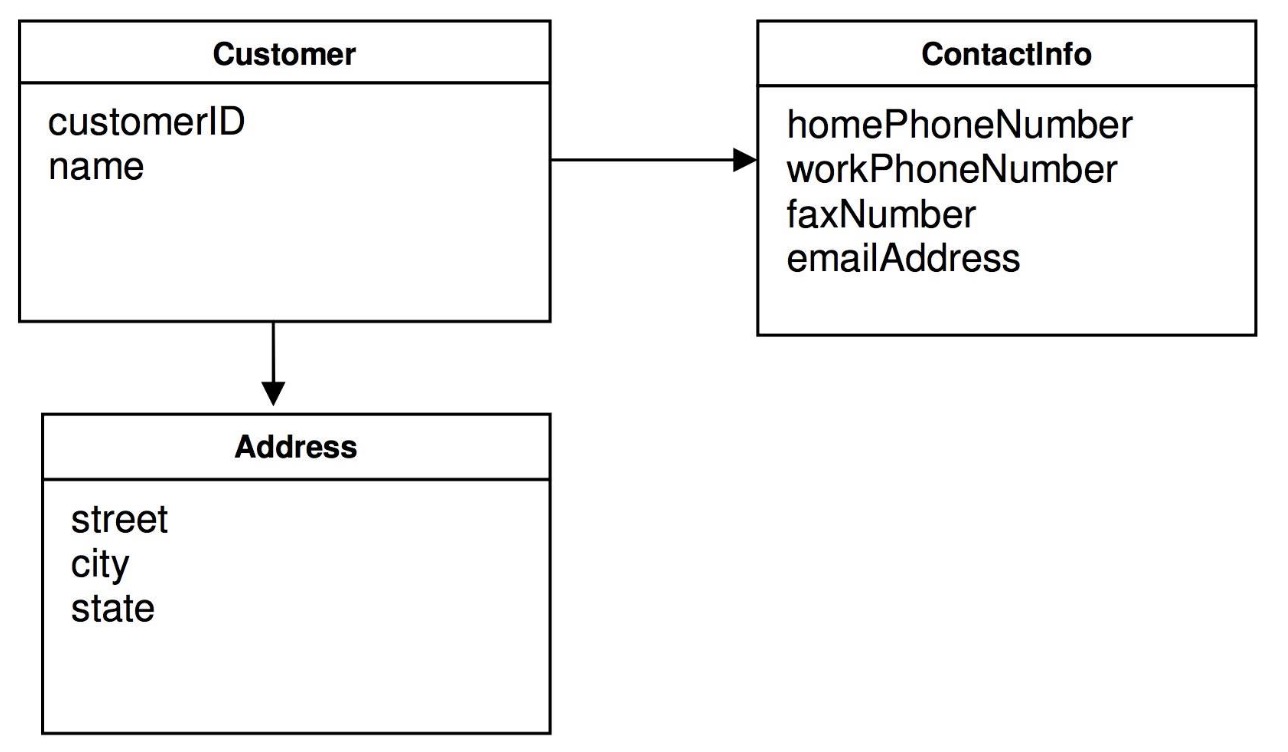
聚合根(Aggregate Root)是DDD中的一个概念,是一种更大范围的封装,把一组有相同生命周期、在业务上不可分隔的实体和值对象放在一起考虑, 只有根实体可以对外暴露引用,也是一种内聚性的表现。
21.9. 工厂
DDD中的工厂也是一种体现封装思想的模式。DDD中引入工厂模式的原因是:有时创建一个领域对象是一件比较复杂的事情,不仅仅是简单的new操作。 正如对象封装了内部实现一样(我们无需知道对象的内部实现就可以使用对象的行为),工厂则是用来封装创建一个复杂对象。工厂的作用是将创建对 象的细节隐藏起来。
工厂在创建一个复杂的领域对象时,通常会知道该满足什么业务规则(它知道先怎样实例化一个对象,然后在对这个对象做哪些初始化操作,这些规则 就是创建对象的细节),如果传递进来的参数符合创建对象的业务规则,则可以顺利创建相应的对象;但是如果由于参数无效等原因不能创建出期望的 对象时,应该抛出一个异常,以确保不会创建出一个错误的对象。
当然也不是所有都需要通过工厂来创建对象,当构造器很简单或者构造对象不依赖于其他对象的创建的时候,我们只需要简单的使用构造函数创建对象就可以。 隐藏创建对象的好处是显而易见的,这样可以不会让领域层的业务逻辑泄露到应用层,同时也减轻了应用层的负担,它只需要简单的调用领域工厂创建符合期 望的对象即可。
| Halo Framework中使用@Factory注解,标记一个类为工厂。 |
21.10. 防腐层
防腐层也被称适配层或者转换层。在一个上下文中,有时需要对外部上下文进行访问, 通常会引入防腐层的概念来对外部上下文的访问进行一次转义。
有以下几种情况会考虑引入防腐层:
-
1.需要将外部上下文中的模型翻译成本上下文理解的模型。
-
2. 不同上下文之间的团队协作关系,如果是供奉者关系,建议引入防腐层,避免外部上下文变化对本上下文的侵蚀。
-
3. 该访问本上下文使用广泛,为了避免改动影响范围过大。
21.11. 领域服务
领域中的一些概念不太适合建模为对象,即归类到实体对象或值对象,因为它们本质上就是一些操作,一些动作,而不是事物。这些操作或动作往往会涉及到 多个领域对象,并且需要协调这些领域对象共同完成这个操作或动作。如果强行将这些操作职责分配给任何一个对象,则被分配的对象就是承担一些不该承担的 职责,从而会导致对象的职责不明确很混乱。但是基于类的面向对象语言规定任何属性或行为都必须放在对象里面。所以我们需要寻找一种新的模式来表示这种 跨多个对象的操作,DDD认为服务是一个很自然的范式用来对应这种跨多个对象的操作,所以就有了领域服务这个模式。领域服务本来就是来处理这种场景的。 比如要对密码进行解密,可以创建一个PasswordService来专门处理加解密的问题。
领域服务还有一个很重要的功能就是可以避免领域逻辑泄露到应用层。因为如果没有领域服务,那么应用层会直接调用领域对象完成本该属于领域服务该做的操作, 这样一来,领域层可能会把一部分领域泄露到应用层。因此,引入领域服务可以有效的防止领域层的逻辑泄露到应用层。对于应用层来说,从可理解的角度来讲, 通过调用领域服务提供的简单,易懂,明确的接口肯定也要比直接操纵领域对象容易的多。
那如何去识别领域服务呢?主要看它是否满足以下三个特征:
-
服务执行的操作代表了一个领域概念,这个领域概念无法自然地隶属于一个实体或者值对象。
-
被执行的操作涉及到领域中的其他的对象。
-
操作是无状态的。
| Halo Framework中使用@DomainService注解,标记一个类为领域服务。将领域行为封装到领域对象中, 将资源管理行为封装到资源库中,将外部上下文的交互行为封装到防腐层中。此时,我们再回过头来看领域服务时, 能够发现领域服务本身所承载的职责也就更加清晰了,即就是通过串联领域对象、资源库和防腐层等一系列领域内的对象的行为, 对其他上下文提供交互的接口。 |
21.12. 应用服务
应用服务:一组面向业务场景的业务外观方法,只是一个对外提供接口、对内分配职责的协作对象,属于应用层。
21.12.1. 应用服务分类
| 分类 | 说明 | 备注 |
|---|---|---|
命令执行器 |
被@CmdHandler注解标记的类 |
命令执行器在App层,主要做入参check和代码逻辑复用编排 |
流程 |
被@Flow注解标记的类 |
流程定义和流程编排 |
节点执行器 |
被@Processor注解标记的类 |
节点的处理器代码,每个节点做对应的代码逻辑处理 |
阶段 |
被@Phase注解标记的类 |
代码逻辑的处理可以拆分为几个阶段,比如检验阶段,组装参数阶段,执行阶段 |
步骤 |
被@Step注解标记的类 |
每个阶段中的代码,又可以拆分为几个步骤,每个步骤可以只做单一的一件事情 |
纯应用服务 |
被@AppService注解标记的类 |
当Command Handler,阶段,步骤都满足不了的情况下,可以使用@AppService标记为一个应用服务 |
21.12.2. @Phase和@Step
阶段或步骤,必须实现org.xujin.halo.command.BaseAppService接口。BaseAppService的代码如下所示:
/**
* 统一的应用服务层服务编写接口
* I是input 输入参数
* O是OutPut 输出参数
* @author xujin
* @param <I>
*/
public interface BaseAppService<I,O> {
/**
* 唯一的方法
* @param input
* @return
*/
O execute(I input);
}示例的Phase如下所示:
package org.xujin.halo.admin.phase;
import org.xujin.halo.annotation.app.Phase;
import org.xujin.halo.command.BaseAppService;
@Phase
public class OnSaleContextInitPhase implements BaseAppService<String,String> {
@Override
public String execute(String input) {
return null;
}
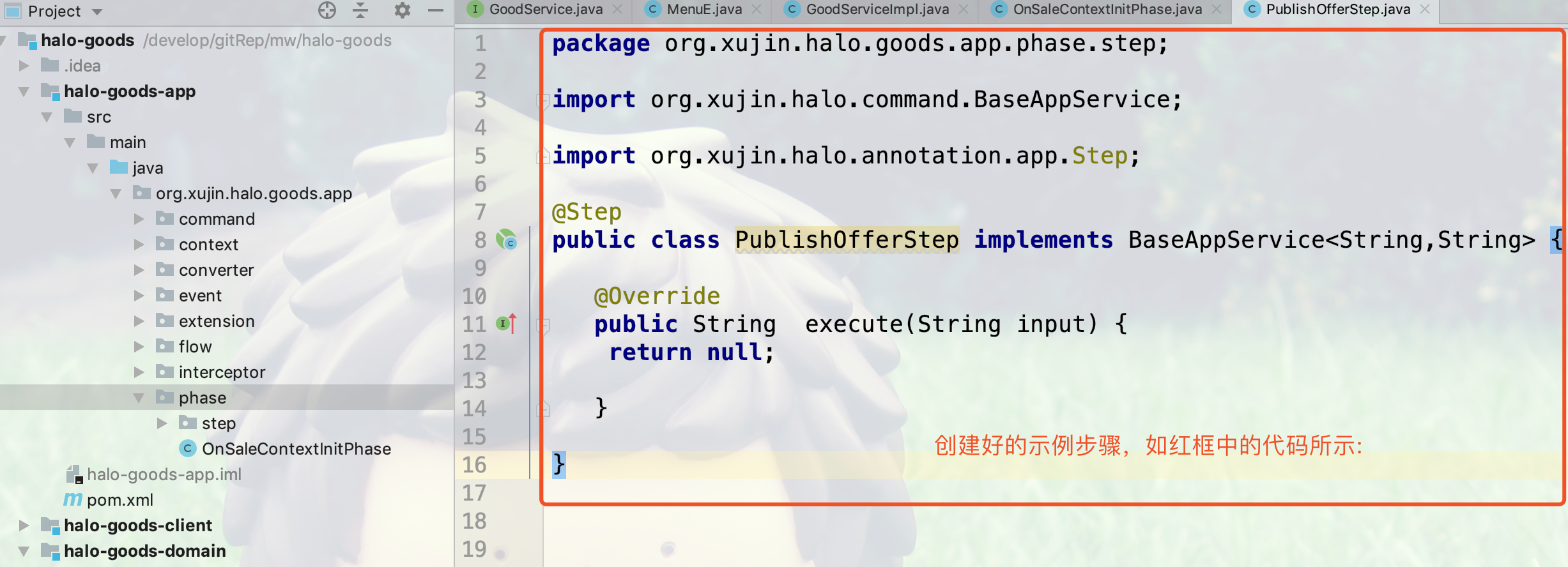
}示例的Step如下所示:
package org.xujin.halo.admin.phase.step;
import org.xujin.halo.annotation.app.Step;
import org.xujin.halo.command.BaseAppService;
@Step
public class PublishOfferStep implements BaseAppService<String,String> {
@Override
public String execute(String input) {
return null;
}
}21.12.3. @AppService
当应用层中的服务不能用命令执行器,流程的节点处理器,阶段,步骤表示的时候,可以使用@AppService注解标记为一个应用层的服务,并实现BaseAppService接口。 示例代码如下:
package org.xujin.halo.admin.appservice;
import org.xujin.halo.annotation.app.AppService;
import org.xujin.halo.command.BaseAppService;
@AppService
public class UploadFileService implements BaseAppService<String,String> {
@Override
public String execute(String input) {
return null;
}
}21.12.4. 应用服务和领域服务的区别
应用服务与领域服务的区别是什么呢?
应用服务:一组面向业务场景的业务外观方法,只是一个对外提供接口、对内分配职责的协作对象,属于应用层。
| 命令执行器在这里就相当于应用服务 |
领域服务:一个领域服务对应最多一个业务场景,往往需要和聚合、Repository、甚至领域服务一起协作。
| 领域服务或其他领域对象的粒度太细(便于协作、扩展和重用),不利于客户端的调用,基于“最小知识原则”,还是让客户 端少知道这些领域对象协作的知识为好。此时的应用服务更像是对领域对象的一种“编排”。 |
21.12.5. 应用能力下沉
所谓的能力下沉,是指我们不强求一次就能设计出Domain Service或Domain Ability,也不需要强制让把所有的业务功能都放到Domain层,而是采用实用主义的态度, 即只对那些需要在多个场景中需要被复用的能力进行抽象下沉,而不需要复用的,就暂时放在App层的Use Case里就好了。
| Use Case是《架构整洁之道》里面的概念,就是一个Http请求的处理过程,在Halo中就是一个命令的处理过程。 |
通过实践,应用服务,领域服务,领域能力循序渐进的下沉,更适合系统的演进进化。因为我业务模型和业务架构不是一次性设计出来的,而是迭代演化出来的。
-
下沉的过程如下图所示,假设两个use case中,我们发现use case1的Phase3的step1和use case2的Phase1的step2有类似的功能,我们就可以考虑让其下沉到Domain层变为领域服务,从而增加代码的复用性。
-
领域服务,可以下沉为实体或者值对象的能力或行为,即Domain Ability
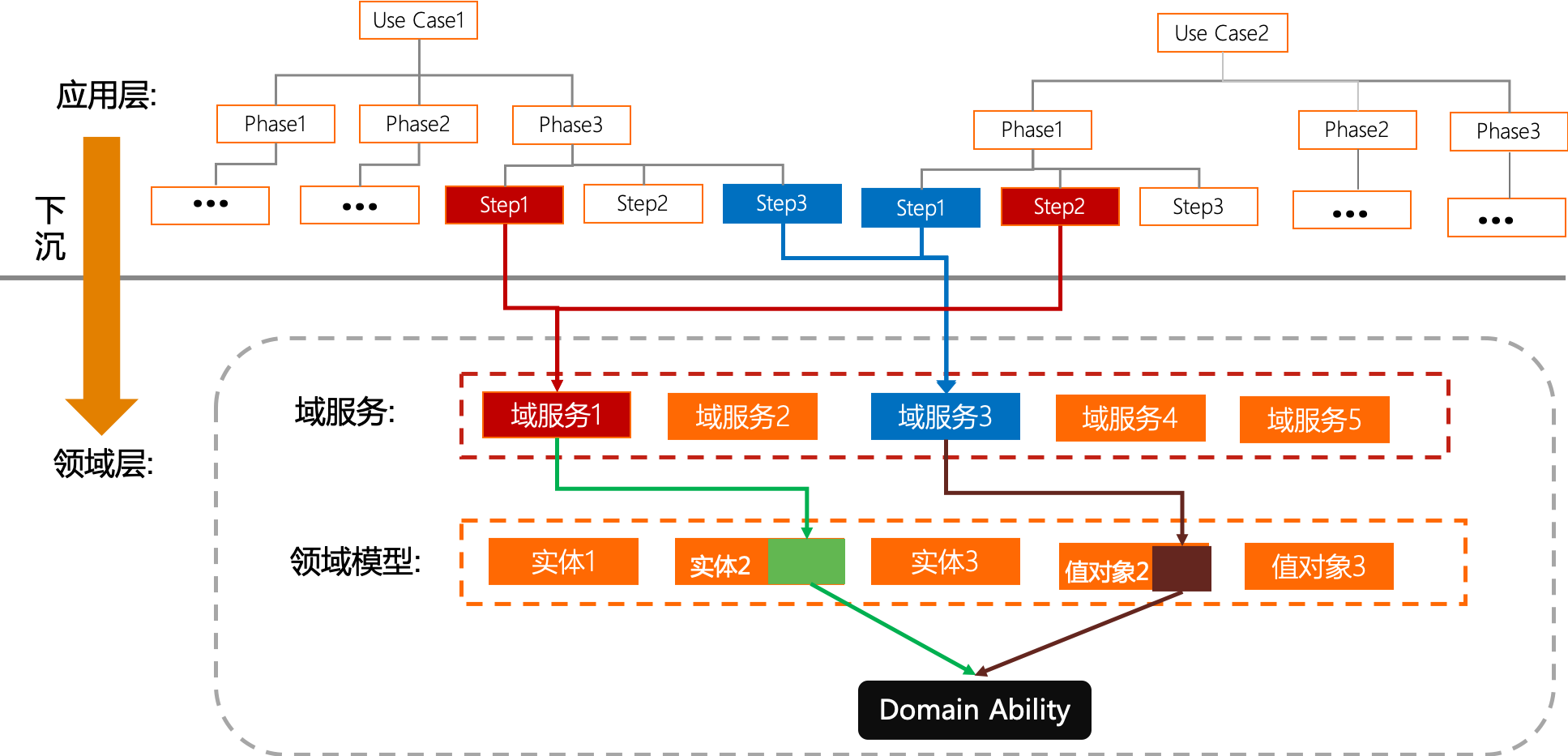
| 应用层的服务可以下沉到领域层成为领域服务,领域服务中方法可以继续沉淀为领域能力。 |
21.13. 领域能力
实体中的方法通过注解@DomainAbility,标识该方法是一个域能力。
/**
* 活动开始
*/
@DomainAbility
public void start(){
if(!isEnabled){
return;
}
this.campaignState = CampaignState.RUNNING;
this.setModifier("message");
campaignRepository.save(this);
startTime.setFireTime(new Date());
campaignRepository.updateTimerMsgStatus(this.id, startTime);
}21.14. 资源库
领域模型中的对象自从被创建出来后不会一直留在内存中活动,当它不活动时会被持久化到数据库中,然后当需要的时候我们会重建该对象;重建对象就是根据数据库 中已存储的对象的状态重新创建对象的过程。所以可见重建对象是一个和数据库打交道的过程。从更广义的角度来理解,我们经常会像集合一样从某个类似集合的地方 根据某个条件获取一个或一些对象,往集合中添加对象或移除对象。也就是说,我们需要提供一种机制,可以提供类似集合的接口来帮助我们管理对象。仓储就是基于 这样的思想被设计出来的。
仓储里面存放的对象一定是聚合,原因是领域模型中是以聚合的概念去划分边界的;聚合是我们更新对象的一个边界,事实上我们把整个聚合看成是一个整体概念,要么 一起被取出来,要么一起被删除。我们永远不会单独对某个聚合内的子对象进行单独查询或做更新操作。因此,我们只对聚合设计仓储。
仓储还有一个重要的特征就是分为仓储定义部分和仓储实现部分,在领域模型中我们定义仓储的接口,而在基础设施层实现具体的仓储。这样设计的原因是:由于仓储背 后的实现都是在和数据库打交道,但是我们又不希望调用方(如应用层)把重点放在如何从数据库获取数据的问题上,因为这样做会导致调用方(应用层)代码很混乱, 很可能会因此而忽略了领域模型的存在。所以我们需要提供一个简单明了的接口,供调用方使用,确保客户能以最简单的方式获取领域对象,从而可以让它专心的不会被什么 数据访问代码打扰的情况下协调领域对象完成业务逻辑。这种通过接口来隔离封装变化的做法其实很常见。由于对外暴露的是抽象的接口并不是具体的实现,所以可以随时替换仓储的真实实现。
| Halo Framework中使用@DomainRepository注解,标记一个类为资源库。 |
在DDD中,所有的领域对象应该都属于领域层。在DDD中需要将领域层和基础设施层解耦,将设计的注意力完全放在领域建模和领域设计上, 思考领域逻辑的实现时,应尽可能地不要考虑领域对象的持久化.于是定义了Repository这个抽象。经过这么一层的抽象之后,获取领域对象, 或者说管理领域对象生命周期的逻辑就应该属于领域层。
21.15. halo DDD实战
领域驱动设计的战略设计阶段是从下面两个方面来考量的:
问题域方面:针对问题域,引入限界上下文(Bounded Context)和上下文映射(Context Map)对问题域进行合理的分解,识别出核心领域(Core Domain)与子领域(SubDomain),并确定领域的边界以及它们之间的关系,维持模型的完整性。
架构方面:通过分层架构来隔离关注点,尤其是将领域实现独立出来,能够更利于领域模型的单一性与稳定性;
CQRS 模式则分离了查询场景和命令场景,针对不同场景选择使用同步或异步操作,来提高架构的低延迟性与高并发能力。
整个软件系统被分解为多个限界上下文(或领域)后,就可以分而治之,对每个限界上下文进行战术设计。 领域驱动设计并不牵涉到技术层面的实现细节,在战术层面,它主要应对的是领域的复杂性。
21.15.1. Halo DDD的模型采集
领域驱动设计的关键在于识别业务的模型,而模型又是会随着业务的发展而演进的。领域模型采集要做到代码即领域模型,领域模型即代码。
-
Halo框架设计了一套领域模型注解提供。用于标记@Entity(实体),@Factory(工厂), @DomainService(领域服务), @AggregateRoot(聚合根), @UniqueIdentity(实体唯一标识),@AggregatePart(聚合部件),@ValueObject(值对象),@DomainRepository(资源库),@DomainAbility(域能力)。
-
当应用启动的时候异步生成领域模型,并上传到Halo Admin或者通过Halo Toolkit右键生成领域模型,最终实时查看战术设计中的领域模型。
-
第一步: 根据战略设计,设计出领域模型。
-
第二步:开发工程师或架构师按照领域设计的原则对业务代码分析并标记相应的注解(可以通过Halo Toolkit实时查看代码生成的领域模型)。
-
第三步:Halo应用启动时自动扫描生成领域模型上传到Halo Admin。
-
第四步:模型采集完毕之后进行版本跟踪,反哺战略设计。
-
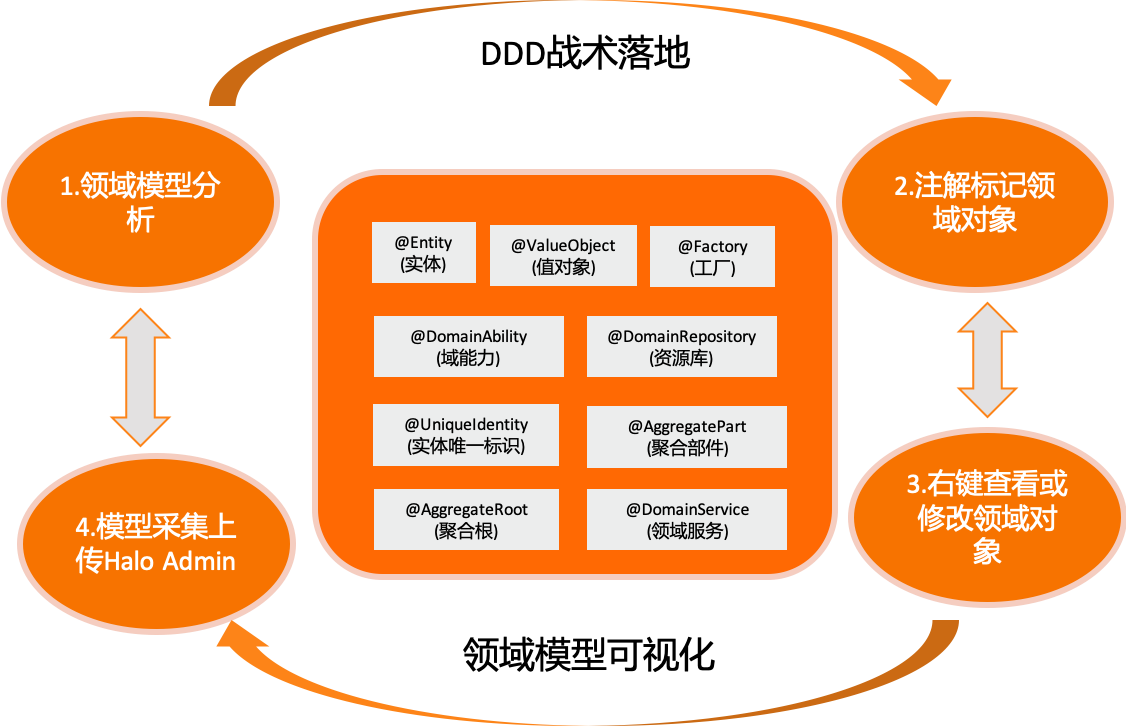
21.15.2. DDD模型要素约定
领域驱动设计用以表示模型的主要要素包括:
-
值对象(Value Object)
-
实体(Entity)
-
领域服务(Domain Service)
-
领域事件(Domain Event)
-
资源库(Repository)
-
工厂(Factory)
-
聚合(Aggregate)
-
应用服务(Application Service)
Eric Evans通过下图勾勒出了战术设计要素之间的关系:
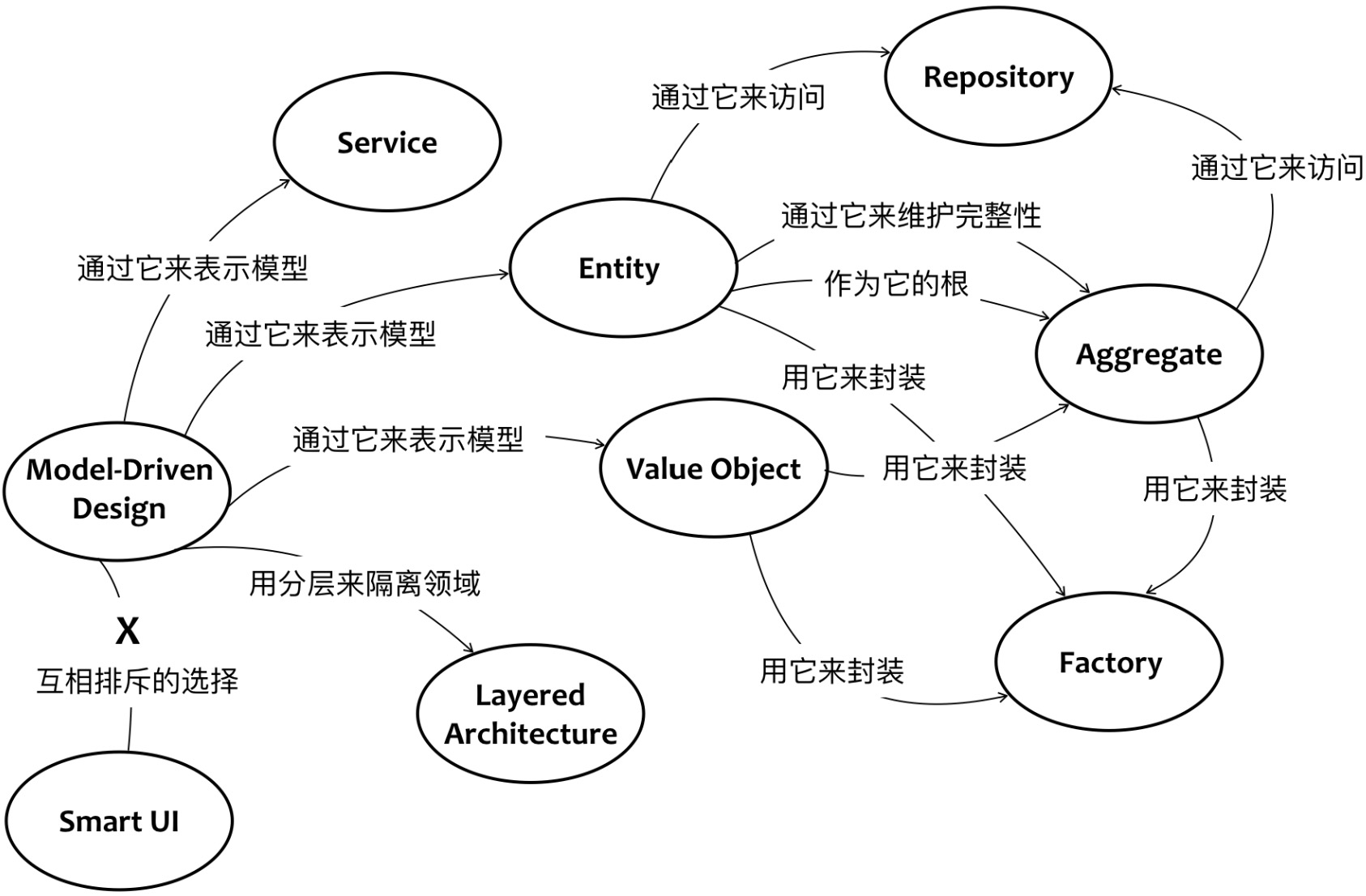
领域驱动设计围绕着领域模型进行设计,
-
通过分层架构(Layered Architecture)将领域隔离。
-
表示领域模型的对象包括:实体、值对象和领域服务,领域逻辑都应该封装在这些对象中。 这一严格的设计原则可以避免业务逻辑渗透到领域层之外,导致技术实现与业务逻辑的混淆。 在领域驱动设计的演进中,又引入了领域事件来丰富领域模型。
-
聚合是一种边界,它可以封装一到多个实体与值对象,并维持该边界范围之内的业务完整性。
-
在聚合中,至少包含一个实体,且只有实体才能作为聚合根(Aggregate Root)。
| 在领域驱动设计中,没有任何一个类是单独的聚合,因为聚合代表的是边界概念,而非领域概念。在极端情况下,一个聚合可能有且只有一个实体。 |
-
工厂和资源库都是对领域对象生命周期的管理。
工厂 负责`领域对象的创建`,往往用于`封装复杂`或者`可能变化的创建逻辑`;
资源库则负责从存放资源的位置(数据库、内存或者其他 Web 资源)获取、添加、删除或者修改领域对象。领域模型中的资源库不应该暴露访问领域对象的技术实现细节。
21.15.3. 运用 Halo DDD改造系统
假如你是一个团队 Leader 或者架构师,当你接手一个旧系统维护及重构的任务时,你该如何改造呢? 是否觉得哪里都不对但由于业务认知的不熟悉而无从下手呢?其实这里我可以教你一套方法来应对这种窘境。
你要做的大概以下几点:
-
1. 通过公共平台大概梳理出系统之间的调用关系(一般中等以上公司都具备 RPC 和 HTTP 调用关系,无脑的挨个系统查询即可), 画出来的可能会很乱,也可能会比较清晰,但这就是现状。
-
2. 分配组员每个人认领几个项目,来梳理项目维度关系,这些关系包括:对外接口、交互、用例、MQ 等的详细说明。个别核心系统可以画出内部实体或者聚合根。
-
3. 小组开会,挨个 review 每个系统的业务概念,达到组内统一语言。
-
4. 根据以上资料,即可看出哪些不合理的调用关系(比如循环调用、不规范的调用等),甚至不合理的分层。
-
5. 根据主线业务自顶向下细分领域,以及限界上下文。此过程可能会颠覆之前的系统划分。
-
6. 根据业务复杂性,指定领域模型,选择贫血或者充血模型。团队内部最好实行统一习惯,以免出现交接成本过大。
-
7. 分工进行开发,并设置 deadline,注意,不要单一的设置一个 deadline,要设置中间 check 时间,比如 dealline 是 1 月 20 日,还要设置两个 check 时间,分别沟通代码风格及边界职责,以免 deadline 时延期。
22. Halo扩展点
22.1. 扩展点出现背景
业务的不断发展、业务类型的不断增多、不断添加的业务需求使得代码出现“bad smell”——平台代码和业务代码耦合严重难以分离;业务和业务之间代码交织缺少拆解——这也是行业中的通病。Halo Framework出现就是为了解决此类问题
Halo Framework为扩展点提供了可视化界面,开发人员可以直观地了解当前各个扩展的的业务身份值。
| 扩展点越少,越意味着“过度耦合”,可能会对后续业务变更无法适应导致主干需要大幅改动。但是扩展点数量也不是,越多越好,因此需要在数量和扩展性之间找到一个平衡。 |
22.1.1. 消灭if-else
-
场景1:如下代码
public void process(OrderDTO orderDTO) {
int serviceType = orderDTO.getServiceType();
if (1 == serviceType) {
System.out.println("取消即时订单");
} else if (2 == serviceType) {
System.out.println("取消预约订单");
} else if (3 == serviceType) {
System.out.println("取消拼车订单");
}
}-
场景2: 例如:接口需要根据 p1、p2、p3、version 多个入参的不同组合按照其对应的业务策略给出结果数据。 由于该接口已经开发了三期了,每次开发新一期的需求时为了兼容老的业务逻辑,大家都倾向于不删不改只新增, 因此这块代码已经产生了一些「坏味道」,函数入口通过不断添加「卫语句」判断 version 的方式跳转到新一期的业务逻辑方法中, 而每一期的业务逻辑也是通过 p1、p2、p3 的 if-else 组合形成不同的分支逻辑。如下图所示:

22.1.2. 多实现执行
if(A类型) {
if(A1类型) {
doSomething1();
}else if(A2类型) {
doSomething2();
}
} else if(B类型) {
doSomething3();
} else if(C类型) {
if(C1类型) {
doSomething4();
}else if(C2类型) {
doSomething5();
}
}类似的代码大家应该都写过不少。逻辑简单的时候写成这样无可厚非,但当逻辑开始变复杂的时候这种写法会具有较多的坏处:
-
难以抽出公共的逻辑,代码块愈发臃肿。
-
有较多相同点少量异同点的新类型的实现很难复用原先的代码。
-
各个类型的代码实际上融合在一块,更改代码可能会影响到其他类型,提高上线风险和测试回归成本。
-
对于新接手的开发人员来说,理解成本高,上手难度大,无形中降低开发效率。
| 上面if else的写法可能有点low,可能大家觉得使用策略模式可以解决上面的问题,因为策略方式是将算法的使用与定义解耦,能够实现根据规则路由到不同策略类进行处理。 实践证明换成策略模式的写法依然会很Low。 |
22.3. 扩展点设计
22.3.1. 扩展点是什么
扩展(Extension)是很多可扩展项目中一个关键的机制,可以利用扩展向平台添加新功能。但是扩展不能随意地创建,必须按照扩展点(Extension Point)定义的规范进行明确的声明,平台才能识别出这些扩展。
所谓扩展点,就是系统定义出来可以让你扩展的地方,可以认为是一些扩展的契约,而扩展,这是你对这些扩展点的实现,当然你自己的插件也可以定义扩展点供别的开发人员扩展。
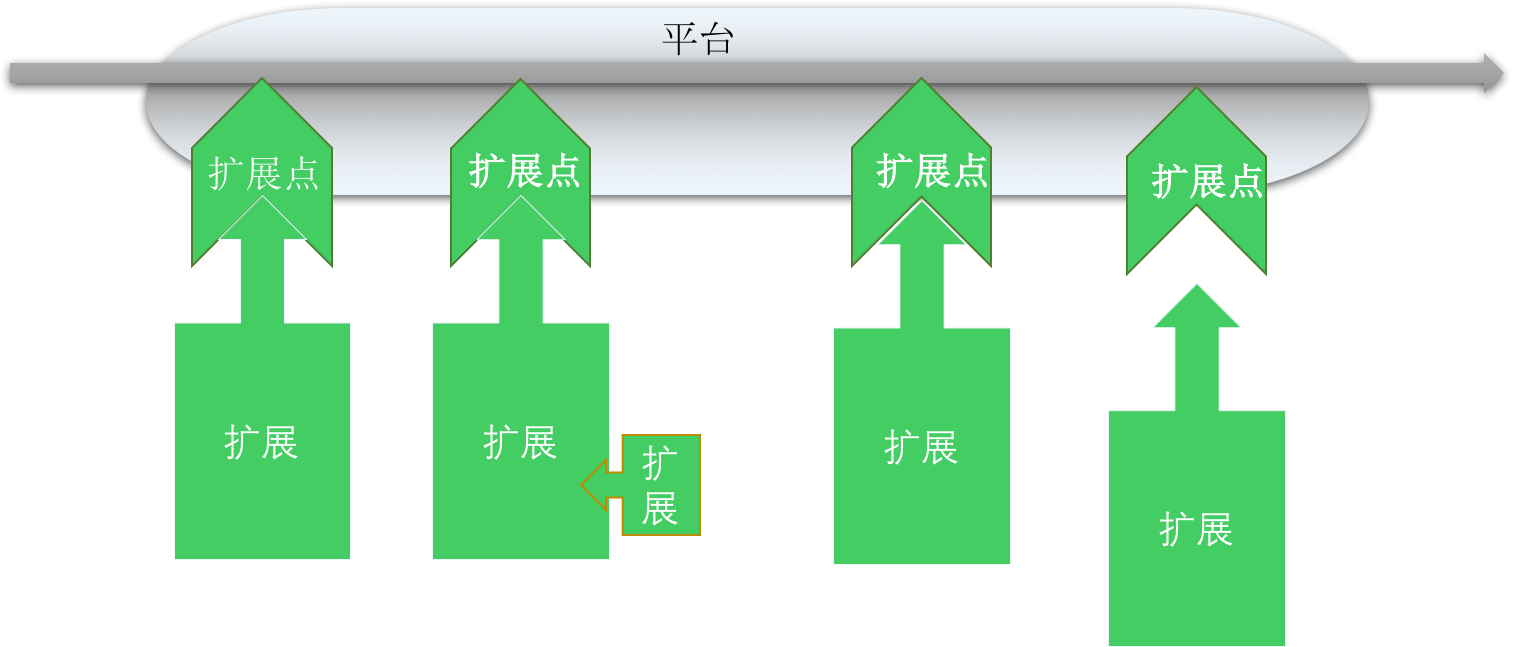
如果开发的功能想要有多种实现方式,而且可以被随便扩展。那就需要中声明一个或一系列的扩展点。 而每个扩展点都要定义一个允许访问的类或接口,Halo框架中推荐定义一个接口。
22.3.2. 扩展是什么
扩展点是一个接口,那么扩展就是接口的实现类。
22.3.3. 扩展点注解
通过自定义注解@ExtensionPoint的方式,标注一个接口是一个扩展点。扩展点的注解如下代码所示。
/**
* 扩展点注解
* @author xujin
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ExtensionPoint {
/**
* 扩展点id
* @return
*/
String id() default "";
/**
* 扩展点名称
* @return
*/
String name();
/**
* 扩展点描述
* @return
*/
String desc();
}| 使用@ExtensionPoint时,其中的name和desc是必须填写的,因为要收集到中台Portal进行统一的管理。 |
22.3.4. 扩展注解
扩展就是接口的实现,Halo框架通过自定义注解@Extension的方式,标注一个接口的实现是一个扩展。 扩展的注解如下代码所示。
/**
* 扩展的注解
* @author xujin
*/
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Target({ElementType.TYPE})
@Component
public @interface Extension {
/**
* 扩展的Id
* @return
*/
String id() default "";
/**
* 扩展的名称
* @return
*/
String name();
/**
* 对应的扩展点Id
* @return
*/
String extensionPointId() default "";
/**
* 扩展对应的描述
* @return
*/
String desc() default "";
/**
* 业务身份
* @return
*/
String bizCode() default CoreConstant.DEFAULT_BIZ_CODE;
}| 使用@Extension时,其中的name和desc是必须填写的,如果bizCode不填代表是默认扩展,如果有多个扩展,需要在扩展上面填写对应的bizCode, 因为要收集到中台Portal进行统一的管理。 |
22.3.5. 业务身份
在扩展点中,引入了业务身份,不同的业务身份走不同的业务扩展,Halo Admin最终会对应用中的业务身份统一管理起来,避免业务身份冲突,调整业务身份执行的优先级. 下面代码中的bizCode = "com.pay.alipay"就是业务身份.
package org.xujin.halo.extension;
import org.xujin.halo.annotation.extension.Extension;
/**
* 支付宝支付扩展
* @author xujin
*/
@Extension(name = "支付包支付扩展", bizCode = "com.pay.alipay",desc = "支付宝支付扩展") (1)
public class AliPayExtension implements PayExtPt {
@Override
public String pay(Object object) {
return "支付包支付扩展";
}
@Override
public void pay() {
}
}| 1 | 其中的bizCode = "com.pay.alipay"是业务身份,业务身份之间用.隔开,一般来说是:一级业务身份.二级业务身份.三级业务身份 |
22.3.6. 提取业务身份
Halo框架扩展点的执行,需要根据业务身份路由到对应的扩展点实现.因此需要提取业务身份.
-
1.上游传递到下游
通过上游调用方,或者前端,APP传递业务身份给下游,比如用户选中支付宝支付,此时传递bizCode=com.pay.alipay到调用端,示例代码如下所示:
@GetMapping("/extensionExe")
public String exeExtension(String bizCode) {
Context context = new Context();
//bizCode可以是前端传递过来的com.pay.alipay
context.setBizCode(bizCode);
String result = extensionExecutor.exeReturnValue(PayExtPt.class, context, extension -> extension.pay(null));
return result;
}-
2.在执行扩展之前通过实现BizCodeParser接口提取
@Component
public class PayMethodBizParser implements BizCodeParser<String> {
@Override
public Context bizCodeParser(String object) {
Context<String> context = new Context<String>();
context.setBizCode("com.pay.alipay");
return context;
}
}| 把提取业务身份的逻辑收拢到统一的地方处理,比如提取不同业务身份写的if-else. |
在需要使用的地方@Autowired注入调用即可.
@Autowired PayMethodBizParser payMethodBizParser
Context context=payMethodBizParser.bizCodeParser("提前业务身份需要传递的参数");
extensionExecutor.exeReturnValue(PayExtPt.class, context, extension -> extension.pay(null));-
3.根据不同的应用Api入口确定,携带对应的业务身份
22.3.7. 减少扩展点数量
共用业务身份减少扩展点
24. 流程编排
24.1. 业务场景
24.1.1. 仓储出库场景
仓储出库场景如下图所示,展示了B2C,O2O,B2B不同形态的业务节点编排:
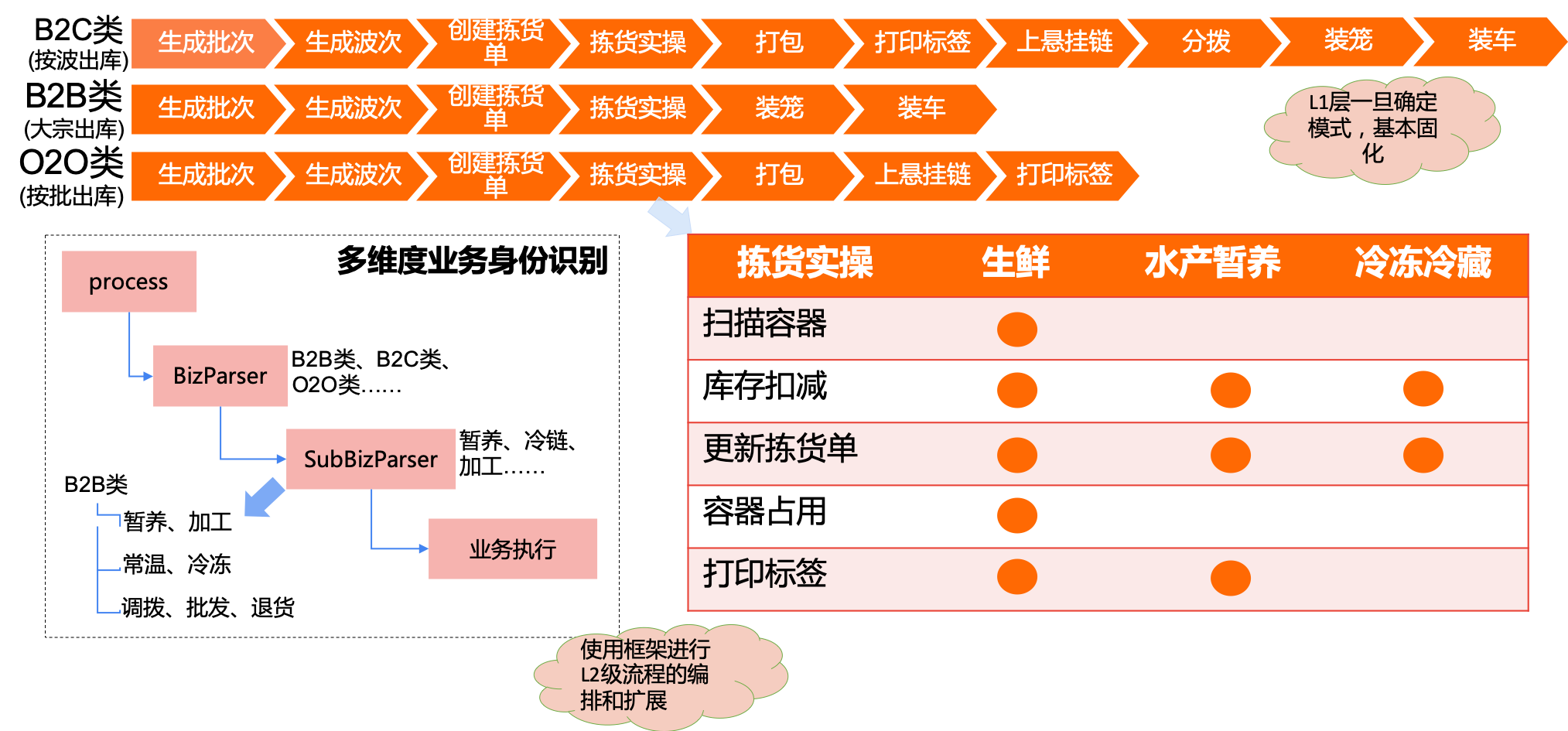
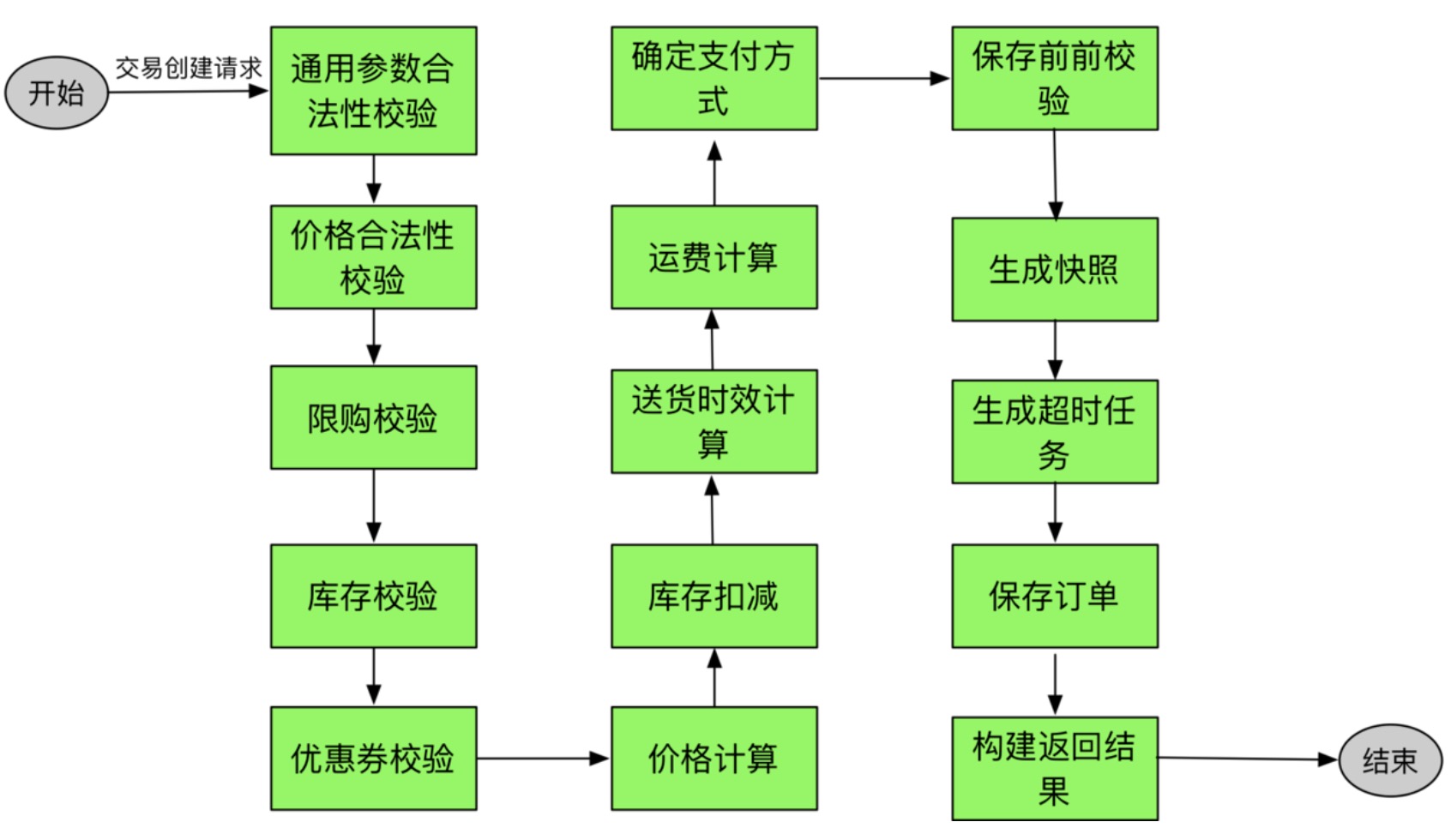
| 如上图所示,不同的业务类型,产生不同的业务流程,不同的业务流程,可能由相同的业务节点组成。 此时就需要流程编排,业务节点资产复用,快速效应不同的业务需求。 |
24.2. 流程编排
当没有流程编排的时候,会出现以下问题
-
代码复用方式千奇百怪,无统一标准。
-
模块划分无章可循。
-
应用日趋复杂
-
流程变更过程冗繁。
| 因为没有流程编排会出现如上的问题,因此组件化需求产生,将代码形成可复用的代码资产。 |
组件化需求
-
一套简单的复用标准。
-
一个简单的模块划分标准。
-
多么复杂多变的业务都可轻松应对。
-
轻量、敏捷、易用。
24.3. 流程编排的关键问题
流程由多个组件或节点组成,下面介绍一下组件或节点相关的概念。
-
如何定义组件? > 我们将一个独立的计算单元称为组件。
-
组件划分的标准是什么? > 一个单一功能即可划归为一个组件。
-
如何进行组件间的数据传输? > 操作和数据分离,数据统一存储,按需存取
-
如何用一种方式标示组件编排顺序?
> 所有操作从开始到结束的实际执行链路展开是一个串行无分叉的链路,但将多种情况的执行链路放在一起却是树状的。所以我们将采用树状存储结构。
24.4. 流程编排设计
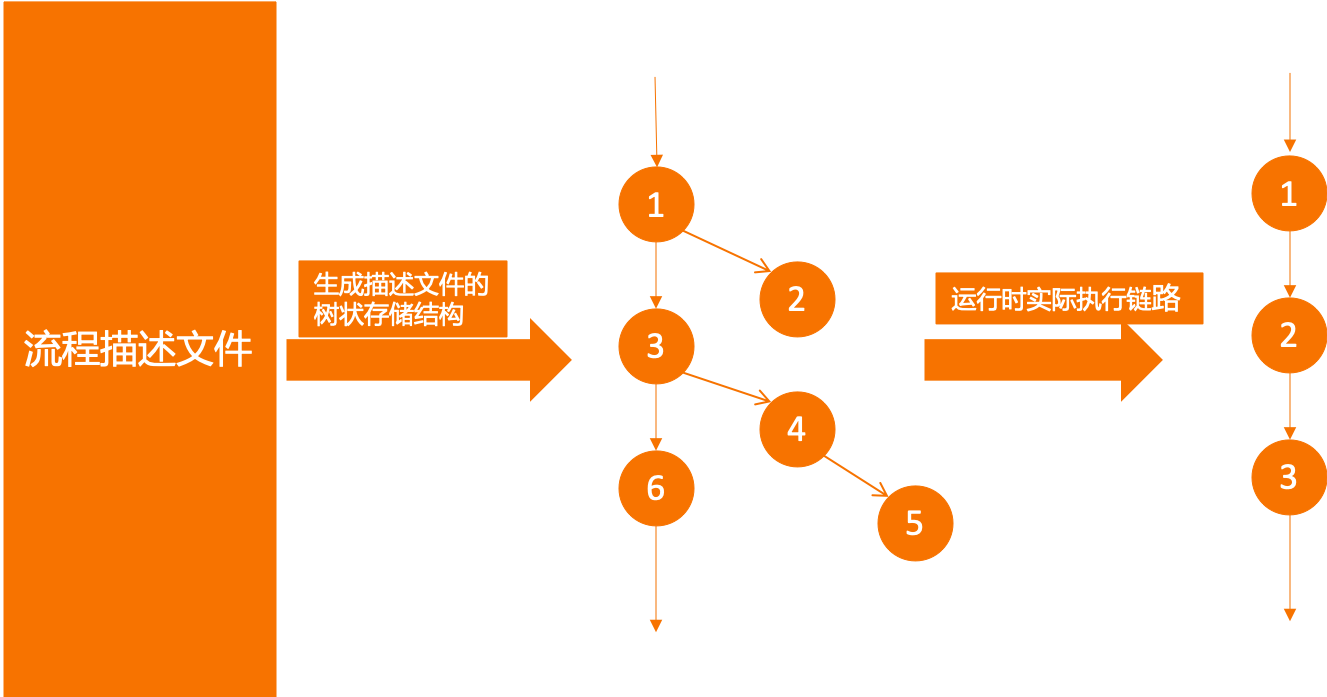
24.4.2. 流程定义
通过自定义注解@Flow实现流程定义。
/**
* B2C出库流程
* @author xujin
*/
@Flow(name = "b2cOutPutFlow", desc = "B2C出库流程") (1)
public class B2cOutPutFlow {
/**
* 开始节点,
* 一个流程必须得有一个开始节点
*
* @return
*/
@StartNode(nextNodeRoute = {@NextNodeRoute(key = "succes", nodeName = "generateBatch")}) (2)
public String start() {
return "succes";
}
/**
* 生成批次
*
* @param processResult
* @return
*/
@ProcessNode(nextNodeRoute = {@NextNodeRoute(key = "succes", nodeName = "generateWave")},
name = "generateBatch", handler = "generateBatchProcessor", desc = "该节点用于生成批次")
public String generateBatch(Boolean processResult) {
return "succes";
}
/**
* 生成波次
*
* @param processResult
* @return
*/
@ProcessNode(nextNodeRoute = {
@NextNodeRoute(key = "succes", nodeName = "createPicking"), (3)
@NextNodeRoute(key = "fail", nodeName = "end")}, (4)
name = "generateWave", (5)
handler = "generateWaveProcessor", (6)
desc = "该节点用于生成波次" (7)
)
public String generateWave(Boolean processResult) { (8)
String nextNodeRouteKey = null;
if (processResult) {
nextNodeRouteKey = "succes"; (9)
} else {
nextNodeRouteKey = "fail"; (10)
}
return nextNodeRouteKey;
}
/**
* 创建拣货单
*
* @param processResult
* @return
*/
@ProcessNode(nextNodeRoute = {@NextNodeRoute(key = "end", nodeName = "end")},
name = "createPicking", handler = "createPickingProcessor", desc = "该节点用于创建拣货单")
public String createPicking(Boolean processResult) {
return "end";
}
/**
* 结束节点
*/
@EndNode
public void end() { (11)
}
}| 1 | 使用@Flow定义流程 |
| 2 | 定义开始节点 |
| 3 | 下一个节点路由映射,其中的key为String,当前节点执行完毕后的判断,nodeName为下一个节点的名称 |
| 4 | 当前节点名称 |
| 5 | 节点描述 |
| 6 | handler = "generateWaveProcessor"当前节点对应的节点处理器,其中generateWaveProcessor为处理器Bean的名称,首字母小写。 |
| 7 | public String generateWave(Boolean processResult)其中processResult是当前节点处理器的返回值 |
| 8 | 根据处理器的返回值判断返回key=succes,执行下一个节点createPicking |
| 9 | 根据处理器的返回值判断返回key=fail,执行结束节点 |
24.4.3. 节点定义
Halo Flow中的Node分为开始节点,执行节点,结束节点,如下表所示
| 节点名称 | 类型 | 描述 |
|---|---|---|
开始节点 |
SN |
使用@StartNode注解标记该节点是一个开始节点 |
执行节点 |
PN |
使用@ProcessNode注解标记该节点是一个执行节点 |
结束节点 |
EN |
使用@EndNode注解标记该节点是一个结束节点 |
24.4.4. 节点异常持久化
当某个节点,出现异常时,需要对异常的执行节点持久化。Halo-flow模块当节点出现异常时会记录相关的数据, 但是默认不开启记录,需要使用方根据实际情况设置开启。
halo:
flow:
persistence: true24.4.5. 启动流程
Halo Flow提供以下两种接口启动流程
public interface FlowEngine {
/**
* 默认从Start节点执行流程
* @param flowName 流程名称
* @param inputData 流程执行入参
* @return FlowHandleContext<T> 流程执行的结果
*/
public <T> FlowHandleContext<T> start(String flowName, T inputData); (1)
/**
* 从指定节点执行流程
*
* @param flowName 流程名称
* @param flowHandleContext 流程执行上下文
* @param nodeName 指定节点名称
* @return FlowHandleContext<T> 流程执行的结果
*/
public <T> FlowHandleContext<T> start(String flowName, FlowHandleContext<T> flowHandleContext, String nodeName); (2)
}| 1 | 该方法默认从开始节点执行,需要输入参数流程名称和流程执行需要的入参 |
| 2 | 该方法使用场景是指定节点执行,此时需要输入流程执行节点需要的上下文 |
在代码中使用示例代码如下:
@Autowired
private FlowEngine flowEngine;
/**
* flowName是流程名称,
**/
flowEngine.start("flowName", inputData);| 流程名称是@Flow(name = "b2cOutPutFlow")注解中的name,Spring Bean的名称首字母小写 |
24.4.6. 流程执行异常处理
流程启动后,在节点执行过程中抛出异常时,Halo Flow会在记录异常信息后,将该异常抛出,交由开发人员处理。
为提高灵活性,在Halo Flow抛出异常时,会通过Throwable.addSuppressed()的方式,把流程执行相关信息附加到原始异常中。流程执行相关信息被封到FlowExecutionException对象,包括流程名称、流程中断时执行节点、流程中断时上下文等。通过Throwable.getSuppressed()方法可以获取到FlowExecutionException对象。
FlowExecutionException代码定义:
public class FlowExecutionException extends Exception {
private static final String MSG_FORMAT = "Halo流程引擎执行流程%s的%s节点时失败";
/**
* 流程名称
*/
private String flowName;
/**
* 当前执行节点名称
*/
private String nodeName;
/**
* 流程执行失败时的上下文信息
*/
private FlowHandleContext context;
public FlowExecutionException(String flowName, String nodeName, FlowHandleContext context) {
super(getMsg(flowName, nodeName));
this.flowName = flowName;
this.nodeName = nodeName;
this.context = context;
}
private static String getMsg(String flowName, String nodeName) {
return String.format(MSG_FORMAT, flowName, nodeName);
}
}24.4.7. 流程事务
Halo Framework中的流程默认开启事务,即整个执行流程开启事务。在使用@Flow进行流程定义的时候默认为true开启事务。
| 如果应用中不需要数据源,即不需要配置事务管理器,使用默认参数启动流程会报错,此时应该将@Flow中enableFlowTx属性置为false。 |
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Component
public @interface Flow {
/**
* 流程名称(默认使用被注解的类名,首字母小写)
*/
String name(); (1)
/**
* 是否开启流程事务(默认开启)
*/
boolean enableFlowTx() default true;
/**
* 指定事务管理器的bean name
* 用于多个数据源情况下,不指定则使用默认事务管理器
*/
String txManager() default "";
/**
* 当前流程的描述
*
* @return
*/
String desc(); (2)
/**
* 流程的唯一Id
*
* @return
*/
String id() default "";
}| ①和②表示流程的名称和描述必填。 |
24.4.8. 节点事务
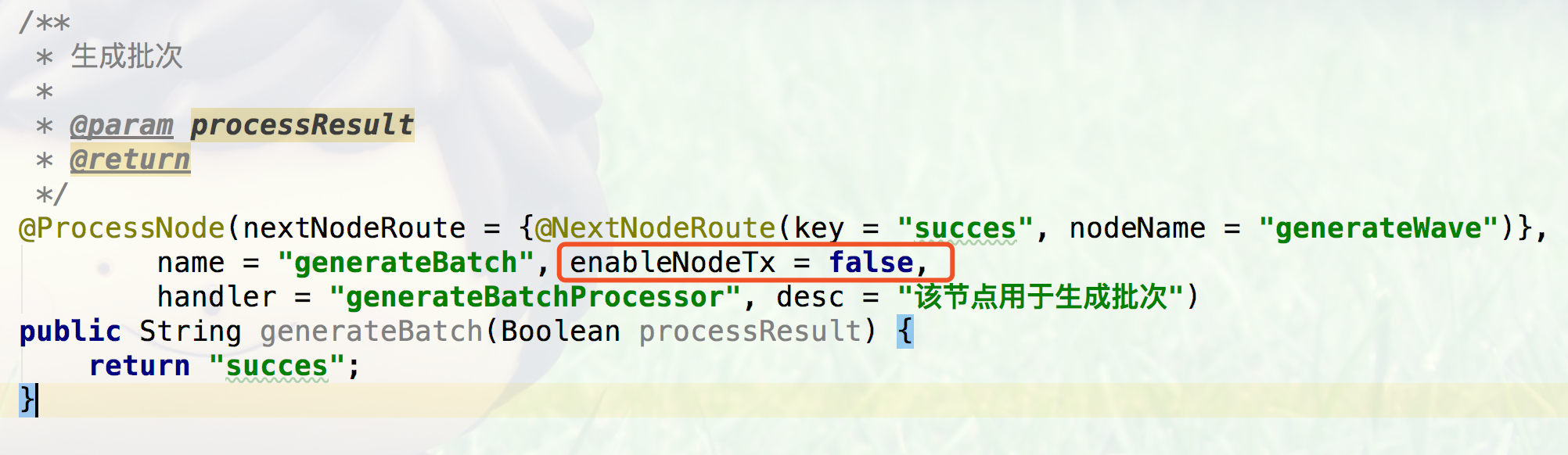
在Halo Flow中每个节点默认都是一个独立的单元,默认每个Node执行完毕就把当前节点的事务提交,如果不需要当前节点把事务提交可以在Node上 添加enableNodeTx = false。
24.4.9. 多数据源流程事务
Halo Flow采用Spring事务管理器进行事务管理,目前并不支持分布式事务。
当项目中用到多个数据源时,其中一个数据源(DataSource)必须显式的用@Primary标记。在默认情况下,Halo使用该DataSource对应的事务管理器,如果在流程中同时操作非@Primary数据源,则非@Primary数据源并不受Halo Flow事务管理。
通过@Flow的txManager属性,可以显式指定事务管理器的bean名称,与@Transactional(Spring)中transactionManager属性用法相同。
多数据源配置请参考:Halo Mybatis多数据源配置。
Flow事务管理器配置:

24.5. 流程编排信息采集
24.5.1. 登录到中台可视化查看
可以登录到Halo Admin查看中台可视化
25. Halo Plugin
Halo Plugin
26. Halo Cache
Halo Cache
27. 分层设计
27.1. 传统三层
传统三层即Controller,Service,Dao,需求开发直接一杆子从Controller捅到底。

| 事实证明传统三层指导不了复杂的软件系统开发! |
27.1.1. Halo传统三层分层
Halo的传统三层是结合Service,Dao,Controller,和命令的编程模式。
tradition-demo
├── README.md
├── pom.xml
├── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── tradition
│ │ └── demo
│ │ ├── Application.java //Spring Boot主入口程序类
│ │ ├── command //命令包
│ │ │ ├── AddUserCmdExe.java //写命令
│ │ │ ├── cmo
│ │ │ │ └── AddUserCmd.java //命令对象
│ │ │ ├── co
│ │ │ │ └── UserCO.java //客户端对象
│ │ │ └── query
│ │ │ └── QueryUserCmdExe.java //查询命令
│ │ ├── config
│ │ │ └── AutoConfig.java //自己定制的Spring Boot的AutoConfig
│ │ ├── controller
│ │ │ └── UserController.java //Controller
│ │ ├── converter
│ │ │ └── UserConverter.java //整个应用的转换防腐层,比如命令对象转为数据对象,数据对象转为客户端对象
│ │ ├── dao
│ │ │ └── UserMapper.java //MyBatis的Mapper
│ │ ├── dataobject
│ │ │ └── UserDO.java //数据对象
│ │ ├── service
│ │ │ ├── UserService.java //Service层的接口定义
│ │ │ └── impl
│ │ │ └── UserServiceImpl.java //Service层的接口实现,里面注入Mapper
│ │ └── utils
│ │ └── Iputil.java //自己写的工具类
│ └── resources
│ ├── META-INF
│ │ └── app.properties //Apollo的配置文件
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html27.2. Halo架构分层
在Halo 1.0中,我们的分层是如下左图所示的是DDD的经典分层,在Halo 2.0中,还是这些层次,但是依赖关系发生了变化,Domain层不再直接依赖Infrastructure层, 而是引入了一个端口适配器模式(Port/Adapter),使用DIP(Dependency Inversion Principle,依赖倒置)反转了Domain层和Infrastructure层的依赖关系,其关系如右图所示:
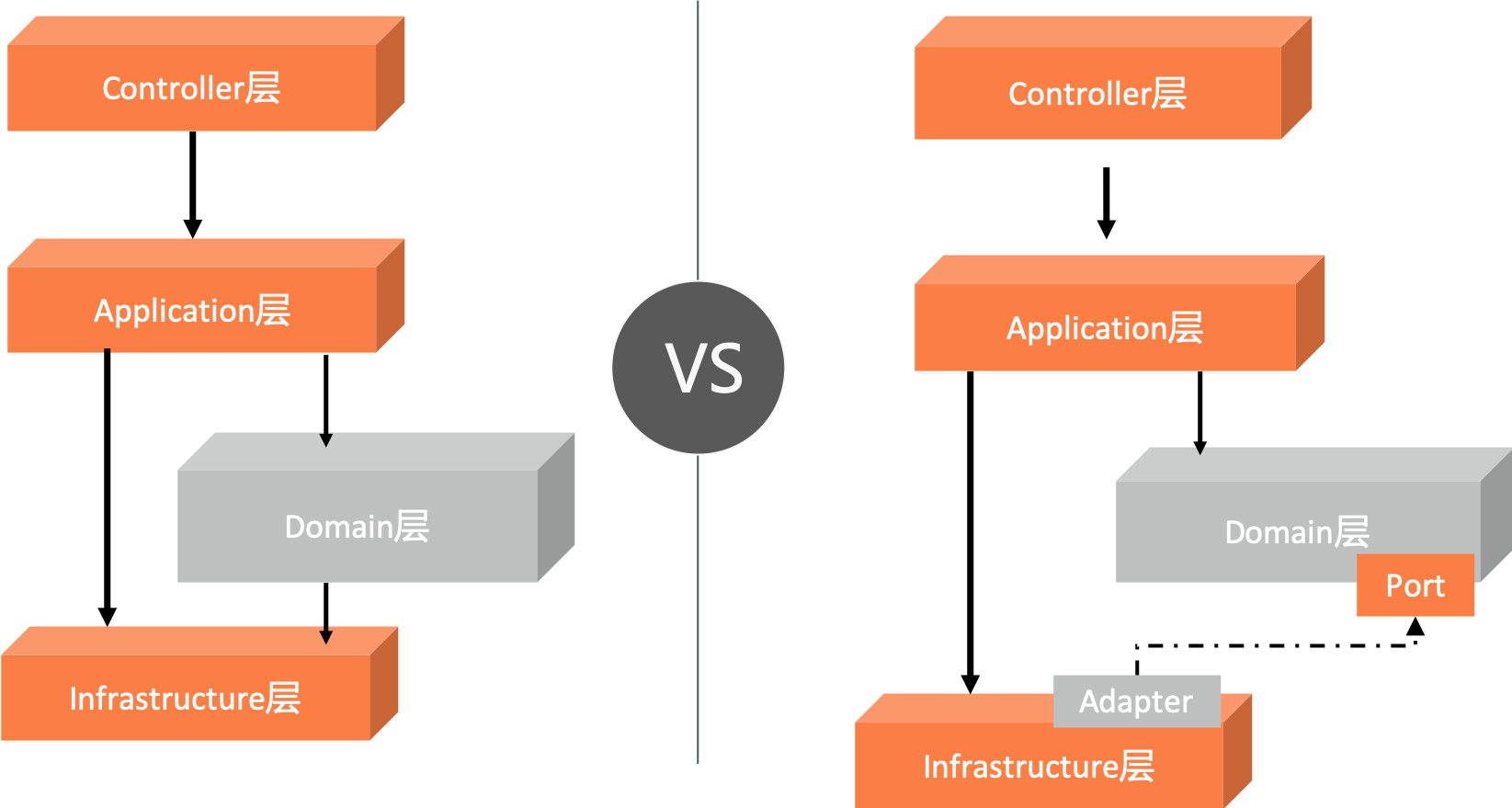
| Domain层不在依赖基础实施层,而是以接口的方式开放端口,让基础实施层去实现,这样设计的点是Domain层的演变和进化完全是独立的, 向上不受App层影响,向下不受基础设施层影响。 |
27.3. Halo应用分层
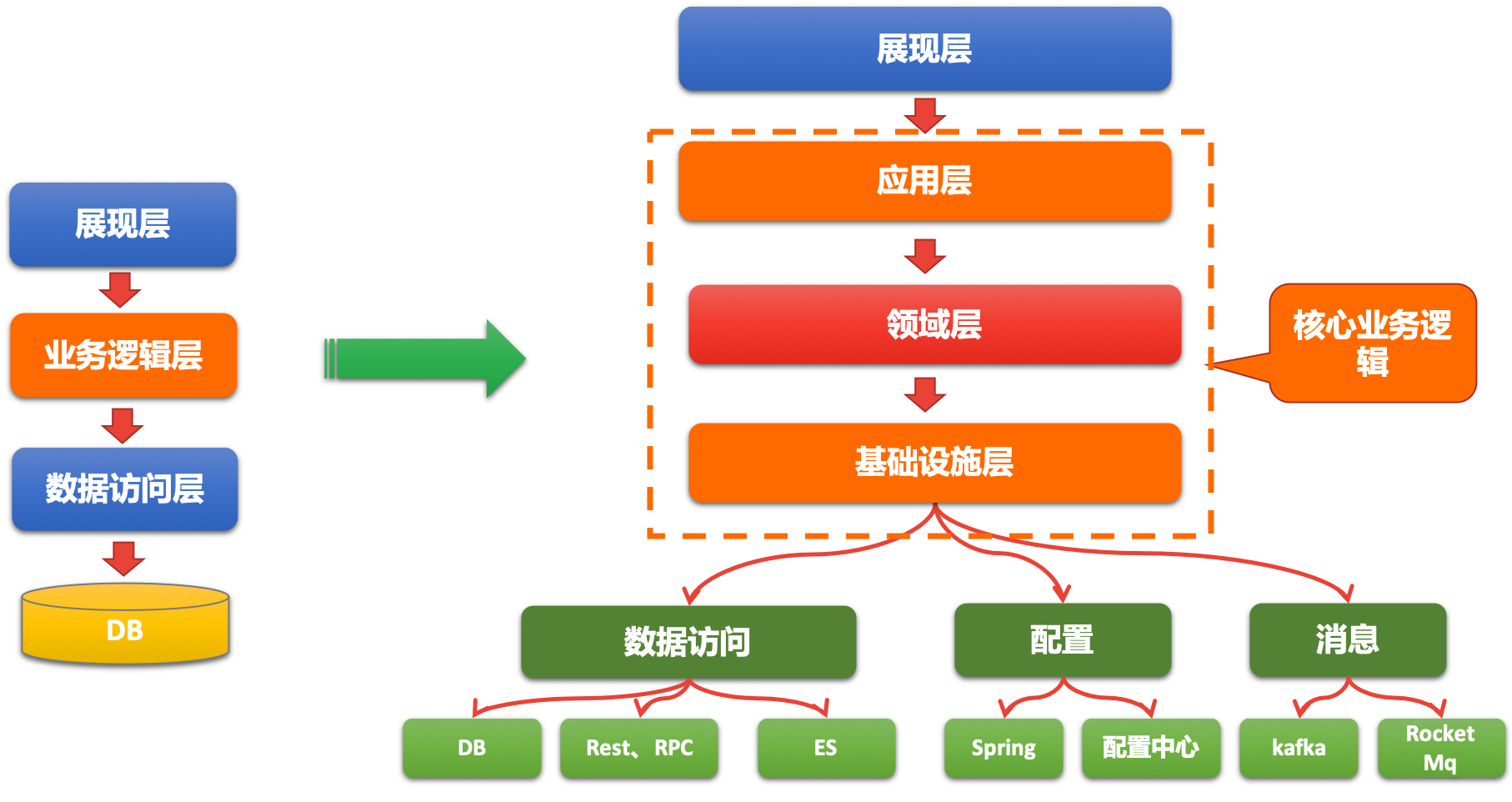
应用分层从传统的表现层,业务逻辑层,数据库层演变为表现层,领域层,基础设施层。以halo-goods应用为例 对应的工程模块如下所示:
| 模块 | 描述 | 备注 |
|---|---|---|
halo-goods-app |
halo-goods应用的应用层 |
应用层适合做参数校验,提供简单的应用服务,还有就是流程编排 |
halo-goods-domain |
halo-goods应用的领域层 |
领域层主要管理领域,领域划分 |
halo-goods-infrastructure |
halo-goods应用的基础设施层 |
|
halo-goods-start |
halo-goods应用的start |
|
halo-goods-client |
halo-goods应用的二方包 |

-
展现层
展现层负责向用户显示信息和解释用户指令。
-
应用层
应用层是很薄的一层,主要面向用户用例操作,协调和指挥领域对象来完成业务逻辑。应用层也是与其他系统的应用层进行交互的必要渠道。应用层服务尽量简单,它不包含业务规则或知识,只为下一层的领域对象协调任务,使它们互相协作。应用层还可进行安全认证、权限校验、分布式和持久化事务控制或向外部应用发送基于事件的消息等。
-
领域层
领域层是软件的核心所在,它实现全部业务逻辑并且通过各种校验手段保证业务正确性。它包含业务所涉及的领域对象(实体、值对象)、领域服务以及它们之间的关系。它负责表达业务概念、业务状态以及业务规则,具体表现形式就是领域模型。
-
基础设施层
基础层为各层提供通用的技术能力,包括:为应用层传递消息、提供 API 管理,为领域层提供数据库持久化机制等。它还能通过技术框架来支持各层之间的交互。
27.3.1. 经典DDD分层
领域驱动设计经典分层如下所示:
├-halo-demo
├── halo-demo-app //应用层
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── halo
│ └── demo
│ └── app
│ ├── appservice //应用层服务
│ │ └── UploadFileAS.java
│ ├── command //命令
│ │ ├── AddCustomerCmdExe.java
│ │ ├── AddUserCmdExe.java
│ │ ├── TestFlowCmdExe.java
│ │ ├── cmo //命令对象
│ │ │ ├── AddAddressCmd.java
│ │ │ ├── AddContactInfoCmd.java
│ │ │ ├── AddCustomerCmd.java
│ │ │ └── AddUserCmd.java
│ │ └── co //客户端对象
│ │ └── UserCO.java
│ ├── converter //转换层
│ │ ├── CustomerClientConverter.java
│ │ └── UserClientConverter.java
│ ├── ext //扩展点
│ │ ├── AlipayExt.java
│ │ └── PayExtPt.java
│ ├── flow //流程编排
│ │ ├── DemoFlow.java
│ │ └── node
│ │ ├── FirstNodeProcessor.java
│ │ └── SecondNodeProcessor.java
│ └── interceptor
│ └── PhenixContextPreInterceptor.java
├── halo-demo-client //二方包
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── halo
│ └── demo
│ └── client
│ └── co
│ └── UserCO.java
├── halo-demo-domain //领域层
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── halo
│ └── demo
│ └── domain
│ ├── customer // A领域
│ │ ├── converter //转换层
│ │ │ └── CustomerConverter.java
│ │ ├── entity //实体
│ │ │ └── CustomerE.java
│ │ ├── factory //工厂
│ │ │ └── CustomerFactory.java
│ │ ├── ports //端口
│ │ │ └── CustomerPort.java
│ │ ├── repository //资源库
│ │ │ └── CustomerRepository.java
│ │ ├── service //领域服务
│ │ │ ├── CustomerSevice.java
│ │ │ └── impl
│ │ │ └── CustomerServiceImpl.java
│ │ └── valueobject
│ │ ├── AddressVO.java
│ │ └── ContactInfoVO.java
│ └── user
│ ├── converter
│ │ └── UserConverter.java
│ ├── entity
│ │ └── UserE.java
│ ├── factory
│ │ └── UserFactory.java
│ ├── ports
│ │ └── UserPort.java
│ ├── repository
│ │ └── UserRepository.java
│ └── service
│ ├── UserService.java
│ └── impl
│ └── UserServiceImpl.java
├── halo-demo-infrastructure //基础设施层
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── halo
│ └── demo
│ └── infrastructure
│ ├── adapters //适配器
│ │ ├── CustomerAdapter.java
│ │ └── UserAdapter.java
│ └── tunnel //数据通道
│ └── db
│ ├── dao //Mapper
│ │ ├── AddressMapper.java
│ │ ├── ContactinfoMapper.java
│ │ ├── CustomerMapper.java
│ │ └── UserMapper.java
│ └── dataobject //数据对象
│ ├── AddressDO.java
│ ├── ContactinfoDO.java
│ ├── CustomerDO.java
│ └── UserDO.java
├── halo-demo-start //应用入口
│ ├── pom.xml
│ └── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── halo
│ │ └── demo
│ │ ├── Application.java //主程序入口
│ │ └── start
│ │ └── controller //Controller
│ │ ├── CustomerController.java
│ │ ├── TestFlowController.java
│ │ └── UserController.java
│ └── resources
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html
├── pom.xml27.3.2. Halo简化版DDD分层
Halo DDD的简化版,是把App层,domain层,基础设施层合并到core模块,减少层次结构
├── ddd-demo-client //二方包
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── ddd
│ └── demo
│ └── client
│ ├── api //接口定义
│ ├── cmo //命令对象
│ └── co
│ └── UserCO.java //客户端对象
├── ddd-demo-core //应用的核心层,包含了ddd中的app层,domain层和基础设施层
│ ├── pom.xml
│ └── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── ddd
│ │ └── demo
│ │ ├── app
│ │ │ ├── command
│ │ │ │ ├── AddUserCmdExe.java // 写命令
│ │ │ │ ├── cmo
│ │ │ │ │ └── AddUserCmd.java //命令对象
│ │ │ │ ├── co
│ │ │ │ │ └── UserCO.java //客户端对象
│ │ │ │ └── query //查询命令
│ │ │ └── converter
│ │ │ └── UserClientConverter.java //转换防腐层
│ │ ├── domain
│ │ │ ├── aggregate01 //聚合1
│ │ │ │ ├── converter
│ │ │ │ │ └── UserConverter.java // app进domain的转换层
│ │ │ │ ├── entity
│ │ │ │ │ └── UserE.java //实体
│ │ │ │ ├── factory
│ │ │ │ │ └── UserFactory.java //工厂
│ │ │ │ ├── ports
│ │ │ │ │ └── UserPort.java //端口
│ │ │ │ ├── repository
│ │ │ │ │ └── UserRepository.java //资源库
│ │ │ │ └── service
│ │ │ │ ├── UserService.java //域服务接口
│ │ │ │ └── impl
│ │ │ │ └── UserServiceImpl.java //域服务接口实现
│ │ │ └── aggregate02 //聚合2
│ │ │ └── test.java
│ │ └── infrastructure
│ │ ├── adapters
│ │ │ └── UserAdapter.java //基础设施层-适配层
│ │ └── tunnel //数据通道
│ │ └── db
│ │ ├── dao
│ │ │ └── UserMapper.java //MyBatis对应的Mapper
│ │ └── dataobject
│ │ └── UserDO.java //数据对象
│ └── resources
│ ├── META-INF
│ │ └── app.properties
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html
├── ddd-demo-start //应用启动入口,只允许放Controller和自己开发的Spring Boot Starter
│ ├── pom.xml
│ └── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── ddd
│ │ └── demo
│ │ ├── Application.java //主入口程序启动类
│ │ └── start
│ │ └── controller // controller所在包
│ │ └── UserController.java
│ └── resources
│ ├── META-INF
│ │ └── app.properties
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html
├── ddd-demo.iml
├── pom.xml27.4. Halo的组件视图
在Halo 2.0中,我们重新设计了组件,引入了一些新的组件,也去除了一些旧组件。这些变动的宗旨是为了让应用结构更加清晰,组件的职责更加明确,从而更好的提供开发指导和约束。 新的组件结构如下图所示:
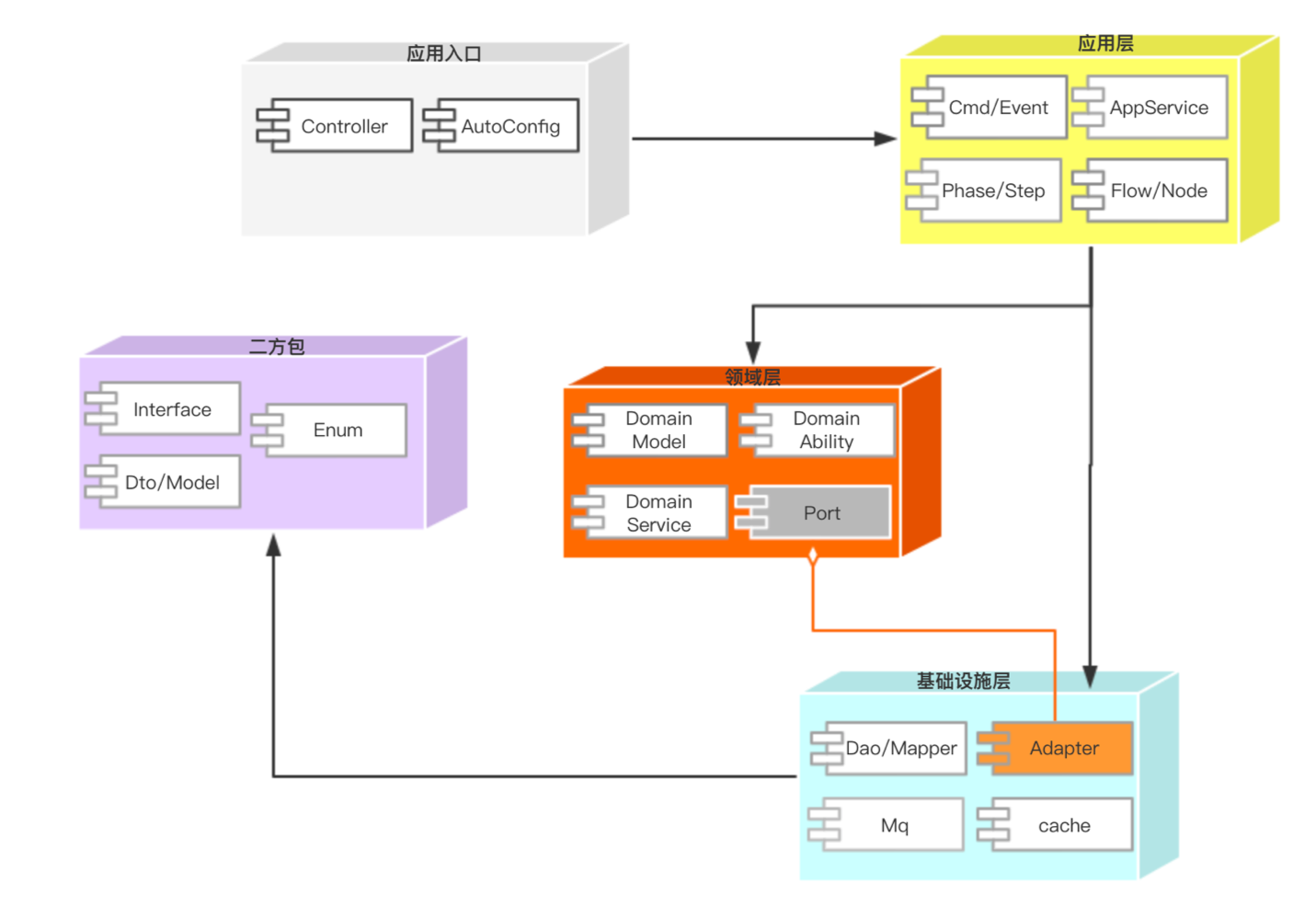
| 模块 | 描述 | 备注 |
|---|---|---|
xxx-xxx-app |
xxx或xxx-xxx应用的应用层 |
应用层的组件有命令,事件,领域服务(包含命令,Phase(阶段),Step(步骤),Flow(流程),Node(节点)等) |
xxx-xxx-domain |
xxx或xxx-xxx应用的领域层 |
组件主要有领域对象,领域服务和领域能力,开放的Port(端口,即接口) |
xxx-xxx-infrastructure |
xxx或xxx-xxx应用的基础设施层 |
组件主要有Dao或Mapper,缓存操作,RPC调用,REST调用 |
xxx-xxx-start |
xxx或xxx-xxx应用的start |
标志应用的入口,主要有Controller等 |
xxx-xxx-client |
xxx或xxx-xxx应用的二方包 |
包含接口定义,入参返回值,枚举等 |

27.6. Halo服务视图
-
应用服务
应用服务位于应用层。用来表述应用和用户行为,负责服务的组合、编排和转发,负责处理业务用例的执行顺序以及结果的拼装。
应用层的服务包括应用服务和领域事件相关服务。
应用服务可对微服务内的领域服务以及微服务外的应用服务进行组合和编排,或者对基础层如文件、缓存等数据直接操作形成应用服务,对外提供粗粒度的服务。
领域事件服务包括两类:领域事件的发布和订阅。通过事件总线和消息队列实现异步数据传输,实现微服务之间的解耦。
-
领域服务
领域服务位于领域层,为完成领域中跨实体或值对象的操作转换而封装的服务,领域服务以与实体和值对象相同的方式参与实施过程。
领域服务对同一个实体的一个或多个方法进行组合和封装,或对多个不同实体的操作进行组合或编排,对外暴露成领域服务。领域服务封装了核心的业务逻辑。实体自身的行为在实体类内部实现,向上封装成领域服务暴露。
为隐藏领域层的业务逻辑实现,所有领域方法和服务等均须通过领域服务对外暴露。
为实现微服务内聚合之间的解耦,原则上禁止跨聚合的领域服务调用和跨聚合的数据相互关联。
-
基础服务
基础服务位于基础层。为各层提供资源服务(如数据库、缓存等),实现各层的解耦,降低外部资源变化对业务逻辑的影响。
基础服务主要为仓储服务,通过依赖反转的方式为各层提供基础资源服务,领域服务和应用服务调用仓储服务接口,利用仓储实现持久化数据对象或直接访问基础资源。
27.7. 分层对象
传统应用分层产生VO(View Object)视图对象,DAO(data access object) 数据访问对象,PO(persistant object) 持久对象即实体.
Halo框架分层之后会产生如下对象
| 名称 | 描述 | 备注 |
|---|---|---|
Command Object |
命令对象 |
命令对象简单CMO |
Entity |
实体 |
DDD中的实体 |
value object |
值对象 |
值对象简称VO |
Data Object |
数据对象 |
数据对象简称DO,相当于传统三层中的实体和数据库表结构映射 |
Client Object |
客户端对象 |
所有的命令处理完毕之后,返回的对象皆为客户端对象,客户端包括前端,服务消费方等 |
CO,DO,Entity之间的转换关系如下图所示:
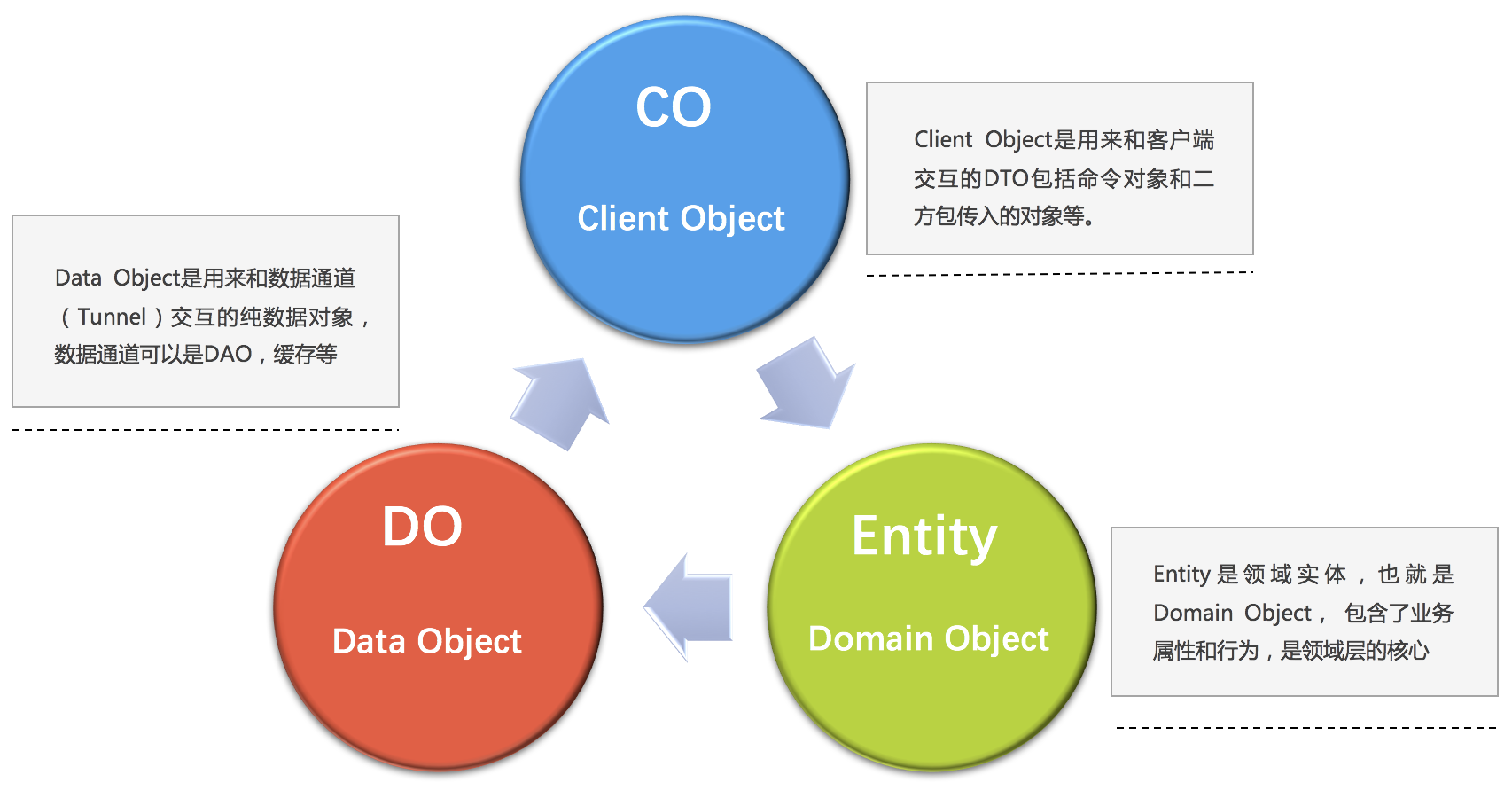
27.8. Convertor设计
在Halo中有三类主要的对象:
-
ClientObject: 也就是二方库中的数据对象,主要承担DTO的职责。
-
Entity/ValueObject: 也就是既有属性又有行为的领域实体。
-
DataObeject:是用来获取数据用的,主要是DAO使用。
Convertor在上面三个对象之间的转换起到了至关重要的作用,然而Convertor里面的逻辑应该是简单的,大部分都是setter/getter, 如果属性重复度很高的话,也可以使用BeanUtils.copyProperties让代码变得更简洁。但事实情况是,现在系统中很多的Convertor 逻辑并没有在Convertor里面。
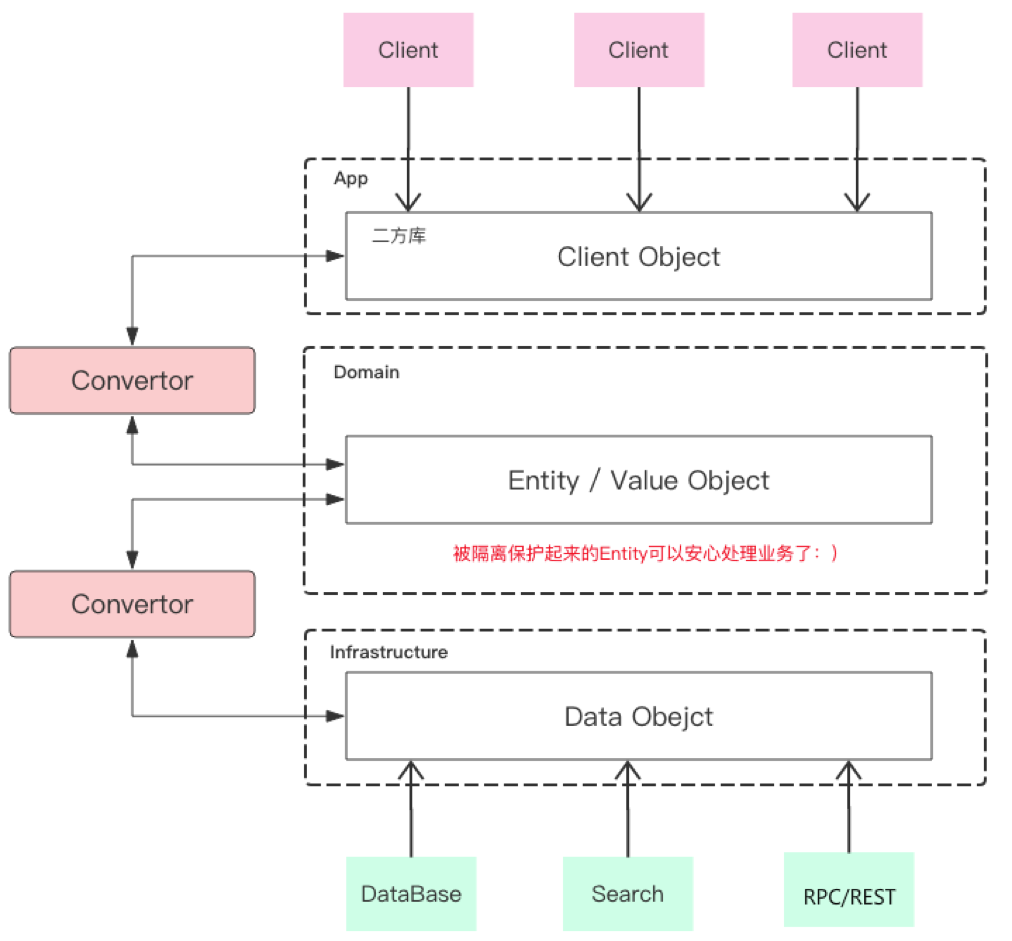
28. Halo Check
Halo Framework提供代码质量检查工具,目前包含了CheckStyle和PMD代码检查.
28.2. CheckStyle
checkstyle是一种静态代码分析工具,用来分析java代码是否符合定义的规则; 常用以下方面检查
-
属性和方法的命名约定
-
方法参数的个数
-
代码行的长度
-
强制性文件头,如copyright author
-
import和public privte protect等修饰符的使用
-
字符间空格的间隔
-
代码复杂度检查
28.3. PMD
全称:Programming Mistake Detector;
常用以下方面检查
-
Possible bugs — Empty try/catch/finally/switch blocks/eating original exception and throwing a new one
-
Dead code — Unused [local variables](https://en.wikipedia.org/wiki/Local_variable), [parameters](https://en.wikipedia.org/wiki/Parameter), and [private methods](https://en.wikipedia.org/wiki/Private_method)
-
Empty if/while statements
-
Overcomplicated expressions — Unnecessary if statements, for loops that could be while loops
-
Suboptimal code — Wasteful String/StringBuffer usage
-
Classes with high [Cyclomatic Complexity](https://en.wikipedia.org/wiki/Cyclomatic_complexity) measurements
-
Incorrect BigDecimal Usage
28.4. 使用说明
目标用户:项目管理员
-
第一步:在项目中引入maven插件
<plugin>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-maven-githook</artifactId>
<version>1.0.0-SNAPSHOT</version>
<executions>
<execution>
<goals>
<goal>git-hooks</goal>
</goals>
<configuration>
<ghooks>
<pre-commit>pre-commit-sh/pre-commit.sh</pre-commit>
<pre-commit-checkstyle>pre-commit-sh/pre-commit-checkstyle.sh</pre-commit-checkstyle>
<pre-commit-pmd>pre-commit-sh/pre-commit-pmd.sh</pre-commit-pmd>
</ghooks>
</configuration>
<phase>compile</phase>
</execution>
</executions>
</plugin>当Maven对应用进行编译时,将会触发安装,安装日志如下:
[INFO] --- maven-compiler-plugin:3.8.1:compile (default-compile) @ halo-admin-start ---
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 23 source files to /xujin/code/halo-admin/halo-admin-start/target/classes
[INFO]
[INFO] --- halo-maven-githook:1.0.0-SNAPSHOT:git-hooks (default) @ halo-admin-start ---
[INFO] ========== pre-commit ==========
[INFO] Install Halo Check Component [halo-pmd.jar]...
[INFO] Install Halo Check Component [halo-checkstyle.jar]...
[INFO] Install git hook[pre-commit]...
[INFO] Use plugin git hook file: pre-commit-sh/pre-commit.sh
[INFO] ========== pre-commit-checkstyle ==========
[INFO] Install Halo Check Component [halo-pmd.jar]...
[INFO] Install Halo Check Component [halo-checkstyle.jar]...
[INFO] Install git hook[pre-commit-checkstyle]...
[INFO] Use plugin git hook file: pre-commit-sh/pre-commit-checkstyle.sh
[INFO] ========== pre-commit-pmd ==========
[INFO] Install Halo Check Component [halo-pmd.jar]...
[INFO] Install Halo Check Component [halo-checkstyle.jar]...
[INFO] Install git hook[pre-commit-pmd]...
[INFO] Use plugin git hook file: pre-commit-sh/pre-commit-pmd.sh
[INFO]
[INFO] --- maven-resources-plugin:3.1.0:testResources (default-testResources) @ halo-admin-start ---
[INFO] Using 'UTF-8' encoding to copy filtered resources.-
第二步(可跳过):去Halo-admin 定制本项目的校验规则
如不需要定制个性化校验规则,可以跳过本步骤,使用系统默认的规则
1) 在 代码质量管理>规则文件管理 菜单下新增规则文件,然后编辑规则文件选择要check的规则
2) 在 代码质量管理>项目规则管理 菜单下,找到自己的项目,然后设置上一步新建的规则文件
VI Halo Boot
29. 什么是Starter
何为starter? "一种服务": 预配置,依赖关系完整,自我管理.
-
预配置: 默认值应足够好,在大部分情况下不需要修改
-
依赖关系完整: pom.xml只需要加上starter的依赖,相关jar应该完整,不需要再额外添加
-
自我管理: starter应该有自己的生命周期
30. Halo Boot概述
Halo Boot 是基于 Spring Boot 的研发框架,将开发过程中经常需要使用的组件进行封装做到开箱即用。它在 Spring Boot 的基础上,提供了诸如 Readiness Check,类隔离,日志空间隔离等能力。在增强了 Spring Boot 的同时,Halo Boot 提供了让用户可以在 Spring Boot 中非常方便地使用 Halo相关中间件以及第三方中间件的能力。
-
Halo Boot主要模块
-
DDD与CQRS: halo-basic
-
应用内部流程编排: halo-flow
-
web层:通过Halo web对Spring Web进行封装增强。
-
数据库访问层: halo-mybatis,halo-mongodb,halo-es6,halo-es7 。
-
文档调试:halo-swagger,通过对Swagger进行封装定制方便开箱即用。
-
配置中心: halo-apollo。
-
分布式缓存: halo-redis。
-
分布式定时任务: halo-job
-
消息队列: halo-alimq(商业版Mq,即ONS)
-
31. Halo Boot扩展
31.1. @HaloApplication注解
Halo Boot可以通过HaloApplication去替代@SpringBootApplication注解,Halo Boot默认会获取并设置最基本的类扫描包. @HaloApplication的代码如下所示:
@Documented
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@SpringBootApplication
public @interface HaloApplication {
String appId() default "";
}| 其中的appId用于设置当前应用在Halo应用的全局唯一ID,如果不设置将获取Spring Application Name作为唯一标识(其实唯一标识不应该具有任何服务注册与发现的含义等,只有全局唯一标识).其实大型互联网系统中都有对应的系统去管理应用的生命周期,需要唯一的标识. |
33. Halo Mybatis
Halo Mybatis是Halo框架进行选型对Mybatis,Mybatis Plus进行增强的数据库访问层组件
33.1. Halo Mybatis的功能
-
完全兼容MyBatis-Plus,在其基础上增加支持字段加解密、JSON对象字段自动映射等功能。
-
增强MyBatis-Plus通用枚举,自动注册基础扫描包中通用枚举类型。
-
分页插件已默认启用
-
支持配置自动应用到多数据源:包括加解密字段、JSON对象字段、通用枚举字段、分页插件等。
-
对HikariCP数据源的参数进行了优化,简化配置,只需要配置(url、userName、password)三个即可。
-
jdbc默认会把查询结果集全部返回到客户端导致oom,对空where进行拦截判断
33.2. Halo的默认内置HikariCP
Spring Boot 2.0开始推 HikariCP,将默认的数据库连接池从tomcat jdbc pool改为了hikariCp 。 HikariCP 在性能和并发方面确实表现不俗(号称最快的连接池)。
如果你使用 spring-boot-starter-jdbc 或 spring-boot-starter-data-jpa ,会自动添加对 HikariCP 的依赖,也就是说此时使用 HikariCP 。当然你也可以强制使用其它的连接池技术,可以通过在 application.properties 或 application.yml 中配置 spring.datasource.type 指定。
-
必须配置的属性
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/alicedb?characterEncoding=UTF-8&useSSL=false
username: 用户名
password: 密码| 对HikariCP数据源的参数进行了优化,简化配置,只需要配置(url、userName、password)三个即可 |
-
无需配置的属性
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/alicedb?characterEncoding=UTF-8&useSSL=false
username: 用户名
password: 密码
type: com.zaxxer.hikari.HikariDataSource (1)
driver-class-name: com.mysql.jdbc.Driver (2)
| 1 | Spring Boot 2.x默认内置数据库连接池为hikariCp,因此无需配置,如果是其它数据连接池需要配置 |
| 2 | 无需设置Spring Boot根据数据库连接的URL可以判断出对应的数据库连接驱动的Class Name
|
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/alicedb?characterEncoding=UTF-8&useSSL=false
username: 用户名
password: 密码
hikari:
auto-commit: true (1)
connection-test-query: SELECT 1 (2)
connection-timeout: 30000 (3)
idle-timeout: 180000 (4)
max-lifetime: 1800000 (5)
maximum-pool-size: 10 (6)
minimum-idle: 5 (7)
pool-name: MyHikariCP (8)| 1 | 此属性控制从池返回的连接的默认自动提交行为,默认值:true |
| 2 | 连接测试的sql |
| 3 | 数据库连接超时时间,默认30秒,即30000 |
| 4 | 空闲连接存活最大时间,默认600000(10分钟) |
| 5 | 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟 |
| 6 | 连接池最大连接数,默认是10 |
| 7 | 最小空闲连接数量 |
| 8 | 连接池Name |
33.2.1. 查看HikariCP默认配置
HikariCP的主要配置参数是在 com.zaxxer.hikari.HikariConfig中初始化的,部分参数是在 com.zaxxer.hikari.pool.PoolBase 中初始化的。 Spring Boot在org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.java中封装了HikariCP需要的基本配置。Spring Boot对hikariCP的配置封装如下图所示:
33.2.2. Halo中HikariCP的配置
Halo Mybatis基于Spring Boot进行扩展增强,因此HikariCP连接池及其在Spring Boot中的配置和官方保持一致,如下表格所示:
| 配置项 | 描述 | 构造器默认值 | 默认配置validate之后的值 | validate重置 |
|---|---|---|---|---|
autoCommit |
自动提交从池中返回的连接 |
true |
true |
- |
connectionTimeout |
等待来自池的连接的最大毫秒数 |
SECONDS.toMillis(30) = 30000 |
30000 |
如果小于250毫秒,则被重置回30秒 |
idleTimeout |
连接允许在池中闲置的最长时间 |
MINUTES.toMillis(10) = 600000 |
600000 |
如果idleTimeout+1秒>maxLifetime 且 maxLifetime 0,则会被重置为0(代表永远不会退出);如果idleTimeout!=0且小于10秒,则会被重置为10秒 |
maxLifetime |
池中连接最长生命周期 |
MINUTES.toMillis(30) = 1800000 |
1800000 |
如果不等于0且小于30秒则会被重置回30分钟 |
connectionTestQuery |
如果您的驱动程序支持JDBC4,我们强烈建议您不要设置此属性 |
null |
null |
- |
minimumIdle |
池中维护的最小空闲连接数 |
-1 |
10 |
minIdle<0或者minIdle>maxPoolSize,则被重置为maxPoolSize |
maximumPoolSize |
池中最大连接数,包括闲置和使用中的连接 |
-1 |
10 |
如果maxPoolSize小于1,则会被重置。当minIdle⇐0被重置为DEFAULT_POOL_SIZE则为10;如果minIdle>0则重置为minIdle的值 |
metricRegistry |
该属性允许您指定一个 Codahale / Dropwizard MetricRegistry 的实例,供池使用以记录各种指标 |
null |
null |
- |
healthCheckRegistry |
该属性允许您指定池使用的Codahale / Dropwizard HealthCheckRegistry的实例来报告当前健康信息 |
null |
null |
- |
poolName |
连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 |
null |
HikariPool-1 |
- |
initializationFailTimeout |
如果池无法成功初始化连接,则此属性控制池是否将fail fast |
1 |
1 |
- |
isolateInternalQueries |
是否在其自己的事务中隔离内部池查询,例如连接活动测试 |
false |
false |
- |
allowPoolSuspension |
控制池是否可以通过JMX暂停和恢复 |
false |
false |
- |
readOnly |
从池中获取的连接是否默认处于只读模式 |
false |
false |
- |
registerMbeans |
是否注册JMX管理Bean(MBeans) |
false |
false |
- |
catalog |
为支持 catalog 概念的数据库设置默认 catalog |
driver default |
null |
- |
connectionInitSql |
该属性设置一个SQL语句,在将每个新连接创建后,将其添加到池中之前执行该语句。 |
null |
null |
- |
driverClassName |
HikariCP将尝试通过仅基于jdbcUrl的DriverManager解析驱动程序,但对于一些较旧的驱动程序,还必须指定driverClassName |
null |
null |
- |
transactionIsolation |
控制从池返回的连接的默认事务隔离级别 |
null |
null |
- |
alidationTimeout |
连接将被测试活动的最大时间量 |
SECONDS.toMillis(5) = 5000 |
5000 |
如果小于250毫秒,则会被重置回5秒 |
leakDetectionThreshold |
记录消息之前连接可能离开池的时间量,表示可能的连接泄漏 |
0 |
0 |
如果大于0且不是单元测试,则进一步判断:(leakDetectionThreshold < SECONDS.toMillis(2) or (leakDetectionThreshold > maxLifetime && maxLifetime > 0),会被重置为0 . 即如果要生效则必须>0,而且不能小于2秒,而且当maxLifetime > 0时不能大于maxLifetime |
dataSource |
这个属性允许你直接设置数据源的实例被池包装,而不是让HikariCP通过反射来构造它 |
null |
null |
- |
schema |
该属性为支持模式概念的数据库设置默认模式 |
driver default |
null |
- |
threadFactory |
此属性允许您设置将用于创建池使用的所有线程的java.util.concurrent.ThreadFactory的实例。 |
null |
null |
- |
scheduledExecutor |
此属性允许您设置将用于各种内部计划任务的java.util.concurrent.ScheduledExecutorService实例 |
null |
null |
- |
33.3. HikariCP多数据源配置
Spring Boot中的数据源自动装配方式适用于单数据源,对于多数源的配置,可以参考 SpringBoot Configure Two DataSources。
Halo集成了Mybatis Plus,在配置多数据源时,需要将Mybatis Plus和数据源进行集成。
由于Halo Flow管理流程事务的需要,在配置数据源的同时,需提供对应数据源的事务管理器。
双数据源配置示例 Java:
@Configuration
@MapperScan(basePackages = "org.xujin.defensor.mybatis2.mapper.halo", sqlSessionFactoryRef = "haloSqlSessionFactory")
@MapperScan(basePackages = "org.xujin.defensor.mybatis2.mapper.forge", sqlSessionFactoryRef = "forgeSqlSessionFactory")
public class DaoConfig {
/**
* halo datasource begin
*/
@Primary
@Bean
@ConfigurationProperties("spring.datasource.halo")
public DataSourceProperties haloDataSourceProperties() {
return new DataSourceProperties();
}
@Primary
@Bean(value = "haloDataSource")
@ConfigurationProperties("spring.datasource.halo.hikari")
public DataSource tradeDataSource() {
return haloDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Primary
@Bean("haloTxManager")
public PlatformTransactionManager tradeTxManager(@Qualifier("haloDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Primary
@Bean("haloSqlSessionFactory")
public SqlSessionFactory tradeSqlSessionFactory(@Qualifier("haloDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean sqlSessionFactoryBean = new MybatisSqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
// 需要Mybatis Mapper xml配置时添加
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/halo/*Mapper.xml"));
return sqlSessionFactoryBean.getObject();
}
/**
* forge datasource begin
*/
@Bean
@ConfigurationProperties("spring.datasource.forge")
public DataSourceProperties forgeDataSourceProperties() {
return new DataSourceProperties();
}
@Bean(value = "forgeDataSource")
@ConfigurationProperties("spring.datasource.forge.hikari")
public DataSource forgeDataSource() {
return forgeDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean("forgeTxManager")
public PlatformTransactionManager forgeTxManager(@Qualifier("forgeDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean("forgeSqlSessionFactory")
public SqlSessionFactory forgeSqlSessionFactory(@Qualifier("forgeDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean sqlSessionFactoryBean = new MybatisSqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
// 需要Mybatis Mapper xml配置时添加
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/forge/*Mapper.xml"));
return sqlSessionFactoryBean.getObject();
}
}application.yml:
spring:
datasource:
halo:
url: jdbc:mysql://***
username: ***
password: ***
hikari:
maximum-pool-size: 20
minimum-idle: 10
forge:
url: jdbc:mysql://***
username: ***
password: ***
hikari:
maximum-pool-size: 20
minimum-idle: 10上面示例中,配置了两个数据源:trade、forge,并将数据源与Mybatis Plus进行集成,同时为每个数据源配置了对应的事务管理器。
33.4. Halo提供的HaloBaseMap
HaloBaseMapper继承了com.baomidou.mybatisplus.core.mapper.BaseMapper,支持Mybatis分页查询支持传递Map, 具体的扩展代码如下所示
public interface HaloBaseMapper<T> extends com.baomidou.mybatisplus.core.mapper.BaseMapper<T> {
/**
* 精确分页查询
*
* @param page:分页查询对象
* @param param: key须是数据库字段,value是比较值
* @return
*/
default Page<T> selectPageAccurate(Page<T> page, Map<String, Object> param) {
return selectPage(page, Wrappers.<T>query().allEq(param));
}
/**
* 精确总数查询
*
* @param param: key须是数据库字段,value是比较值
* @return
*/
default Integer selectCountAccurate(Map<String, Object> param) {
return selectCount(Wrappers.<T>query().allEq(param));
}
/**
* 模糊分页查询
*
* @param page:分页查询对象
* @param param: key须是数据库字段,value是比较值
* @return
*/
default Page<T> selectPageBlurry(Page<T> page, Map<String, Object> param) {
QueryWrapper<T> query = Wrappers.<T>query();
if (null != param) {
param.forEach((k, v) -> {
query.like(k, v);
});
}
return selectPage(page, query);
}
/**
* 模糊总数查询
*
* @param param: key须是数据库字段,value是比较值
* @return
*/
default Integer selectCountBlurry(Map<String, Object> param) {
QueryWrapper<T> query = Wrappers.<T>query();
if (null != param) {
param.forEach((k, v) -> {
query.like(k, v);
});
}
return selectCount(query);
}
/**
* 内部使用方法 强转Ipage对象
*
* @param page
* @param queryWrapper
* @return
*/
default Page<T> selectPage(Page<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper) {
return (Page<T>)selectPage((IPage<T>)page, queryWrapper);
}
}33.5. Halo Mybatis的使用
33.5.1. Maven引入
-
引入Halo-MyBatis依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 mybatis 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-mybatis</artifactId>
</dependency>33.5.2. 演示代码
-
数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
platform: mysql
url: jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8
username: root
password: root-
实体类
@TableName("city")
@Data
public class City implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type=AUTO)
private Long id;
private String name;
@TableField("state")
private EncryptedColumn state;
@TableField("country")
private String country;
}| 说明:如果表字段采用了例如:key, value, order作为字段,会报错org.springframework.jdbc.BadSqlGrammarException。此时需要处理关键字为‘关键字’, 示例:@TableField(value=“key”) |
-
Mapper
@Mapper
public interface CityMapper extends MyBaseMapper<City> {
@Select("select count(0) from city")
int test();
}-
Service
@Service
public class CityService {
@Autowired
private CityMapper cityMapper;
/***
* @Description: 创建新城市。并返回插入数据的条数
* @Param: [name]
* @Return: int
*/
public int createCity(String name) {
City newCity = new City();
newCity.setName(name);
return cityMapper.insert(newCity);
}
/***
* @Description: 创建新城市。返回city实体
* @Param: [name]
* @Return: boolean
*/
public City createCity2(String name) {
City newCity = new City();
newCity.setName(name);
if (cityMapper.insert(newCity)>0) {
return newCity;
} else {
return null;
}
}
/***
* @Description: 根据id更新城市名称,返回更新成功的条数
* @Param: [id, newName]
* @Return: int
*/
public int updateCity(long id, String newName) {
City cityUpdate = new City();
cityUpdate.setId(id);
cityUpdate.setName(newName);
return cityMapper.updateById(cityUpdate);
}
/***
* @Description: 根据名称查询城市
* @Param: [name]
*/
public City findCityByName(String name) {
return cityMapper.selectOne(Wrappers.<City>query().eq(getFieldName(City::getName), name));
}
/***
* @Description: 根据名称模糊查询
* @Param: [name]
*/
public List<City> findManyCityByNameLike(String name) {
return cityMapper.selectList(Wrappers.<City>query().like(getFieldName(City::getName), name));
}
/***
* @Description: 根据名称做分页排序查询,ascs是升序排列的字段。page=1 size=10 表示查询第一页,每页10条数据
* @Param: [name, page, size, ascs]
* @Return: com.baomidou.mybatisplus.extension.plugins.pagination.Page
*/
public Page findPagedCityByNameAsc(String name, int page, int size, List<String> ascs) {
Page pageRequest = new Page(page, size);
pageRequest.setAscs(ascs);
Map<String, Object> param=new HashMap<>();
param.put(getFieldName(City::getName),name);
return cityMapper.selectPageAccurate(pageRequest,param);
}
/***
* @Description: 根据名称做分页排序查询(用like做模糊查询),ascs是升序排列的字段。page=1 size=10 表示查询第一页,每页10条数据
* @Param: [name, page, size, ascs]
* @Return: com.baomidou.mybatisplus.extension.plugins.pagination.Page
*/
public Page findPagedCityByNameLikeAsc(String name, int page, int size, List<String> ascs) {
Page pageRequest = new Page(page, size);
pageRequest.setAscs(ascs);
Map<String, Object> param=new HashMap<>();
param.put(getFieldName(City::getName),name);
return cityMapper.selectPageBlurry(pageRequest,param);
}
/***
* @Description: 根据ID删除
* @Param: [id]
* @Return: int
*/
public int deleteById(long id) {
return cityMapper.deleteById(id);
}
/***
* @Description: 根据id批量删除
* @Param: [ids]
* @Return: int
*/
public int deleteByIds(List<Long> ids) {
return cityMapper.deleteBatchIds(ids);
}
/***
* @Description: 根据名称删除 ,返回删除的条数
* @Param: [name]
* @Return: int
*/
public int deleteByName(String name) {
Map<String, Object> columnMap = new HashMap<>();
columnMap.put(getFieldName(City::getName), name);
return cityMapper.deleteByMap(columnMap);
}
/***
* @Description: 根据name更新country,先查询出ID,然后根据ID进行更新
* @Param: [name, country]
* @Return: boolean
*/
public int updateCountryByName(String name, String country) {
Map<String,Object> param=new HashMap<>();
param.put(getFieldName(City::getName),name);
return cityMapper.updateBatchById(cityMapper
.selectByMap(param)
.stream()
.map(city -> {
City updateCity = new City();
updateCity.setId(city.getId());
updateCity.setCountry(country);
return updateCity;
})
.collect(Collectors.toList()));
}
}33.7. 字段加密
利用自定义类型来实现字段的自动加解密。
33.7.2. 代码
通过在实体中自定义类型来实现,比如下面代码表示state字段存储到数据库时加密的。
@TableField("state")
private EncryptedColumn state; // 加密字段测试用例
@Test
public void testEncrypted(){
City city = new City();
city.setName("成都");
city.setState(EncryptedColumn.create("四川"));
city.setCountry("中国");
service.save(city);
System.out.println(cityMapper.selectById(city.getId()));
Assert.assertEquals("四川",cityMapper.selectById(city.getId()).getState().getValue());
}service.save(city); 产生的SQL是
INSERT INTO city ( name, state, country) VALUES ( '成都', '45ffd17bf74bad972a6bc45dc5c949fedacd773b5d4205f9888129d597fa6b47ae9c01054d4f', '中国')System.out.println(cityMapper.selectById(city.getId())); 输出的结果是
City{id=56, name='成都', state=EncryptedColumn{value='四川'}, country='中国'}可以看到存储 ("四川") 时已经被加密,通过mapper查询出的实体中被解密成功(可通过city.getState().getValue()`获取明文)。
33.8. JSON对象字段
支持自定义Java对象与数据表中字符串、JSON(MySQL>=5.7.8)字段之间的相互映射。
由于Mybatis限制,目前只支持JSON对象类型,不支持JSON数组类型(对应于Java中Array、List等)。
33.8.1. 配置
| @TableJSONField只有声明在由@TableName注解的DataObject中才生效。 |
33.8.2. 代码
@Data
public class AddressInfo implements Serializable {
private String province;
private String city;
private String street;
private String houseNum;
}
@Data
@TableName("t_user") //MyBatis Plus提供
public class UserDO {
@TableId(value = "id", type = AUTO)
private Long id;
@TableField(value = "name")
private String name;
@TableField(value = "address") //MyBatis Plus提供
@TableJSONField // Halo扩展
private AddressInfo address;
}
// 使用
public void addUser() {
UserDO userDO = new UserDO();
userDO.setName("halo user");
AddressInfo address = new AddressInfo();
address.setCity("SH");
address.setStreet("HaiLun");
userDO.setAddress(address);
userMapper.insert(userDO);
}33.8.3. 配置选项
-
halo.mybatis.enable-table-json-field: 是否启动JSON字段映射,默认启用。
-
halo.mybatis.table-json-field-package: 扫描包,默认扫描@SpringBooApplication所在包。
示例:
halo.mybatis.enable-table-json-field: true
halo.mybatis.table-json-field-package: org.xujin.halo.admin.db.dataobject33.9. 通用枚举字段
通用枚举由MyBatis Plus提供,Halo对其进行增强,支持自动扫描、多数据源自动适配等。
33.9.1. 配置
-
根据需要,定义枚举对象。 该枚举对象需实现IEnum [3]接口,或者使用@EnumValue [4]注解,具体使用方式,请参考 MyBatis Plus 通用枚举
-
在DataObject中,使用该枚举类型声明字段。
33.9.2. 代码
public enum UserStatus {
VALID((byte) 1, "有效"),
INVALID((byte) -1, "无效");
UserStatus(Byte value, String desc) {
this.value = value;
this.desc = desc;
}
@Getter
@EnumValue // 由MyBatis Plus提供
private Byte value;
@Getter
private String desc;
}
@Data
@TableName("t_user")
public class UserDO {
@TableId(value = "id", type = AUTO)
private Long id;
@TableField(value = "name")
private String name;
@TableField(value = "`status`")
private UserStatus status;
}
// 使用
public void addUser() {
UserDO userDO = new UserDO();
userDO.setName("halo user");
userDO.setStatus(UserStatus.VALID);
userMapper.insert(userDO);
}33.9.3. 配置选项
-
halo.mybatis.enable-table-enum-field: 是否启动通用枚举字段映射,默认启用。
-
mybatis-plus.type-enums-package: 扫描包,默认扫描@SpringBooApplication所在包。
示例:
halo.mybatis.enable-table-enum-field: true
mybatis-plus.type-enums-package: org.xujin.halo.admin33.10. Mybatis空Where SQL拦截
项目中经常出现因为Mybatis的动态where条件不满足导致实际sql语句的where条件为空,进而查询全表,当数据量比较大的时候,导致OOM的情况。比如当用户表的数据量为4千万时,如果load全表数据量将会导致OOM,如下图所示:
Halo Mybatis从1.2.0版本开始将会,增加如下的功能:
-
对空Where进行拦截判断
-
并支持开关关闭空where拦截
-
支持白名单设置,即在白名单中Mapper的方法将不会进行拦截
-
支持多数据源进行拦截check
开启Halo Mybatis空Where拦截的yml文件的配置如下代码所示:
halo:
mybatis:
#empty-where-intercept: false (1)
empty-where-white-list:
- org.xujin.halo.admin.tunnel.db.dao.AppMapper.queryHaloVersionChart (2)
- org.xujin.halo.admin.tunnel.db.dao.AppMapper.queryApp (3)| 1 | halo.mybatis.empty-where-intercept默认为true,即开启空Where条件判断,当为false时关闭空where拦截判断 |
| 2 | 表示配置白名单全限定Mapper类型.方法名 |
| 3 | 表示配置白名单全限定Mapper类型.方法名 |
| 不建议主动关闭空where拦截判断,如果需要设置白名单,可以根据配置设置白名单,白名单中的Mapper的方法将不会被拦截 |
33.11. Mybatis与tK PageHelper
Halo Mybatis封装的是Mybatis Plus,有些老项目中用了tk的PageHelper,支持混用。Halo Mybatis自带分页,不建议集成其它的分页组件。
33.12. Mybatis Plus开启乐观锁
乐观锁使用场景,当要更新一条记录的时候,希望这条记录没有被别人更新时使用。
乐观锁实现方式:
-
取出记录时,获取当前version
-
更新时,带上这个version
-
执行更新时, set version = newVersion where version = oldVersion
-
如果version不对,就更新失败
Halo Mybatis开启乐观锁yml文件的配置如下代码所示:
halo:
mybatis:
enableOptimistLock: true注解实体字段 @Version
@Version
private Integer version;| 更多内容可以访问:https://mp.baomidou.com/guide/optimistic-locker-plugin.html |
34. Halo Web
34.1. Halo Web功能
-
统一接口返回,返回码可根据应用情况扩展
-
全局异常处理,可配置异常钉钉提醒
-
接口日志打印,可配置日志是否脱敏、扩展脱敏规则
-
接口版本控制,自动兼容接口版本
-
支持跨域功能,默认关闭,需要时开启
-
无需引入Spring web相关的jar
-
使用@RestPathController注解取代@RestController和@RequestMapping
34.2. Halo Web的使用
34.2.1. Maven引入
1.引入Halo-Web依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.在需要使用的工程模块中,引入 web 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-web</artifactId>
</dependency>34.2.2. 配置使用
Halo Web的配置如下所示:
halo:
web:
logMark: defensor-web
dingTalkWebHook: https://oapi.dingtalk.com/robot/send?access_token=xxx
dingTalkMessageErrorMsgCodes: 400,500
dingTalkAtMobiles: 1992113xxxx
paramValidErrorMsgCode: 400
paramValidErrorMsgContent: 参数校验失败
bindErrorMsgCode: 400
bindErrorMsgContent: 参数绑定错误
sqlErrorMsgCode: 500
sqlErrorMsgContent: sql错误
systemErrorMsgCode: 500
systemErrorMsgContent: 系统错误
logDesensitizationEnabled: true
logMobileRegularDesensitizationEnabled: true
corsEnabled: true-
halo.web.logMark
配置接口打印的日志标记,默认值为"CONTROLLER",可配合LogFilter把接口日志输出到指定文件,方便在kibana上查看
-
halo.web.dingTalkWebHook\halo.web.dingTalkAtMobiles\halo.web.dingTalkMessageErrorMsgCodes
异常钉钉提醒相关配置,分别为群机器人url、提醒@人的手机号、需要提醒的错误码。
-
halo.web.paramValidErrorMsgCode
错误码相关配置,示例的配置为默认配置。
| 建议使用标准HTTP状态码,不要使用1、10001这种不标准的状态码。 |
-
halo.web.logDesensitizationEnabled
开启日志脱敏,默认为true。具体的脱敏策略需要和脱敏注解配合使用。
-
halo.web.logMobileRegularDesensitizationEnabled
开启日志中手机号正则匹配脱敏,默认为true。
| 正则表达式匹配手机号脱敏建议不要关闭,接口的入参和返回包含手机号的字段可能会遗漏脱敏注解。 |
34.3. 详细功能
34.3.1. @RestPathController
-
使用@RestPathController注解取代@RestController和@RequestMapping, 示例代码如下所示:
@RestPathController("/admin/app")
@Api("应用管理")
public class AppController {
@Autowired
private CommandBus commandBus;
}-
常规Controller,如下示例代码所示:
@RestController
@RequestMapping("/admin/app")
@Api("应用管理")
public class AppController {
@Autowired
private CommandBus commandBus;
}34.3.2. 接口统一返回
@PostMapping("/write-log")
public ResultData<UserOutVO> writeLog(@Valid @RequestBody TestInVO testInVO) {
UserOutVO user = new UserOutVO();
user.setUsername("张三");
user.setPassword("123xxx");
user.setEmail("123@qq.com");
return ResultData.success(user);
}{
"code": 200,
"msgCode": "200",
"msgContent": "success",
"data": {
"username": "张三",
"password": "123xxx",
"email": "123@qq.com"
}
}34.3.3. 跨域处理
CORS是一种允许当前域(domain)的资源(比如html/js/web service)被其他域(domain)的脚本请求访问的机制, 通常由于同域安全策略(the same-origin security policy)浏览器会禁止这种跨域请求。
Halo Web内置跨域功能,当应用需要跨域时开启跨域即可(默认关闭跨域功能)。YML配置如下所示:
halo:
web:
# CORS跨域配置,默认允许跨域
cors:
# 是否启用跨域,默认启用
enable: trueHalo框架内置了跨域的默认配置,如下Java代码所示:
@ConfigurationProperties(prefix = "halo.web.cros")
public class HaloWebCorsProperties {
/**
* 是否启用跨域,默认启用
*/
private boolean enable = true;
/**
* CORS过滤的路径,默认:/**
*/
private String path = "/**";
/**
* 允许访问的源
*/
private List<String> allowedOrigins = Collections.singletonList(CorsConfiguration.ALL);
/**
* 允许访问的请求头
*/
private List<String> allowedHeaders = Collections.singletonList(CorsConfiguration.ALL);
/**
* 是否允许发送cookie
*/
private boolean allowCredentials = true;
/**
* 允许访问的请求方式
*/
private List<String> allowedMethods = Collections.singletonList(CorsConfiguration.ALL);
/**
* 允许响应的头
*/
private List<String> exposedHeaders = Arrays.asList("Content-Type",
"X-Requested-With", "accept", "Origin", "Access-Control-Request-Method", "Access-Control-Request-Headers","token");
/**
* 该响应的有效时间默认为30分钟,在有效时间内,浏览器无须为同一请求再次发起预检请求
*/
private Long maxAge = 1800L;
}一般不需要进行特殊跨域配置,如果需要特殊跨域配置,yml文件配置如下:
halo:
web:
# CORS跨域配置,默认允许跨域
cors:
# 是否启用跨域,默认启用
enable: true
# CORS过滤的路径,默认:/**
path: /**
# 允许访问的源
allowed-origins: '*'
# 允许访问的请求头
allowed-headers: x-requested-with,content-type,token
# 是否允许发送cookie
allow-credentials: true
# 允许访问的请求方式
allowed-methods: OPTION,GET,POST
# 允许响应的头
exposed-headers: token
# 该响应的有效时间默认为30分钟,在有效时间内,浏览器无须为同一请求再次发起预检请求
max-age: 180034.3.4. 全局异常
全局异常处理是整个应用统一处理异常的地方。项目中只有框架(自己的框架或第三方框架)抛出的异常,业务异常,未知异常三种异常。 业务异常需要统一的处理设置msgCode,msgContent.框架异常和未知异常,由框架统一处理。
默认提供5个全局异常拦截
@ExceptionHandler(MethodArgumentNotValidException.class)
@ExceptionHandler(BindException.class)
@ExceptionHandler(SQLException.class)
@ExceptionHandler(BusinessException.class)
@ExceptionHandler(Throwable.class)-
MethodArgumentNotValidException
参数校验相关异常
@Data
public class TestInVO {
@NotNull(message = "name不能为空")
private String name;
}当接口入参name属性为null的时候,参数校验失败,全局异常处理会根据当前开发环境显示具体的message或者提示参数错误。
环境为pro
{
"code": 200,
"msgCode": "400",
"msgContent": "参数校验失败",
"data": null
}
环境为dev\fat\uat,会显示具体的参数错误message,方便定位问题
{
"code": 200,
"msgCode": "400",
"msgContent": "parameter error:name不能为空;",
"data": null
}-
BindException
msgCode和msgContent可以根据参数halo.web.bindErrorMsgCode和halo.web.bindErrorMsgContent配置
{
"code": 200,
"msgCode": "400",
"msgContent": "参数绑定错误",
"data": null
}-
SQLException
msgCode和msgContent可以根据参数halo.web.sqlErrorMsgCode和halo.web.sqlErrorMsgContent配置
{
"code": 200,
"msgCode": "500",
"msgContent": "sql错误",
"data": null
}-
BusinessException
自定义的业务异常,自定义业务异常可以通过自定义的返回码枚举来初始化,使用示例如下,
public enum ResultCodeEnum implements IResultCode {
LESSON_CLOSED("211","课堂已关闭");
private final String msgCode;
private final String msgContent;
...
}throw new BusinessException(ResultCodeEnum.LESSON_CLOSED);{
"code": 200,
"msgCode": "211",
"msgContent": "课堂已关闭",
"data": null
}-
Throwable
{
"code": 200,
"msgCode": "500",
"msgContent": "系统错误",
"data": null
}34.3.5. 开启404 Not Found 处理
默认情况下,Spring Boot是不会抛出404异常的,所以@ControllerAdvice也不能捕获到404异常。
但是我们可以通过如下的设置结合全局异常处理器,开启404统一由全局异常处理器处理。
-
application.yml文件配置如下:
spring:
mvc: # mvc.throw-exception-if-no-handler-found 和 resources.add-mappings设置 系统统一异常处理
throw-exception-if-no-handler-found: true
resources:
add-mappings: false-
application.properties配置如下所示:
spring.mvc.throw-exception-if-no-handler-found=true
spring.resources.add-mappings=false在Halo框架中,通过如下代码方式统一内置了404的统一处理方式: 代码查看地址: org.xujin.halo.HaloSpringApplicationRunListener.java
System.setProperty("spring.mvc.throw-exception-if-no-handler-found", "true");
System.setProperty("spring.resources.add-mappings", "false");| 上面的配置会关闭默认的静态资源路径映射,特别当前后端打包部署一起之后,默认关闭映射会让静态资源访问出现问题。如下图所示: |
但是可以通过扩展WebMvcConfigurer手动配置静态资源路径映射,从而能正常访问静态资源。
为了方便大家使用,Halo框架中扩展可通过属性文件的方式去根据自己实际情况进行配置:
halo:
web:
resource-handlers: |
/static/**=classpath:/static/static/
/index.html=classpath:/static/index.html如果使用了Halo Swagger或者自己开发的Swagger组件,还需要增加如下的配置,Swagger才可以正常使用
halo:
web:
resource-handlers: |
/static/**=classpath:/static/static/
/index.html=classpath:/static/index.html
/swagger-ui.html=classpath:/META-INF/resources/
/webjars/**=classpath:/META-INF/resources/webjars/| Halo Web中已经预设static和swagger的配置,若能正常访问,可以忽略本节。 |
*扩展内容: 上面的配置相当于如下扩展代码:
@Configuration
public class ResourceConfig implements WebMvcConfigurer {
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/static/**").addResourceLocations("classpath:/static/");
registry.addResourceHandler("/index.html").addResourceLocations("classpath:/static/index.html");
}
}34.3.6. 接口日志打印
@LogInfo
@PostMapping("/write-log")
public Result<UserOutVO> writeLog(@Valid @RequestBody TestInVO testInVO) {
UserOutVO user = new UserOutVO();
user.setUsername("脱敏君");
user.setPassword("123456");
user.setEmail("12345@qq.com");
user.setIdCard("19921137705");
user.setPhone("18888888888");
return Result.create(ResultCodeEnum.SUCCESS,user);
}@Data
public class UserOutVO {
private String username;
@Desensitization
private String idCard;
@Desensitization(strategy = PasswordStrategy.class)
private String password;
private String email;
@Desensitization(strategy = MobileStrategy.class)
private String phone;
}+-------defensor-web----------
| userId:null;执行方法:public org.xujin.halo.dto.ResultData<org.xujin.halo.web.vo.UserOutVO> org.xujin.halo.web.controller.LogController.writeLog(org.xujin.halo.web.vo.TestInVO)
| 参数依次为:
| 0:{"name":"*******7706"}
| 返回值:{"code":200,"data":{"email":"12345@qq.com","idCard":"","password":"****","phone":"*******8888","username":"脱敏君"},"msgCode":"200","msgContent":"success"}
| 耗时(毫秒):93
\__________________系统默认开启日志脱敏以及手机号正则匹配脱敏。
-
如何使用脱敏
使用@Desensitization注解,该注解默认使用的脱敏策略为NonPrint策略,系统还包括邮箱、手机号脱敏策略。
也可以自定义脱敏策略。实现IDesensitizationStrategy接口即可。
public class PasswordStrategy implements IDesensitizationStrategy {
@Override
public Object handleDesensitization(Object value) {
return "****";
}
}@Desensitization(strategy = PasswordStrategy.class)
private String password;以上关于日志脱敏,是通过fastjson的ValueFilter实现,对象转换为json字符串,再打印,就脱敏了。
UserOutVO user = new UserOutVO();
user.set...
LOGGER.info(JsonUtils.toJSONStringWithDesensitize(user));34.3.7. 接口版本控制
在前后端分离、rest接口盛行的当下,接口的版本控制是一个成熟的系统所应该拥有的。 web模块提供的版本控制,可以方便我们快速构建一个基于版本的api接口。
@RestController
@RequestMapping("/version/{version}")
public class Version1Controller {
@ApiVersion(1)
@RequestMapping("/test")
public String test1(){
return "v1";
}
@ApiVersion(4)
@RequestMapping("/test")
public String test4(){
return "v4";
}
}@ApiVersion(2)
@RestController
@RequestMapping("/version/{version}")
public class Version2Controller {
@RequestMapping("/test")
public String test2(){
return "v2";
}
}/version/v0/test
不存在
/version/v1/test
返回v1
/version/v2/test
返回v2
/version/v3/test
返回v2
/version/v4/test
返回v4
/version/v6/test
返回v4| 请配合使用注解@ApiVersion和url中{version};默认自动向下兼容最大的接口版本; |
34.4. Halo Assert
以优雅的 Assert(断言) 方式来校验业务的异常情况,只关注业务逻辑,而不用花费大量精力写冗余的 try catch 代码块。
想必 Assert(断言) 大家都很熟悉,比如 Spring框架中的org.springframework.util.Assert,在我们写测试用例的时候经常会用到,例如如下代码:
@Test
public void test1() {
User user = userDao.selectById(userId);
Assert.notNull(user, "用户不存在.");
}
@Test
public void test2() {
// 另一种写法
User user = userDao.selectById(userId);
if (user == null) {
throw new IllegalArgumentException("用户不存在.");
}
}| 如上述代码所示,第一种判定非空的写法很优雅,第二种写法 if {…} 代码块相对丑陋的。 |
Assert.notNull()底层实现代码如下所示:
public abstract class Assert {
public Assert() {
}
public static void notNull(@Nullable Object object, String message) {
if (object == null) {
throw new IllegalArgumentException(message);
}
}
}| 从上述代码Assert代码本质就是把if {…} 封装了一下,虽然是很简单的封装,但不可否认的是代码整洁度至少提升了一个档次。那Halo框架是否能模仿org.springframework.util.Assert也写一个断言类, 不过断言失败后抛出的异常不是IllegalArgumentException 这些内置异常,而是Halo框架自己定义的异常。 |
34.4.1. Halo Assert的实现
@Getter
@AllArgsConstructor
public enum CommonResponseEnum implements BusinessExceptionAssert {
/**
*
*/
CMD_NOT_NULL("7001", "cmd不能为null"),
/**
*
*/
LICENCE_NOT_FOUND("7002", "Licence not found.")
;
/**
* 返回码
*/
private String code;
/**
* 返回消息
*/
private String message;
@Override
public String getMsgCode() {
return String.valueOf(code);
}
@Override
public String getMsgContent() {
return message;
}
}上面的Assert断言方法是使用接口的默认方法定义的,然后有没有发现当断言失败后,抛出的异常不是具体的某个异常, 而是交由2个newException接口方法提供。因为业务逻辑中出现的异常基本都是对应特定的场景,比如根据用户id获取用户信息, 查询结果为null,此时抛出的异常可能为UserNotFoundException,并且有特定的异常码(比如7001)和异常信息“用户不存在”。 所以具体抛出什么异常,有Assert的实现类决定。
34.4.2. Enum 和 Halo Assert结合
不使用Enume和Halo Assert的代码如下所示:
private void checkNotNull(Licence licence) {
if (licence == null) {
throw new LicenceNotFoundException();
// 或者这样
throw new BusinessException(7001, "Bad licence type.");
}
}使用了Halo Assert之后的代码如下所示:
/**
* 校验{@link Licence}存在
* @param licence
*/
private void checkNotNull(Licence licence) {
ResponseEnum.LICENCE_NOT_FOUND.assertNotNull(licence);
}使用枚举类结合(继承)Assert,只需根据特定的异常情况定义不同的枚举实例, 如上面的BAD_LICENCE_TYPE、LICENCE_NOT_FOUND,就能够针对不同情况抛出特定的异常(这里指携带特定的异常码和异常消息), 这样既不用定义大量的异常类,同时还具备了断言的良好可读性。
34.4.3. 统一404返回
当请求没有匹配到控制器的情况下,会抛出NoHandlerFoundException异常,但其实默认情况下不是这样,默认情况下会出现类似如下页面:
这个页面是如何出现的呢?实际上,当出现404的时候,默认是不抛异常的,而是 forward跳转到/error控制器,spring也提供了默认的error控制器。
spring.mvc.throw-exception-if-no-handler-found=true
spring.resources.add-mappings=false34.4.4. 使用Halo Assert
下面的代码示例通过定义枚举快速Assert。
CommonResponseEnum.CMD_NOT_NULL.assertNotNull(cmd);CommonResponseEnum代码如下所示:
@Getter
@AllArgsConstructor
public enum CommonResponseEnum implements BusinessExceptionAssert {
/**
*
*/
CMD_NOT_NULL("7001", "cmd不能为null"),
/**
*
*/
LICENCE_NOT_FOUND("7002", "Licence not found.")
;
/**
* 返回码
*/
private String code;
/**
* 返回消息
*/
private String message;
@Override
public String getMsgCode() {
return String.valueOf(code);
}
@Override
public String getMsgContent() {
return message;
}
}35. Halo Swagger
35.1. Halo Swagger的功能
-
兼容swagger功能,常见swagger文档描述可配置
-
可手动配置关闭swagger。在生产环境下,默认就会关闭swagger
-
可配置多包扫描,也支持默认包扫描功能
35.2. Halo Swagger的使用
35.2.1. Maven引入
1.引入Halo-Swagger依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.在需要使用的工程模块中,引入 swagger 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-swagger</artifactId>
</dependency>35.2.2. 配置使用
1.Halo Swagger的基本配置如下所示:
halo:
swagger:
enabled: true
api:
name: Halo Admin
title: Halo Admin
description: 中台管控平台
version: 2.0.8
conractUser: jin.xu
conractUrl: http://xujin.org
conractEmail: Software_King@qq.com
basePackages: org.xujin.halo.admin.controller-
halo.swagger.enabled
配置的值为是否激活swagger,true为激活,false为关闭。
| 考虑到API安全性,当spring.profiles.active(或者java启动属性env)配置为pro或者product时,不管halo.swagger.enabled为true或者false,swagger功能都会关闭。 |
使用Halo Swagger后,请勿再使用Swagger原生注解@EnableSwagger2,否则,halo.swagger.enabled将不受控制。
-
halo.swagger.api.basePackages
| 接口扫描包配置。默认不配置的情况下,系统会扫描标注@SpringBootApplication启动类所在包路径下的所有接口。 也可以手动指定只扫描哪些包,多个包名用英文逗号隔开,例如:org.xujin.openapi,net.qingcloud.admin |
如果配置错误,应用启动会出现提示:配置→halo.swagger.api.basePackages格式有误,请配置正确的包路径,多个用英文逗号隔开
2.下面是增加了全局的操作参数配置
halo:
swagger:
enabled: true
api:
name: Halo Admin
title: Halo Admin
description: 中台管控平台
version: 2.0.8
conractUser: jin.xu
conractUrl: http://xujin.org
conractEmail: Software_King@qq.com
basePackages: org.xujin.halo.admin.controller
globalOperationParameters:
- name: XAuthorization #参数名
description: Token Request Header #描述信息
parameterType: header #指定参数存放位置,参考ParamType:(header,query,path,body,form)
dataType: String #数据类型
required: false
# 测试接口时,自动填充token的值
defaultValue:当应用启动之后,输入网址 http://ip:端口/swagger-ui.html
36. Halo MapStruct
Halo框架中有DO,CO,Entity,Value Object等POJO,为了代码防腐和架构治理各种XO之间会相互转换。。 Spring BeanUtils进行类复制时,每次进行反射查询对象的属性列表, 非常缓慢。在MapStruct没有出来之前Orika时最佳可选方案。 在Halo Util中内置了org.xujin.halo.utils.reflect.BeanMapper,简单封装orika, 实现深度Bean Copy。
MapStruct问世时候,从各方面对比,都相当优秀。因此Halo框架对其进行定制,作为统一的Bean Copy工具。
36.1. 什么是Halo MapStruct
MapStruct 是一个自动生成 bean mapper 类的代码生成器。MapStruct 还能够在不同的数据类型之间进行转换。 Github 地址:https://github.com/mapstruct
性能对比:https://segmentfault.com/a/1190000021004596
文档地址:https://mapstruct.org/documentation/stable/reference/html/
36.2. halo MapStruct的使用
36.2.1. Maven引入
-
引入Halo-job依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 halo job 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-mapstruct</artifactId>
</dependency>38. Halo Test
38.1. Halo Test的功能
为了减少单元测试的工作量,Halo Test下对Spring Boot单元测试的所需的依赖统一管理和提供一些Base层的功能.
-
无需引入Spring Test相关的jar
-
引入halo-starter-test即可
| halo-starter-test只引入了spring-test和spring-boot-starter-test(依赖于Junit4). 由于Halo基于Spring Boot 2.x开发,因此默认包含Junit4. |
38.2. Halo Test的使用
38.2.1. Maven引入
1.引入Halo-Test依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.在需要使用的工程模块中,引入halo-starter-test模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>业务应用不需要引入如下的jar
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>38.2.2. Halo Test使用
1.如下所示,编写CommonTest.
@SpringBootTest(classes = HaloBasicApplication.class)
@RunWith(SpringRunner.class)
public abstract class CommonTest {
}| 其中classes = HaloBasicApplication.class是Spring Boot主入口程序Java类. |
2.编写对应的测试类继承CommonTest
public class CmdTest extends CommonTest {
@Autowired
private CommandBus commandBus;
/**
* 测试写命令
*/
@Test
public void testCmdWrite() {
AddAppCmd addAppCmd=new AddAppCmd();
addAppCmd.setAppId("111");
ResultData<Long> resultData=commandBus.send(addAppCmd);
Assert.assertEquals((long)resultData.getData(),1L);
}
/**
* 测试读命令
*/
@Test
public void testCmdRead() {
QueryAppCmd queryAppCmd=new QueryAppCmd();
queryAppCmd.setId(1L);
ResultData<AppCO> resultData= commandBus.send(queryAppCmd);
Assert.assertEquals(resultData.getData().getAppId(),"defensor");
}
}39. Halo MongoDB
39.1. 什么是Halo MongoDB
Spring Data MongoDB为面向 MongoDB 的开发提供了一套基于 Spring 的编程模型,在 Spring Boot 中使用 spring-boot-starter-data-mongodb 可以很方便的引入 Spring Data MongoDB 以及MongoDB Java Driver。
然而,Spring Data MongoDB 只提供了最简单的 MongoDB 客户端选项,不支持使用连接池,多数据源配置,集群等MongoDB高级特性。
Halo MongoDB是基于spring-boot-starter-data-mongodb封装的定制的Starter,底层使用的是http://mongodb.github.io/mongo-java-driver/3.6[MongoDB Java Driver 3.6.4^]
功能如下:
-
无缝支持Spring Boot中MongoDB的使用,无需显示引入spring-boot-starter-data-mongodb.
-
可以通过Halo MongoDB设置相关的连接池信息(Spring Boot对MongoDB的封装没有提供连接池相关的选项设置)
-
支持多数据源配置(Halo: 2.0.0-SNAPSHOT)
39.2. 使用Halo MongoDB
39.2.1. Maven引入Halo MongoDB
-
引入Halo MongoDB依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 Halo MongoDB模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-mongodb</artifactId>
</dependency>39.2.2. 在属性文件yml或properties配置Halo MongoDB
-
单数据源模式(默认)
在yml文件中配置如下信息,使用Halo MongoDB
spring:
application:
name: defensor-mongodb
data:
mongodb:
host: 10.84.23.71:27017
database: halo-mongodb
username: 用户名
password: 密码
#uri: mongodb://用户名:密码@ip:端口/数据库 (1)
halo:
mongodb:
enabled: true (2)
heartbeat-connect-timeout: 30000 (3)-
多数据源模式
halo:
mongodb:
multi:
enabled: true #启用多数据源模式,默认不开启
dbs:
customDb1: # 自定义数据源名称示例
uri: mongodb://127.0.0.1:27017/db1
connectTimeout: 10000 (3)
customDb2: # 自定义数据源名称示例
uri: mongodb://127.0.0.1:27017/db2|
单、多数据源模式不能同时启用,否则会启动报错。 即halo.mongodb.enabled与halo.mongodb.multi.enabled不能同时为true。 |
| 1 | MongoDB 的连接字符串,当配置了 uri 时,将忽略 addresses、database、username 等连接相关的配置项,而直接使用 uri 建立连接。 |
| 2 | 只有当halo.mongodb.enabled=true才开启Halo MongoDB,否则使用Spring Boot默认对MongoDB的封装,如下图所示: |
| 1 | 关于 MongoDB Java Driver 客户端选项的详细说明可以参考下面汇总的表格。 |
|
注:由于官方已对 socket-keep-alive 选项废弃,因此 Halo MongoDB不建议也不提供配置选型。 |
| 参数名 | 默认参数值 | 参数说明 |
|---|---|---|
ConnectionsPerHost |
100 |
设置每台主机的最大连接数 |
Description |
null |
|
RequiredReplicaSetName |
null |
设置群集所需的副本集名称 |
ConnectTimeout |
10000 |
设置连接超时 |
HeartbeatConnectTimeout |
20000 |
设置用于群集心跳的连接的连接超时 |
HeartbeatFrequency |
10000 |
设置心跳频率。这是驱动程序尝试确定群集中每个服务器当前状态的频率。默认值为10,000毫秒 |
HeartbeatSocketTimeout |
20000 |
设置用于群集心跳的连接的套接字超时 |
LocalThreshold |
15 |
设置本地阈值 |
MaxConnectionIdleTime |
0 |
设置池连接的最大空闲时间 |
MaxConnectionLifeTime |
0 |
设置池连接的最长生存期 |
MaxWaitTime |
120000 |
设置线程阻塞等待连接的最长时间 |
MinConnectionsPerHost |
0 |
设置每台主机的最小连接数 |
MinHeartbeatFrequency |
500 |
设置最小心跳频率。如果驱动程序必须频繁地重新检查服务器的可用性,它至少会在上次检查后等待这么长时间,以避免浪费精力。默认值为500毫秒 |
ServerSelectionTimeout |
30000 |
以毫秒为单位设置服务器选择超时,这定义了驱动程序在引发异常之前等待服务器选择成功的时间。 值0表示如果没有服务器可用,它将立即超时。负值意味着无限期等待。 |
SocketTimeout |
0 |
设置socket超时 |
threadsAllowedToBlockForConnectionMultiplier |
5 |
设置允许阻塞等待连接的线程数的乘数。 |
socketKeepAlive |
设置是否启用套接字保持活动 |
|
sslEnabled |
设置是否使用SSL。将此设置为true也会将SocketFactory设置为sLSocketFactory。GetDefault ( )并将此设置为false会将SocketFactory设置为SocketFactory。GetDefault ( ) |
|
sslInvalidHostNameAllowed |
定义是否允许无效主机名。默认为false。在将此设置为真之前要小心,因为这会使应用程序容易受到中间人攻击 |
|
readPreference |
设置读取首选项 |
|
writeConcern |
设置写入关注点。 |
|
readConcern |
设置读取关注点。 |
|
codecRegistry |
设置编解码器注册表请注意,DB和DBCollection的实例不使用注册表,因此无需在注册表中包含DBObject的编解码器。 |
|
addCommandListener |
添加给定的命令侦听器。 |
|
socketFactory |
设置socket工厂。 |
|
cursorFinalizerEnabled |
设置是否启用游标终结器 |
|
alwaysUseMBeans |
设置驱动程序注册的JMX Beans是否应该始终是MBean,而不管VM是Java 6还是更高版本。如果为false,如果虚拟机为Java 6或更高版本,驱动程序将使用MXBeans,如果虚拟机为Java 5,则使用mbean。 |
|
dbDecoderFactory |
设置解码器工厂 |
|
dbEncoderFactory |
设置编码器工厂 |
|
legacyDefaults |
将默认值设置为MongoOptions中的值 |
39.2.4. 使用MongoTemplate操作MongoDB
-
单数据源模式
@Autowired
private MongoTemplate mongoTemplate;-
多数据源模式
多数据源模式下,halo mongoDB会根据配置的数据源信息,自动在Spring容器中,注册MongoTemplate bean,只需在代码中注入对应的bean即可使用。
多个数据源中,第一个声明的数据源对应的MongoTemplate为@Primary。
MongoTemplate bean 命名规则:数据源名称 + MongoTemplate,例 customDb1MongoTemplate,customDb2MongoTemplate。
@Autowired
@Qualifier("customDb1MongoTemplate")
private MongoTemplate customDb1MongoTemplate;
@Autowired
@Qualifier("customDb2MongoTemplate")
private MongoTemplate customDb2MongoTemplate;由于Halo框架基于Spring Boot 2.4.1版本开发,更多MongoTemplate的使用细节可以查看 Spring Data 2.4.1.RELEASE
40. Halo ElasticSearch 6.3.2
40.1. 什么是Halo ES 6
Halo ES6是基于ES 6.3.2封装的Spring Boot Starter。并提供了HaloEsTemplate并封装了常用的操作API,从而简化ES的使用方式。
40.2. 使用Halo ES 6
40.2.1. Maven引入Halo ES 6
-
引入Halo ES 6依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 Halo ES6 模块即可,如下所示:
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-es6</artifactId>
</dependency>40.2.2. 在yml文件中配置Halo ES6
-
精简版yml配置,不需要修改默认配置:
halo:
es:
host: 10.31.53.185
port: 9300
cluster-name: zm-elk-test-
使用Halo ES6,在yml文件中完整的配置如下所示
halo:
es:
host: 10.31.53.185 (1)
port: 9300 (2)
cluster-name: zm-elk-test (3)
transport:
ignore-cluster-name: false (4)
nodes-sampler-interval: 5s (5)
ping-timeout: 5s (6)
sniff: true (7)| 1 | es主机 必填 |
| 2 | port的端口,默认为9300,必填 |
| 3 | 集群名称,必填 |
| 4 | 是否忽略集群名称,非必填 |
| 5 | 嗅探集群节点的间隔时间,默认5秒,非必填可自定义 |
| 6 | Ping节点的超时时间,默认是5秒,非必填可自定义 |
| 7 | 是否开启集群嗅探,在Halo ES6中默认开启,非必填可自定义 |
在org.elasticsearch.client.transport.TransportClient.java文件中有4个重要参数,如下代码所示:
public abstract class TransportClient extends AbstractClient {
public static final Setting<TimeValue> CLIENT_TRANSPORT_NODES_SAMPLER_INTERVAL =
Setting.positiveTimeSetting("client.transport.nodes_sampler_interval", timeValueSeconds(5), Setting.Property.NodeScope);
public static final Setting<TimeValue> CLIENT_TRANSPORT_PING_TIMEOUT =
Setting.positiveTimeSetting("client.transport.ping_timeout", timeValueSeconds(5), Setting.Property.NodeScope);
public static final Setting<Boolean> CLIENT_TRANSPORT_IGNORE_CLUSTER_NAME =
Setting.boolSetting("client.transport.ignore_cluster_name", false, Setting.Property.NodeScope);
public static final Setting<Boolean> CLIENT_TRANSPORT_SNIFF =
Setting.boolSetting("client.transport.sniff", false, Setting.Property.NodeScope);
}| 在上述代码中可以看到,client.transport.nodes_sampler_interval和client.transport.ping_timeout默认值均为5s,client.transport.ignore_cluster_name和client.transport.sniff均为false, |
40.2.3. 使用HaloEsTemplate操作ES
1.使用HaloEsTemplate非常简单,如下代码所示,依赖注入即可:
@Autowired
private HaloEsTemplate haloEsTemplate; (1)
@Autowired
private TransportClient transportClient;| 1 | 依赖注入haloEsTemplate可以使用HaloEs6的功能. |
<2>如果觉得haloEsTemplate提供的API满足不了需求,可以通过transportClient使用底层的接口操作ES。
2.HaloEsTemplate提供的方法如下所示:
/**
* 批量插入数据
* @param esBasicInfo
* @param object
* @return
* @throws IOException
*/
public int addBatchData(ESBasicInfo esBasicInfo, Object object) throws IOException;
/**
* 增加数据
* @param esBasicInfo
* @param object
* @return
* @throws IOException
*/
public boolean addData(ESBasicInfo esBasicInfo, Object object) throws IOException;
/**
* 分析搜索
* @param clazz
* @param response
* @param <T>
* @return
* @throws IOException
*/
public <T> List<T> analyzeSearchResponse(Class<T> clazz, SearchResponse response) throws IOException;
/**
* 创建索引
* @param index
* @return
*/
public boolean createIndex(String index);
/**
* 创建Mapping
* @param index
* @param type
* @param mapping
* @return
* @throws IOException
*/
public boolean createMapping(String index, String type, XContentBuilder mapping) throws IOException;
/**
* 批量删除数据
* @param esBasicInfo
* @return
*/
public int deleteBatchData(ESBasicInfo esBasicInfo);
/**
* 删除数据
* @param esBasicInfo
* @return
*/
public boolean deleteData(ESBasicInfo esBasicInfo);
/**
* 删除索引
* @param index
* @return
*/
public boolean deleteIndex(String index);
/**
* 查询
* @param index
* @param queryCondition
* @param type
* @return
*/
public SearchResponse executeQuery(String index, QueryCondition queryCondition, String... type);
/**
* 查询所有的Mapping
* @param index
* @return
* @throws IOException
*/
public List<Map<String, Object>> getAllMapping(String index) throws IOException;
/**
*
* Mapping 是定义文档及其包含的字段是如何存储和索引的过程
* @param index
* @param type
* @return
* @throws IOException
*/
public String getMapping(String index, String type) throws IOException;
/**
* 返回高亮结果
* @param esBasicInfo
* @param queryCondition
* @param highLight
* @return
*/
public List<Map<String, Object>> highLightResultSet(ESBasicInfo esBasicInfo, QueryCondition queryCondition,
HighLight highLight);
/**
* 是否存在索引
* @param index
* @return
*/
public boolean isExistedIndex(String index);
/**
* 查询返回泛型
* @param esBasicInfo
* @param clazz
* @param <T>
* @return
* @throws IOException
*/
public <T> T query(ESBasicInfo esBasicInfo, Class<T> clazz) throws IOException;
/**
* 批量更新数据
* @param esBasicInfo
* @param object
* @return
* @throws IOException
*/
public int updateBatchData(ESBasicInfo esBasicInfo, Object object) throws IOException;
/**
* 更新数据
* @param esBasicInfo
* @param object
* @return
* @throws IOException
*/
public boolean updateData(ESBasicInfo esBasicInfo, Object object) throws IOException;41. Halo ElasticSearch 7.2.1
41.1. 什么是Halo ES7
Halo ES7是基于ES的7.2.1版本封装的Spring Boot Starter。支持设置多个ES Server的地址,可以设置timeout和socket timeout,开箱即用,通过依赖注入RestHighLevelClient即可操作ES7.
41.2. 使用Halo ES7
41.2.1. Maven引入Halo ES7
-
引入Halo ElasticSearch依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 Halo Elastic Search6 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-es7</artifactId>
</dependency>
<!-- 显示引入elasticsearch 7.2.1 --> (1)
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.2.1</version>
</dependency>| 1 | 由于Halo Framework基于Spring Boot 2.4.1版本开发,spring-boot-dependencies中内置了elasticsearch的version为5.1.64因此需要强制引入排除低版本,可以查看 spring-boot-dependencies 2.0.8中的ES版本 |
41.2.2. 在属性文件yml或properties配置Halo ES
在yml文件中配置如下信息,使用Halo ES7
halo:
es:
hosts:
- 10.81.164.95:9200 (1)
- 10.81.164.95:9200 (2)
#time-out: 1000 (3)
#socket-timeout: 30000 (4)| 1 | Elastic Search 7.2.1 机器1 |
| 2 | Elastic Search 7.2.1 机器2 |
| 3 | Elastic Search连接超时时间默认1s,非必填,可自定义设置 |
| 4 | Elastic Search Socket超时时间默认30s,非必填,可以自定义设置 |
[NOTE]ES 7.2.1 更多自定义设置可以参考如下文档链接。 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.2/_timeouts.html
41.2.3. 使用RestHighLevelClient操作ES7
使用RestHighLevelClient操作ES7,具体可以看官方API文档,文档地址如下所示:
42. Halo Job
42.1. Halo Job的功能
halo job主要对xxl-job-core包简单封装成spring boot starter,方便通过Spring Boot方式开发xxl-job的executor
| Halo Job基于xxl-job的2.0.2封装,使用的时候,请注意check对应的Server端版本。 |
42.2. halo job的使用
42.2.1. Maven引入
-
引入Halo-job依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 halo job 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-job</artifactId>
</dependency>42.3. halo job的使用
42.3.1. xxl-job可用环境
xxl-job的可用环境填写对应的即可,示例如下所示:
-
UAT环境:
http://localhost:8080/xxl-job-admin/
-
生产环境:
http://localhost:8080/xxl-job-admin
42.3.2. 修改xxl-job配置
添加以下xxl-job配置,也可不配置,不配置则使用默认值。
halo.job:
admin:
admin-addresses: http://localhost:8080/xxl-job-admin
executor:
app-name: xxl-job-spring-boot-starter-example #默认为 xxl-job-executor
access-token: #默认为空
log-path: logs/applogs/xxl-job/jobhandler #默认为 logs/applogs/xxl-job/jobhandler
log-retention-days: 10 #默认为 10
ip: #默认为空
port: 9999 #默认为 999942.3.3. 定义Job执行器
示例Job执行器代码如下所示:
@JobHandler(value="haloJobHandler")
@Component
public class HaloJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return SUCCESS;
}
}43. Halo AliMQ
43.1. Halo AliMQ的功能
Halo AliMQ对阿里的RocketMQ进行封装,通过配置化的方式和Spring Boot进行集成。为RocketMQ提供的消息类型提供全面支持,
包括:普通消息、定时和延时消息、顺序消息、事务消息。
43.3. Halo AliMQ的使用
43.3.1. Maven引入
1、 引入halo-alimq依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2、 在需要使用的工程模块中,引入 halo-alimq 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-alimq</artifactId>
</dependency>43.3.2. 配置
Halo AliMQ相关配置属性在halo.alimq命名空间下。
-
生产者配置
halo:
alimq:
enabled: true # 启用Halo AliMQ总开关,默认启用
namesrv-addr: http://onsaddr.xxxx.mq-internal.aliyuncs.com:8080 # 公共配置
access-key: LTAI4FofsQVbk # 公共配置
secret-key: EOMlH59FGBHVz # 公共配置
group-id: GID_PRODUCER_XUJIN_TEST # 公共配置
producer: # 普通消息、定时和延时消息 生产者
enabled: true # 普通消息、定时和延时消息 生产者开关,默认不启用
access-key: LTAI4FofXsQVbk # 配置则覆盖公共配置,未配则用公共配置
secret-key: EOMlHeFbMm159 # 配置则覆盖公共配置,未配则用公共配置
group-id: GID_PRODUCER_XUJIN_TEST # 配置则覆盖公共配置,未配则用公共配置
orderproducer: # 顺序消息生产者
enabled: true # 顺序消息生产者开关,默认不启用
access-key: LTAI4Vbk # 配置则覆盖公共配置,未配则用公共配置
secret-key: EOMl59HVz # 配置则覆盖公共配置,未配则用公共配置
group-id: GID_PRODUCER_XUJIN_TEST # 配置则覆盖公共配置,未配则用公共配置
transactionproducer: #事务消息生产者
enabled: true # 事务消息生产者开关,默认不启用
access-key: LTAIQVbk # 配置则覆盖公共配置,未配则用公共配置
secret-key: EOMlHeF3 # 配置则覆盖公共配置,未配则用公共配置
group-id: GID_PRODUCER_XUJIN_TEST # 配置则覆盖公共配置,未配则用公共配置
local-transaction-checker: org.xujin.alimq.provider.producer.LocalTransactionCheckerImpl # 回查本地事务接口实现,由Broker回调Producer
-
消费者配置
halo:
alimq:
enabled: true # 启用Halo AliMQ总开关,默认启用
namesrv-addr: http://onsaddr.xxxxxxxx.aliyuncs.com:8080 # 公共配置
access-key: LTAI4Fs # 公共配置
secret-key: f1gpL4 # 公共配置
group-id: GID_CONSUMER_XUJIN_TEST # 公共配置
consumer: # 普通消息、定时和延时消息、事务消息 消费者
enabled: true # 普通消息、定时和延时消息、事务消息 消费者开关,默认不开启
access-key: LTAI4F # 配置则覆盖公共配置,未配则用公共配置
secret-key: f1gpL4 # 配置则覆盖公共配置,未配则用公共配置
group-id: GID_CONSUMER_XUJIN_TEST # 配置则覆盖公共配置,未配则用公共配置
orderconsumer: # 顺序消息消费者
enabled: true # 顺序消息消费者开关,默认不开启
access-key: LTAI4Fs # 配置则覆盖公共配置,未配则用公共配置
secret-key: f1gpL4U # 配置则覆盖公共配置,未配则用公共配置
group-id: GID_CONSUMER_XUJIN_TEST # 配置则覆盖公共配置,未配则用公共配置| 按需配置:用到哪种类型的消息,配置该消息类型对应的生产者、消费者,不用的不要开启,以免发生意想不到的错误。 对同一个topic,普通消息(包含定时和延时消息)、顺序消息、事务消息不要混用,以免发生意想不到的错误。 |
43.3.3. 使用
43.3.3.1. 生产者
配置后,对应消息类型的生产者bean会自动装配。使用时,只需在代码中注入对应的bean即可。
-
普通消息、定时和延时消息生产者
@Autowired
private com.aliyun.openservices.ons.api.Producer producer;-
顺序消息生产者
@Autowired
private com.aliyun.openservices.ons.api.order.OrderProducer orderProducer;-
事务消息生产者
@Autowired
private com.aliyun.openservices.ons.api.transaction.TransactionProducer transactionProducer;注入生产者bean之后,组装Message实例,通过生产者bean的send方法即可发送消息。
43.3.3.2. 消费者
消费消息时,普通消息、定时和延时消息、事务消息消费者需实现MessageListener,
顺序消息消费者需实现MessageOrderListener。
并在Listener实现类加上@AliMqMessageListener注解,通过该注解可以指定Topic和Tag。
-
普通消息、定时和延时消息、事务消息消费者
import com.aliyun.openservices.ons.api.Action;
import com.aliyun.openservices.ons.api.ConsumeContext;
import com.aliyun.openservices.ons.api.Message;
import com.aliyun.openservices.ons.api.MessageListener;
@AliMqMessageListener(topic = "HALO_XUJIN_TEST", tags = {"tag1", "tag2", "tag3"})
public class ConsumerTest implements MessageListener {
@Override
public Action consume(Message message, ConsumeContext context) {
System.out.println("Receive: " + message.getTopic() + ", " + new String(message.getBody()));
return Action.CommitMessage;
}
}-
顺序消息消费者
import com.aliyun.openservices.ons.api.Message;
import com.aliyun.openservices.ons.api.order.ConsumeOrderContext;
import com.aliyun.openservices.ons.api.order.MessageOrderListener;
import com.aliyun.openservices.ons.api.order.OrderAction;
@AliMqMessageListener(topic = "HALO_XUJIN_TEST", tags = {"tag1"})
public class OrderConsumerTest implements MessageOrderListener {
@Override
public OrderAction consume(Message message, ConsumeOrderContext context) {
System.out.println("Receive order msg: " + message.getTopic() + ", " + new String(message.getBody()));
return OrderAction.Success;
}
}44. halo Redis
44.1. halo Redis的功能
Spring Boot简化了Spring Data Redis(简称SDR)的引入,只要引入spring-boot-starter-data-redis之后会自动下载相应的Spring Data Redis和Jedis客户端,可以减少版本这块的冲突,当然,如果要引入别的版本也是可以的。 版本控制全部交由Parent引入的Spring Boot节点进行管理,而Halo管控了Spring Boot的版本,因此无需关心版本使用即可。
Halo Redis基于 spring-data-redis 2.3.0.RELEASE,简单封装成spring boot starter。
spring-data-redis没有集成redisson,默认集成了jedis,lettuce两种客户端,如果需要使用redisson,可以使用另外一个基础组件halo-starter-redisson。
44.2. Halo Redis的使用
44.2.1. Maven引入
1、 引入halo-redis依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2、 在需要使用的工程模块中,引入 halo-redis 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-redis</artifactId>
</dependency>44.2.2. 配置
halo Redis的配置方式与 Spring官方的配置方式保持一致,目前支持
-
单节点模式配置示例
-
集群模式配置示例
spring:
application:
name: defensor-redis
redis:
password: ******
timeout: 5000
cluster:
nodes: 10.11.50.62:6380,10.11.50.63:6381,10.10.50.64:6382| 查看源码 org.springframework.data.redis.connection.RedisClusterConfiguration#RedisClusterConfiguration(org.springframework.core.env.PropertySource<?>) 可以看到spring.redis.cluster.nodes=127.0.0.1:23679,127.0.0.1:23680,127.0.0.1:23681和spring.redis.cluster.max-redirects=3 |
更多属性配置如下:
单节点配置:
# REDIS(RedisProperties)
# 连接工厂使用的数据库索引。
spring.redis.database=0
# 连接URL,将覆盖主机,端口和密码(用户将被忽略),例如:redis://user:password@example.com:6379
spring.redis.url=
# Redis服务器主机。
spring.redis.host=localhost
# Redis服务器端口。
spring.redis.port=6379
# 登录redis服务器的密码。
spring.redis.password=
# 启用SSL支持。
spring.redis.ssl=false
# 池在给定时间可以分配的最大连接数。使用负值无限制。
spring.redis.pool.max-active=8
# 池中“空闲”连接的最大数量。使用负值表示无限数量的空闲连接。
spring.redis.pool.max-idle=8
# 连接分配在池被耗尽时抛出异常之前应该阻塞的最长时间量(以毫秒为单位)。使用负值可以无限期地阻止。
spring.redis.pool.max-wait=-1
# 目标为保持在池中的最小空闲连接数。这个设置只有在正面的情况下才有效果。
spring.redis.pool.min-idle=0
# 以毫秒为单位的连接超时。
spring.redis.timeout=0| 以上是单机版本的,如果是集群参照多节点模式,增加两项即可: |
-
多节点配置:
# (普通集群,不使用则不用开启)在群集中执行命令时要遵循的最大重定向数目。
spring.redis.cluster.max-redirects=
# (普通集群,不使用则不用开启)以逗号分隔的“主机:端口”对列表进行引导。
spring.redis.cluster.nodes=127.0.0.1:1001,127.0.0.1:1002| 一旦开启了集群模式,那么基于单机的配置就会覆盖。 |
-
哨兵模式
# (哨兵模式,不使用则不用开启)Redis服务器的名称。
# spring.redis.sentinel.master=
# (哨兵模式,不使用则不用开启)主机:端口对的逗号分隔列表。
# spring.redis.sentinel.nodes=| PS,如果想了解更多使用方式,可以访问 Spring Boot官方文档,搜索spring.redis |
44.2.3. Redis Serializer
44.2.3.1. Redis Serializer概述
redis是以key-value的形式将数据存在内存中,key就是简单的string,key似乎没有长度限制,但原则上应该尽可能的短小且可读性强,只要Redis中的数据没有过期 key都会在内存中,因此减小key的尺寸可以有效的节约内存,同时也能优化key检索的效率。而value在redis中,存储层面仍然基于string,在逻辑层面,可以是string/set/list/map等。
当数据存储到Redis的时候,键(key)和值(value)都是通过Spring提供的Serializer序列化到数据库的。RedisTemplate默认使用的是JdkSerializationRedisSerializer, StringRedisTemplate默认使用的是StringRedisSerializer。
SDR支持的序列化策略,如下所示:

-
JdkSerializationRedisSerializer:
-
StringRedisSerializer:
-
JacksonJsonRedisSerializer:
-
OxmSerializer:
RedisTemplate默认使用的序列化机制是JdkSerializationRedisSerializer,可以访问org.springframework.data.redis.core.RedisTemplate#afterPropertiesSet查看。
| 如果需要了解更多关于序列化的内容, 可以扩展阅读 Redis序列化方式对比 |
44.2.3.2. Halo Redis Serializer
Halo框架中可以修改RedisTemplate序列化为StringRedisSerializer,但是默认不开启.如果有需要可以通过下面方式开启:
halo:
redis:
stringSerializer:
enabled: true45. Halo Redisson
45.1. Halo Redisson的功能
Halo Redisson基于spring-data-redis,并集成了Redisson,简单封装成spring boot starter。
在方便使用RedisTemplate/StringRedisTemplate的同时,可以直接使用由RedissonClient提供的强大分布式对象、分布式服务等功能。
45.2. Redisson介绍
Redisson是Redis官网推荐的一款Java Redis客户端,相关文档请参考 Redisson Wiki。
鉴于Redisson提供的强大功能,Halo Redisson 通过Redisson,可以方便的使用队列、分布式锁、限流器等基于Redis的分布式组件。
45.3. Halo Redisson的使用
45.3.1. Maven引入
1、 引入halo-redisson依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2、 在需要使用的工程模块中,引入 halo-redisson 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-redisson</artifactId>
</dependency>45.3.2. 配置
Halo Redisson的配置方式与 Spring官方的配置方式保持一致,目前支持 单节点模式、哨兵模式和集群模式。
在Spring Redis配置的基础上,提供了Redisson的扩展配置。这些扩展属性在halo.redis.redisson命名空间下。
-
单节点模式配置示例
spring:
redis:
host: 10.168.29.11
database: 5
port: 6379
password: ***
timeout: 5000
halo:
redis:
redisson:
single-server-config: #单节点模式相关配置
connection-minimum-idle-size: 10
connection-pool-size: 6445.4. Halo Redisson工具类
45.4.1. 防重复提交验证器
Web层应用在和浏览器交互时,由于网络抖动、用户重复点击提交等原因,应用会在短时间内收到多条重复请求, 如果接口没有做幂等处理,或者接口比较耗时,会造成业务重复处理、服务性能下降等相关问题。
鉴于该需求比较普遍,Halo Redis提供了开箱即用的防重复提交验证器组件(本质上是一种特殊的限流器)。
-
配置:
halo:
redis:
submitvalidator:
enabled: true #默认开启
-
使用
@Autowired
private SubmitValidator submitValidator;
//验证
boolean resubmit = submitValidator.isResubmit("业务key", "业务唯一ID", 20);
if(resubmit){
return ResultData.fail("400", "提交太频繁");
}
//todo 正常业务逻辑
-
接口说明
/**
* Desc: 防重复提交校验器
*
* @author xujin
* @date 2019/9/28 19:48
**/
public interface SubmitValidator {
/**
* 是否在指定时间内重复提交
*
* @param bizKey 业务key
* @param uid 同类业务中的唯一id标识符
* @return 在过期时间内该请求是否重复提交
* @see SubmitValidatorProperties#getExpireTime()
* @see SubmitValidatorProperties#DEFAULT_EXPIRE_TIME
*/
boolean isResubmit(String bizKey, String uid);
/**
* 是否在指定时间内重复提交
*
* @param bizKey 业务key
* @param uid 同类业务中的唯一id标识符
* @param expireTime 过期时间 单位:秒
* @return 在过期时间内该请求是否重复提交
* @see SubmitValidatorProperties#getExpireTime()
* @see SubmitValidatorProperties#DEFAULT_EXPIRE_TIME
*/
boolean isResubmit(String bizKey, String uid, Integer expireTime);
}
46. Halo Apollo
46.1. 什么是Halo Apollo
Halo Apollo是对携程配置中心增量的封装处理,把Apollo的app.id,env等环境参数与Spring Boot参数统一.
46.2. Halo Apollo的功能
Halo Apollo的功能如下所示:
-
为项目开发提供配置管理服务
-
使用标准的spring.profiles.active来区分环境,自动为ConfigCenter客户端设置env和meta地址
-
开发人员主要引入包就可以从配置中心读取配置(默认访问开发环境),不用关心Apollo的环境设置问题.
-
统一Apollo中的AppId,当没有设置AppId时,默认取Spring Application Name作为Appid,设置了AppId则使用Appid.
-
内置基础架构或者中间件团队的namespace
-
Apollo Namespace 有三种类型,私有类型,公共类型,关联类型(继承类型).关联类型又可称为继承类型, 关联类型具有 private 权限。关联类型的 Namespace 继承于公共类型的 Namespace,用于覆盖公共 Namespace 的某些配置。 使用建议如下:
-
基础框架部分的统一配置,如 DAL 的常用配置
-
基础架构的公共组件的配置,如监控,熔断等公共组件配置
-
| spring.profiles.active有DEV、FAT、UAT、PRO四个选项,通过-D传入,如果不传入,默认为DEV |
46.3. 使用Halo Apollo
46.3.1. Maven引入
-
引入Halo Apollo依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 Apollo 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-apollo</artifactId>
</dependency>46.4. Halo Apollo的最佳实践
支持 Apollo 配置自动刷新类型,支持 @Value @RefreshScope @ConfigurationProperties 以及日志级别的动态刷新.
-
@Value: Apollo 本身就支持了动态刷新.
@Value("${simple.xxx}")
private String simpleXxx;| 上述代码刷新没有问题 |
@Value("#{'${simple.xxx}'.split(',')}")
private List<String> simpleXxxs;| 需要注意的是如果@Value 使用了 SpEL 表达式,动态刷新会失效。 |
46.5. 使用Apollo的开发案例
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.stereotype.Component;
@Component
@RefreshScope
public class InfraApolloSwitchConfig {
/**
* 质检和鉴别瑕疵数据是否使用mock
*/
public static Boolean QUALITY_REPORT_USE_MOCK = false;
/**
* 支付成功后,多少分钟后卖家才能开始发货(同买家的无责取消期),单位为分钟
*/
public static Integer SWITCH_SELLER_START_DELIVER_TIME_LIMIT = 30;
@Value("${switch.quality.report.use.mock}")
public void setQualityReportUseMock(Boolean qualityReportUseMock) {
QUALITY_REPORT_USE_MOCK = qualityReportUseMock;
}
@Value("${switch.seller.startDeliver.timeLimit}")
public void setSwitchSellerStartDeliverTimeLimit(Integer sellerStartDeliverTimeLimit) {
SWITCH_SELLER_START_DELIVER_TIME_LIMIT = sellerStartDeliverTimeLimit;
}
}使用静态变量的方式:InfraApolloSwitchConfig.SWITCH_SELLER_START_DELIVER_TIME_LIMIT
47. Halo Shiro
47.1. 什么是Halo Shiro
Spring boot中使用shiro大都是通过shiro-spring.jar进行的整合的,虽然不是太复杂,但是也无法做到spring-boot-starter风格的开箱即用。项目中经常用到的功能比如:验证码、密码错误次数限制、账号唯一用户登陆、动态URL过滤规则、无状态鉴权等等,shiro还没有直接提供支持。
Halo Shiro对这些常用的功能进行了封装和自动导入实现开箱即用。
47.2. Halo Shiro的功能
Halo Shiro的功能如下所示:
-
spring-boot-starter风格的开箱即用。
-
区分ajax请求和普通请求,普通请求通过跳转来响应未登陆和未授权,AJAX请求通过状态码和消息响应未登陆和未授权。
-
集成jcaptcha验证码。
-
密码输入错误,重试次数限制。
-
账号唯一用户登陆,一个账号只允许一个用户登陆。
-
与SpringCache无缝对接,支持guava、ehcache、redis等。
-
提供认证\授权缓存数据同步接口,即时生效。
-
支持动态URL过滤规则。
-
无状态认证授权支持,共存有状态和无状态两种鉴权方式,无状态鉴权支持JWT(JSON WEB TOKEN)、HMAC(哈希消息认证码)两种协议。
-
在线session管理,强制用户下线功能。
47.3. 使用Halo Shiro
47.3.1. Maven引入
-
引入Halo Shiro依赖。有两种方式,如下所示:
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二种是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入Halo Shiro模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-shiro</artifactId>
</dependency>47.4. 功能使用
47.4.1. 对接LDAP
halo:
shiro:
ldapRealmEnabled: true
apiUrl: /api/**
loginUrl: /admin/login
unauthorizedUrl: /403
ldapUrl: ldap://ldap.xxx.com
ldap-dn-template: uid={0},ou=staff,dc=xxoxs,dc=cc
jwt-filter-url: /admin/**47.4.2. 对接DB(通过用户名和密码)
1.开启Shiro对接DbRealm,如下面yml文件所示:
halo:
shiro:
apiUrl: /api/**
loginUrl: /admin/login
unauthorizedUrl: /403
jwt-filter-url: /admin/**
d-b-realm-enabled: true2.实现ShiroAccountProvider接口对接当前系统,查询用户,权限,角色,示例代码如下所示:
@Service
public class AccountProviderImpl implements ShiroAccountProvider {
@Autowired
private RoleMapper roleMapper;
@Autowired
private UserRolesMapper userRolesMapper;
@Autowired
private PermissionMapper permissionMapper;
@Autowired
private RolePermissionMapper rolePermissionMapper;
@Autowired
private UserMapper userMapper;
@Override
public Account loadAccount(String account) throws AuthenticationException {
UserDO userDO=userMapper.findUserByUserName(account);
if(null == userDO){
throw new AuthenticationException("账号或密码错误");
}
return userDO;
}
@Override
public Set<String> loadRoles(String account) {
List<String> userRoles = userRolesMapper.findUserRoles(account);
if (CollectionUtils.isEmpty(userRoles)) {
userRoles = Lists.newArrayList(UserRoleEnum.USER.getRole());
}
Set<String> validRoles = roleMapper.findValidRoles(userRoles)
.stream()
.map(RoleDO::getKey)
.collect(Collectors.toSet());
if (inBlackList(validRoles)) {
return null;
}
return new HashSet(validRoles);
}
protected boolean inBlackList(Set<String> roles) {
return roles.contains(UserRoleEnum.BLACK.getRole());
}
@Override
public Set<String> loadPermissions(String account) {
return null;
}
@Override
public Set<String> loadPermissions(Set<String> validRoles) {
Set<Long> permissionIds = rolePermissionMapper.findPermissionByRoles(validRoles)
.stream().map(RolePermissionDO::getPermissionId).collect(Collectors.toSet());
Set<String> permissions = permissionMapper.findValidPermissions(permissionIds)
.stream().map(PermissionDO::getPermission).collect(Collectors.toSet());
return permissions;
}
}3.登录Controller代码如下所示:
@RestController
@RequestMapping("/admin")
@Api("用户登录")
public class LoginController {
@Autowired
private CommandBus commandBus;
@PostMapping("/login")
public ResultData<LogInCO> login(@RequestBody LoginUserCmd loginUserCmd) {
return commandBus.send(loginUserCmd);
}
}4.登录命令执行代码如下所示:
@CmdHandler
@Slf4j
public class LoginUserCmdExe implements CommandExecutorI<ResultData<LogInCO>, LoginUserCmd> {
@Autowired
private EventBus eventBus;
@Override
public ResultData<LogInCO> execute(LoginUserCmd loginUserCmd) {
ResultData<LogInCO> resultData = new ResultData<>();
if (null==loginUserCmd) {
resultData.setMsgCode("401");
resultData.setMsgContent("login failed");
return resultData;
}
String username=loginUserCmd.getUsername();
String password=loginUserCmd.getPassword();
if (StringUtils.isBlank(username) || StringUtils.isBlank(password)) {
resultData.setMsgCode("401");
resultData.setMsgContent("login failed");
return resultData;
}
username = username.trim();
try {
UsernamePasswordToken token = new UsernamePasswordToken(username, password);
Subject subject = SecurityUtils.getSubject();
subject.login(token);
LogInCO logInCO = new LogInCO().setUsername(username).setToken(JwtUtil.createToken(username));
resultData.setData(logInCO);
try {
createUserByEvent(username,password);
} catch (Exception e) {
log.info("create user by event fail:{}",e);
}
} catch (Exception ex) {
resultData.setMsgCode("401");
resultData.setMsgContent("login failed");
return resultData;
}
return resultData;
}
private void createUserByEvent(String username,String password) {
CreateUserEvent createUserEvent=new CreateUserEvent();
createUserEvent.setUserName(username);
createUserEvent.setPassword(password);
createUserEvent.setRole("USER");
eventBus.asyncPublishEvent(createUserEvent);
}
}47.4.3. 关闭Halo Shiro
当引入Halo Shiro的Starter之后,可以通过yml文件相关配置关闭Halo Shiro的功能,如下所示:
halo:
shiro:
apiUrl: /api/**
loginUrl: /admin/login
unauthorizedUrl: /403
jwt-filter-url: /admin/**
d-b-realm-enabled: false (1)
jwt-filter-url: /admin/**
jwt-filter-enabled: false (2)
shiroAnnoEnabled: false (3)| 1 | 关闭dbRealm |
| 2 | 关闭JwtFilter |
| 3 | 关闭shiro中的注解 |
48. Halo influxDB
48.1. Halo influxDB的功能
halo influxDB主要对influxDB-java进行封装,功能如下所示:
-
支持是否开启okhttpClient作为底层的查询客户端
-
当开启okHttpClient时,支持自定义配置连接参数
-
提供InfluxDBTemplate并封装常用的操作
48.2. halo influxdb的使用
48.2.1. Maven引入
-
引入halo-influxdb依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 halo influxdb 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-influxdb</artifactId>
</dependency>48.3. halo influxdb的使用
48.3.1. 配置influxdb的连接信息
通过yml文件方式配置连接influxdb的配置信息如下所示:
halo:
influxdb:
enable: true
enableOkHttpClient: true
url: http://localhost:8086
username: admin
database: janus
retention-policy: autogen
okhttp:
connectTimeout: 1048.3.2. 示例Java使用代码
依赖InfluxDBTemplate操作InfluxDB的示例代码,如下所示:
@Component
public class InfluxDBService {
@Autowired
private InfluxDBTemplate<Point> influxDBTemplate;
public void queryJVM(){
influxDBTemplate.createDatabase();
final Point p = Point.measurement("disk")
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.tag("tenant", "default")
.addField("used", 80L)
.addField("free", 1L)
.build();
influxDBTemplate.write(p);
}
}49. Halo Mail
49.1. Halo Mail的功能
Halo Mail通过对spring-boot-starter-mail进行二次封装和扩展实现开箱即用,并提供统一的sdk,屏蔽底层的实现细节。
49.2. Halo Mail的使用
49.2.1. Maven引入
1.引入Halo Mail依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.在需要使用的工程模块中,引入halo-starter-test模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-mail</artifactId>
<scope>test</scope>
</dependency>49.2.2. Halo Mail使用
1.配置yml文件如下:
@Autowired
private HaloMailService haloMailService;2.依赖注入HaloMailService,调用对应的方法即可
@Autowired
private HaloMailService haloMailService;50. Halo Retrofit
Retrofit是适用于Android和Java且类型安全的HTTP客户端,其最大的特性的是支持通过接口的方式发起HTTP请求。而spring-boot是使用最广泛的Java开发框架,但是Retrofit官方没有支持与spring-boot框架快速整合,因此我们开发了halo-starter-retrofit。
50.1. Halo Retrofit的功能
Halo Retrofit实现了Retrofit与spring-boot框架快速整合,并且支持了诸多功能增强,极大简化开发。具体的功能如下:
-
自定义注入OkHttpClient
-
注解式拦截器
-
连接池管理
-
日志打印
-
请求重试
-
错误解码器
-
全局拦截器
-
熔断降级
-
微服务之间的HTTP调用
-
调用适配器
-
数据转换器
50.2. Halo Retrofit的使用
50.2.1. Maven引入
1.引入Halo Retrofit依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.在需要使用的工程模块中,引入halo-starter-test模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-boot-starter-retrofit</artifactId>
<scope>test</scope>
</dependency>50.2.2. Halo Retrofit使用
1.定义http接口: 接口必须使用@RetrofitClient注解标记!http相关注解可参考官方文档https://square.github.io/retrofit/
@RetrofitClient(baseUrl = "${test.baseUrl}")
public interface HttpApi {
@GET("person")
Result<Person> getPerson(@Query("id") Long id);
}| 注意:方法请求路径慎用/开头。对于Retrofit而言,如果baseUrl=http://localhost:8080/api/test/,方法请求路径如果是person,则该方法完整的请求路径是:http://localhost:8080/api/test/person。 而方法请求路径如果是/person,则该方法完整的请求路径是:http://localhost:8080/person。 |
2.依赖注入,调用对应的方法即可
@Service
public class TestService {
@Autowired
private HttpApi httpApi;
public void test() {
// 通过httpApi发起http请求
}
}默认情况下,自动使用SpringBoot扫描路径进行retrofitClient注册。你也可以在配置类加上@RetrofitScan手工指定扫描路径。
50.2.3. Retrofit HTTP请求相关注解
HTTP请求相关注解,全部使用了retrofit原生注解。详细信息可参考官方文档:retrofit官方文档,以下是一个简单说明:
| 注解分类 | 支持的注解 |
|---|---|
请求方式 |
@GET @HEAD @POST @PUT @DELETE @OPTIONS @HTTP |
请求头 |
@Header @HeaderMap @Headers |
Query参数 |
@Query @QueryMap @QueryName |
Path参数 |
@Path |
form-encoded参数 |
@Field @FieldMap @FormUrlEncoded |
请求体 |
@Body |
文件上传 |
@Multipart @Part @PartMap |
url参数 |
@Url |
VII Halo Cloud
51. Halo Cloud组件列表
| 名称 | 描述 | 备注 |
|---|---|---|
halo-cloud-starter-nacos |
对Spring Cloud Alibaba中的Nacos进行扩展封装 |
更多访问Halo Cloud Nacos |
halo-cloud-starter-eureka |
对Eureka,Ribbon进行定制扩展 |
更多访问Halo Eureka |
halo-cloud-starter-openfeign |
对Open Feign进行定制扩展 |
更多访问Halo Feign |
52. Halo Eureka
52.1. 什么是Halo Eureka
-
Eureka starter是一个针对eureka服务注册发现的增强插件
功能
-
增加服务注册及发现的维度选择,而不仅仅依赖于服务ID来进行注册与发现;(这个功能是为了适应集团子公司及BU部门比较多的情况,有可能出现应用名重复的情况)
-
可以屏蔽某一些IP,不让流量进入这些IP,达到类似金丝雀部署的效果;
-
对ribbon的默认负载均衡机制进行增强,动态根据服务节点负载情况来路由。为每个节点打分(包括cpu和内存;cpu权重为0.7,内存权重为0.3),分值越高,被选中的概率越大。
-
消费者可以指定服务提供者的的group和version
52.2. 使用Halo Eureka
52.2.1. Maven引入
-
引入Halo-Feign依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 eureka 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-cloud-starter-eureka</artifactId>
</dependency>52.3. 演示代码
-
服务提供端
bootstrap.yml配置:
spring:
application:
name: defensor-openfeign-provider
group: qingcloud #group建议以部门作为一个分组
version: 1.0.1 #version建议1.0.1,可以随意定制添加Group和Version进行服务注册,这两个字段将会注册在Eureka的Meta-Data,其中Group建议为部门名,Version可以1.0.1-DEV等等
-
服务消费端,如果希望消费指定的group和version,则启用如下配置。否则不需要做下面的配置
application.yml配置:
eureka:
client:
serviceUrl:
defaultZone: http://eureka.springcloud.cn/eureka/
reference: META-INF/refercen.json在META-INF目录下新建refercen.json,对于服务user-service只消费group:qingcloud且version:1.0.1的服务,内容如下:
[
{
"serviceId": "user-service",
"group": "qingcloud",
"version": "1.0.1"
}
]52.4. 详细功能示例代码和测试用例
52.4.1. 默认配置
框架添加了如下默认配置,之所以添加这些,是因为在线上出现过未配置它们导致的问题
eureka.instance.prefer-ip-address:true
ribbon.MaxAutoRetries: 0
ribbon.MaxAutoRetriesNextServer: 052.4.2. 屏蔽一些IP
-
开启actuator并开启管理端口
-
访问http://ip:managerPort/eurekamgmt/dynamicsroute?serviceId=&routeIp=,其中routeIp是需要屏蔽的IP列表,以","分割

示例访问URL:http://localhost:8081/actuator/eurekamgmt/dynamicsroute?serviceId=defensor-openfeign-provider&routeIp=192.168.47.171
屏蔽成功之后,访问已屏蔽的实例IP,出现如下的错误:
{
"timestamp": "2019-06-13T07:37:28.419+0000",
"status": 500,
"error": "Internal Server Error",
"message": "com.netflix.client.ClientException: Load balancer does not have available server for client: defensor-openfeign-provider",
"path": "/user/add"
}| 建议在开发和测试环境使用,屏蔽影响测试的实例 |
52.4.3. 清除路由
-
开启actuator并开启管理端口
-
访问http://ip:managerPort/eurekamgmt/clearRoute?serviceId=**, 清除步骤2的规则
示例URL:http://localhost:8081/actuator/eurekamgmt/clearRoute?serviceId=defensor-openfeign-provider
| 建议在开发和测试环境使用,直接清除某个服务的所有实例 |
52.4.4. 负载均衡机制
原理是:CPU和内存等可用资源越多,得分越高,节点被选中的概率也就越大
大多数情况,我们只考虑CPU就可以,因为得益于强大的GC,同一个JAVA应用的多个节点的内存使用率基本差不多,除非发生了内存泄漏。故在判断节点资源时,最好给CPU和内存不同的权重。
下面举个栗子来描述如何选择节点,这个例子中不考虑内存
cpuScore =(max( coreSize - load), 0)/coreSize
memScore = (max(maxHeap - usedHeap), 0)/maxheap
-
以cpu为例(内存同理)
Node1:8核心,load等于2时得分(8 -2 )/8 = 0.75
Node2:8核心,load等于6时得分(8 -6) /8 = 0.25
Node3:8核心,load等于4时得分(8 -4) /8 = 0.5
Node4:8核心,load等于10时得分(8 -10) /8 = 0totalScore= 0.75+0.25+0.5+0 = 1.5
-
按CPU的分值将节点分散在[0-1]之间
R1 = 0.75/1.5=0.5
R2 = 0.25/1.5 = 0.1667 。0.1667+ 0.5 = 0.6667
R3 = 0.5/1.5= 0.3333 。0.3333+0.6667 = 1.0
R4 = 1+0 = 1结果是:
[0,0.5) 选Node1
[0.5,0.6667) 选Node2
[0.6667,1) 选Node3
[1,1)选Node4取一个0-1之间的随机值,这个值分布到哪个区间,就选择对应那个区间的Node。
rollScore = Random(0,1)
52.4.5. 指定本地IP测试
在开发项目的过程中,通过注册中心走服务注册和发现,本地开发调试的时候会出现,服务会调用到其它服务,而不是自己本地的服务。 服务之间联调,非常不方便。在dubbo里面,提供指定IP调用服务的方式。 在spring cloud里面,当然也有类似的解决方式,如下:
## 禁用注册中心
ribbon.eureka.enabled: false
service-name1.ribbon.listOfServers: http://127.0.0.1:7710
service-name2.ribbon.listOfServers: http://127.0.0.1:7720| 原理是禁用注册中心(这里使用了eureka),为每个服务指定请求路径即可! |
53. Halo Feign
53.1. Halo Feign的功能
halo feign主要对Spring Cloud Open Feign进行扩展和增强,主要扩展了两点:
-
Open Feign不支持Spring MVC的所有注解
-
解决Open Feign不支持解决Get请求多参数传递的问题
-
支持提供两个版本的Open Feign封装,分别支持Spring Cloud E版和Spring Cloud F版
-
支持OkHttpClient
53.3. 使用Feign开发二方包
-
由于Spring Cloud从F版开始Open Feign部分类移动到新的包名下,并且底层的Spring Boot的版本从1.x变为2.x存在不兼容。
-
由于历史原因,公司老业务系统基于Spring Cloud Edgware.SR5开发,目前新系统基于Spring Cloud Finchley.SR3版本开发,新旧系统之间的相互调用存在问题。
因此,需要编写两个版本的二方包。因此Halo Framework提供两个版本的Open Feign封装。
|
由服务消费方编写服务提供者的该提供的二方包,这种方式也可以解决不同Spring Cloud版本服务之间的调用问题,但是不建议这么做。 |
53.3.1. Halo封装的Feign
1.Halo封装两个版本的Open feign,说明如下所示:
| Open Feign starter | version | Spring Cloud | Spring Boot |
|---|---|---|---|
halo-cloud-starter-openfeign |
1.0.1.RELEASE |
Finchley.SR3 |
2.0.8.RELEASE |
2.二方包工程目录结构示例
-
在开发两个版本的二方包时,推荐示例Maven模块如下所示:
| 模块 | 说明 |
|---|---|
halo-goods-client |
二方包父模块 |
用于聚合1.x和2.x的二方包 |
halo-goods-client-1.x |
针对Spring Cloud E版本的二方包 |
halo-goods-client-2.x |
针对Spring Cloud F版本的二方包 |
halo-goods-client-core |
53.3.2. 支持Spring Cloud Finchley.SR3版本
-
引入Halo-Feign依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入 halo-starter-openfeign 模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-cloud-starter-openfeign</artifactId>
</dependency>53.3.3. 使用OkHttpClient
OpenFeign默认使用JDK的HttpURLConnection作为底层连接,效率较低。
OpenFeign官方提供两种连接池实现,分别为ApacheHttpClient、OkHttpClient。
halo-openfeign从1.3.0.RELEASE开始,已经引入OkHttpClient相关包,通过简单配置即可使用。
feign:
httpclient:
connection-timeout: 10000 # 连接超时时间
okhttp:
enabled: true # 启用OkHttpClient
readTimeout: 10000 # halo扩展配置:OkHttpClient read超时时间
write-timeout: 10000 # halo扩展配置:OkHttpClient write超时时间54. Halo Cloud Nacos
54.1. 什么是Halo Cloud Nacos
-
Halo Cloud Nacos是对Spring Cloud Alibaba Nacos的扩展封装
54.2. 使用Halo Cloud Nacos
54.2.1. Maven引入
-
引入Halo Cloud Nacos依赖。有两种方式
-
第一种是将halo-starter-parent作为工程的parent,maven依赖如下所示:
-
<parent>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>-
第二中是利用dependencyManagement引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-dependencies</artifactId>
<version>2.0.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>-
在需要使用的工程模块中,引入nacos模块即可
<dependency>
<groupId>org.xujin.halo</groupId>
<artifactId>halo-cloud-starter-nacos</artifactId>
</dependency>Halo Admin
55. 中台登录
业务中台支持域账号进行登录, 登录界面如下图所示:
56. 中台可视化DashBoard
业务中台DashBoard如下图所示,包括中台建设成熟模型等。
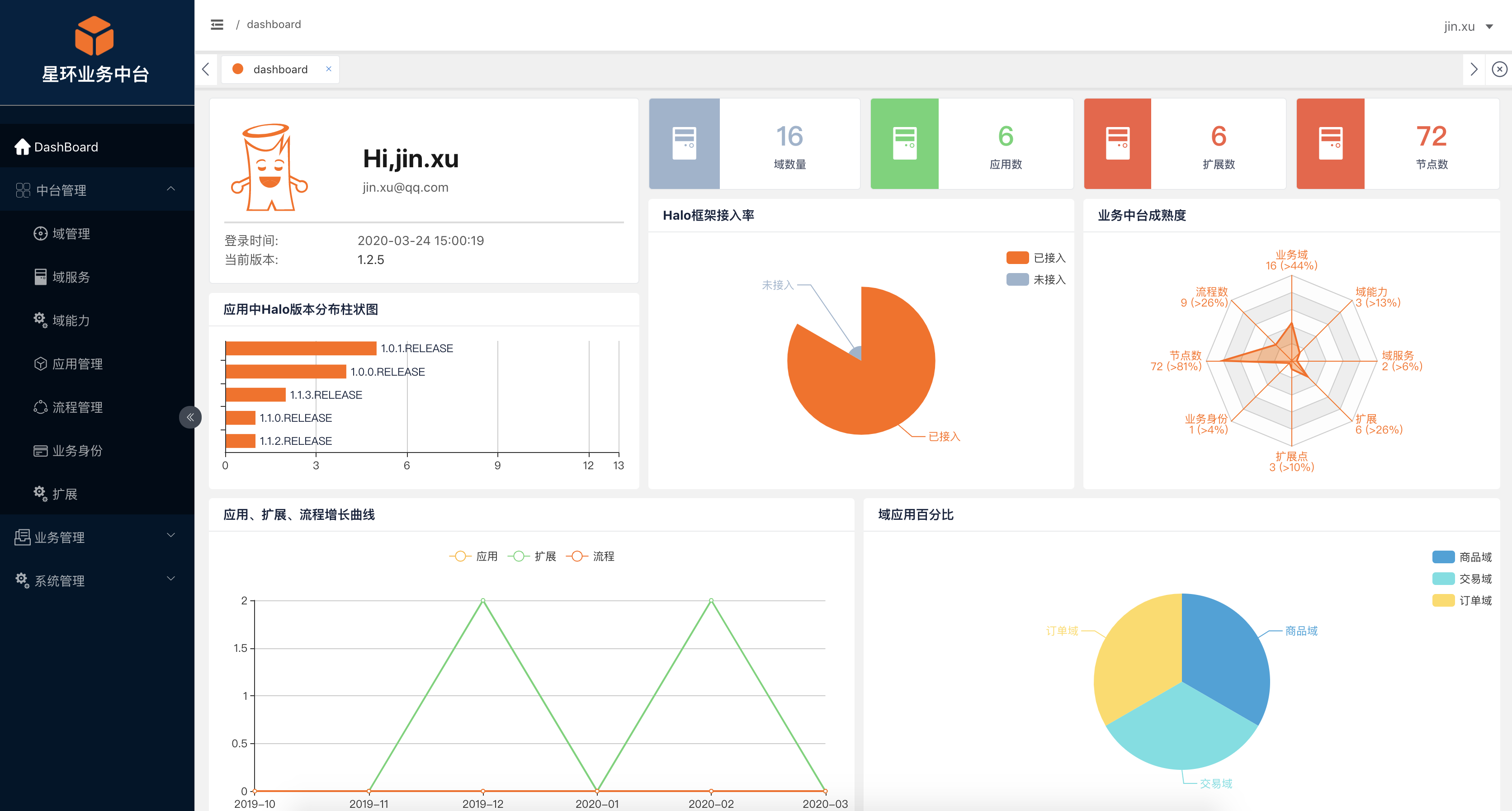
57. 域管理
1.业务中台-域管理编辑模式如下图所示:
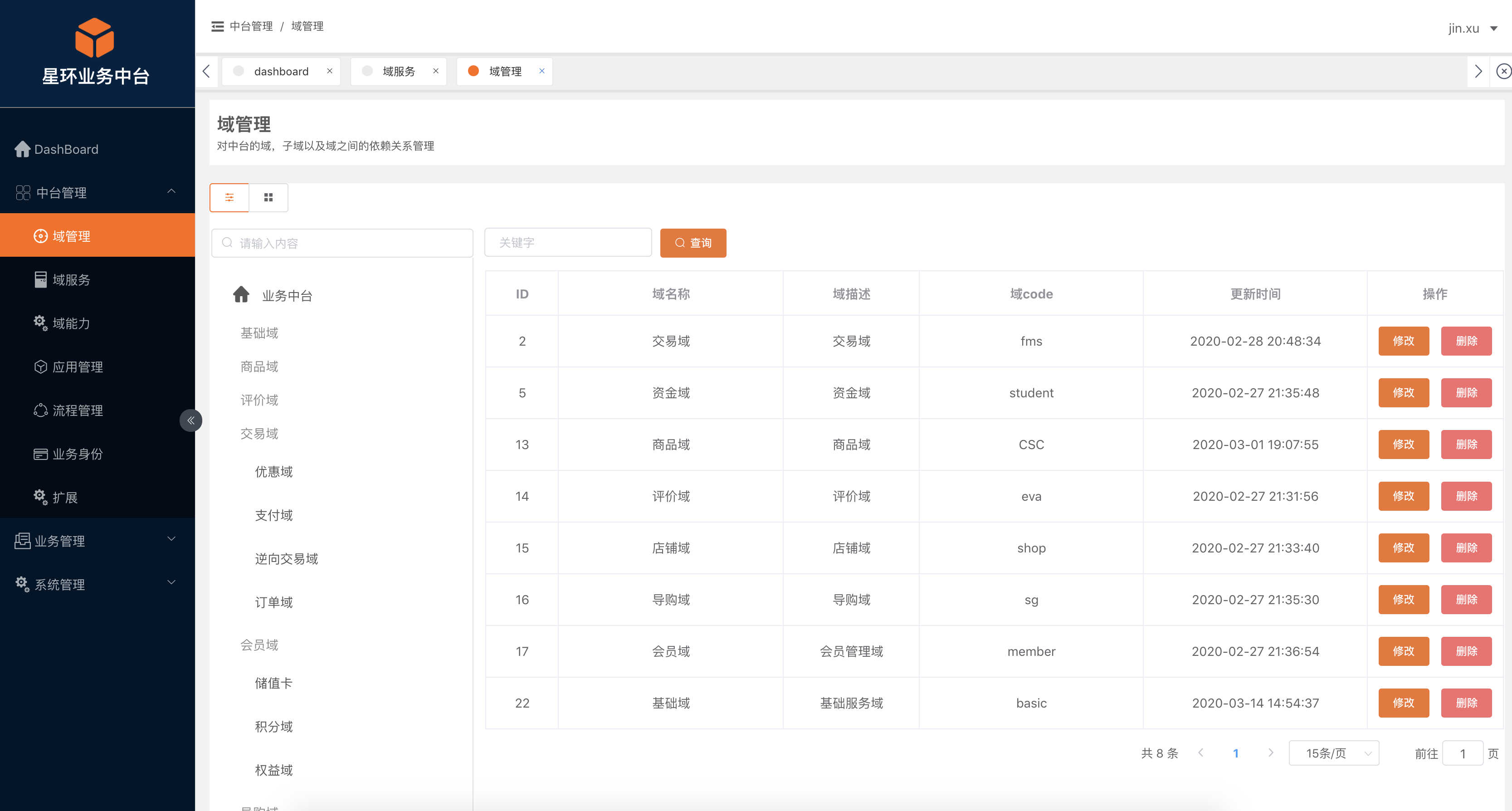
2.业务中台-域管理树形层级查看模式,如下图所示:
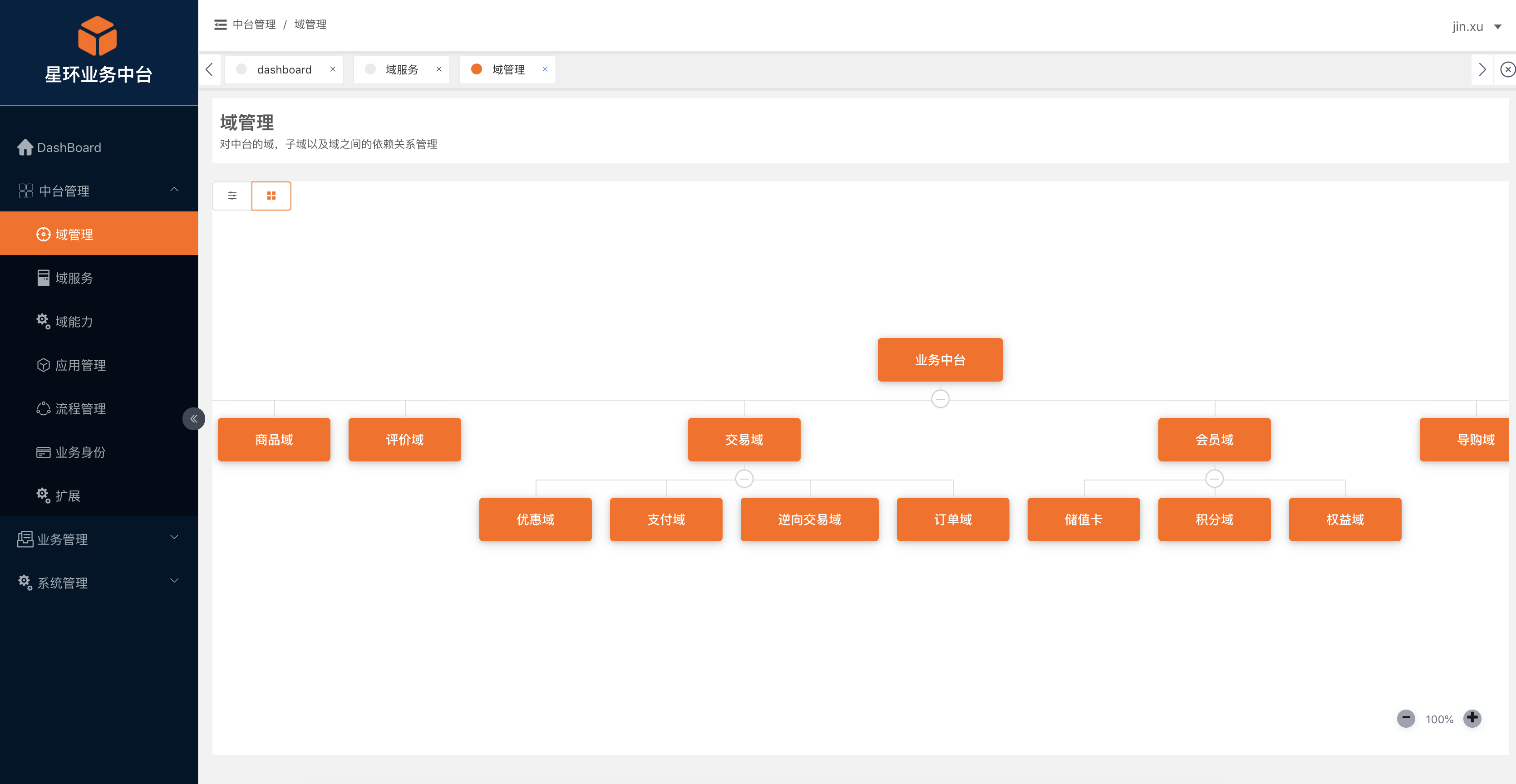
58. 中台成熟度模型
业务中台建设的成熟度,目前在业界没有具体的衡量标准。Halo框架提供一个衡量标准。如下图所示,用雷达图的方式进行衡量。 雷达图面积越大,说明业务中台建设越成熟。
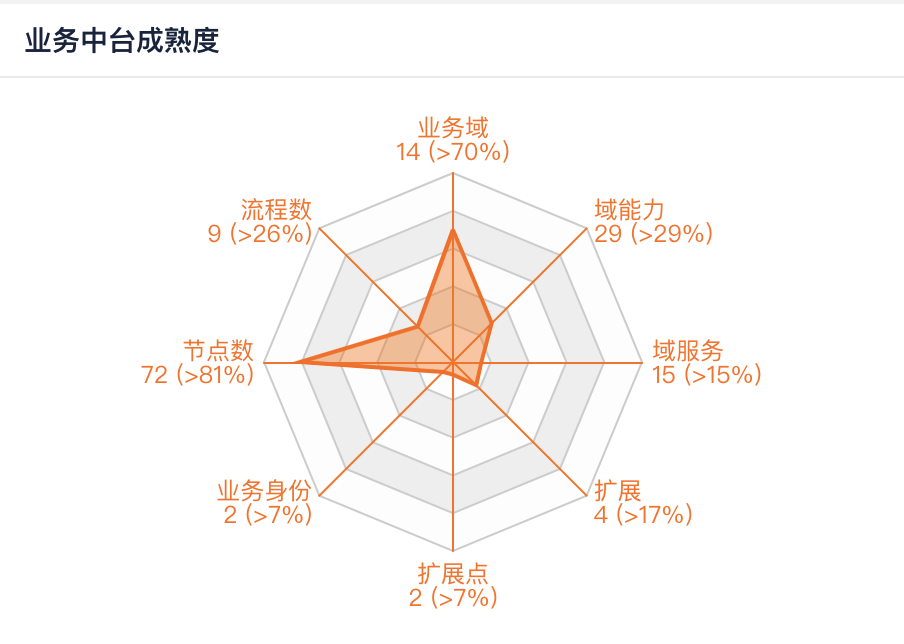
59. 域服务
业务中台按照域划分之后,每个域由应用组成,统一对外提供域服务。比如订单域,由订单应用等统一对外提供订单域的域服务。Halo Admin增加域服务的管理。如下所示:
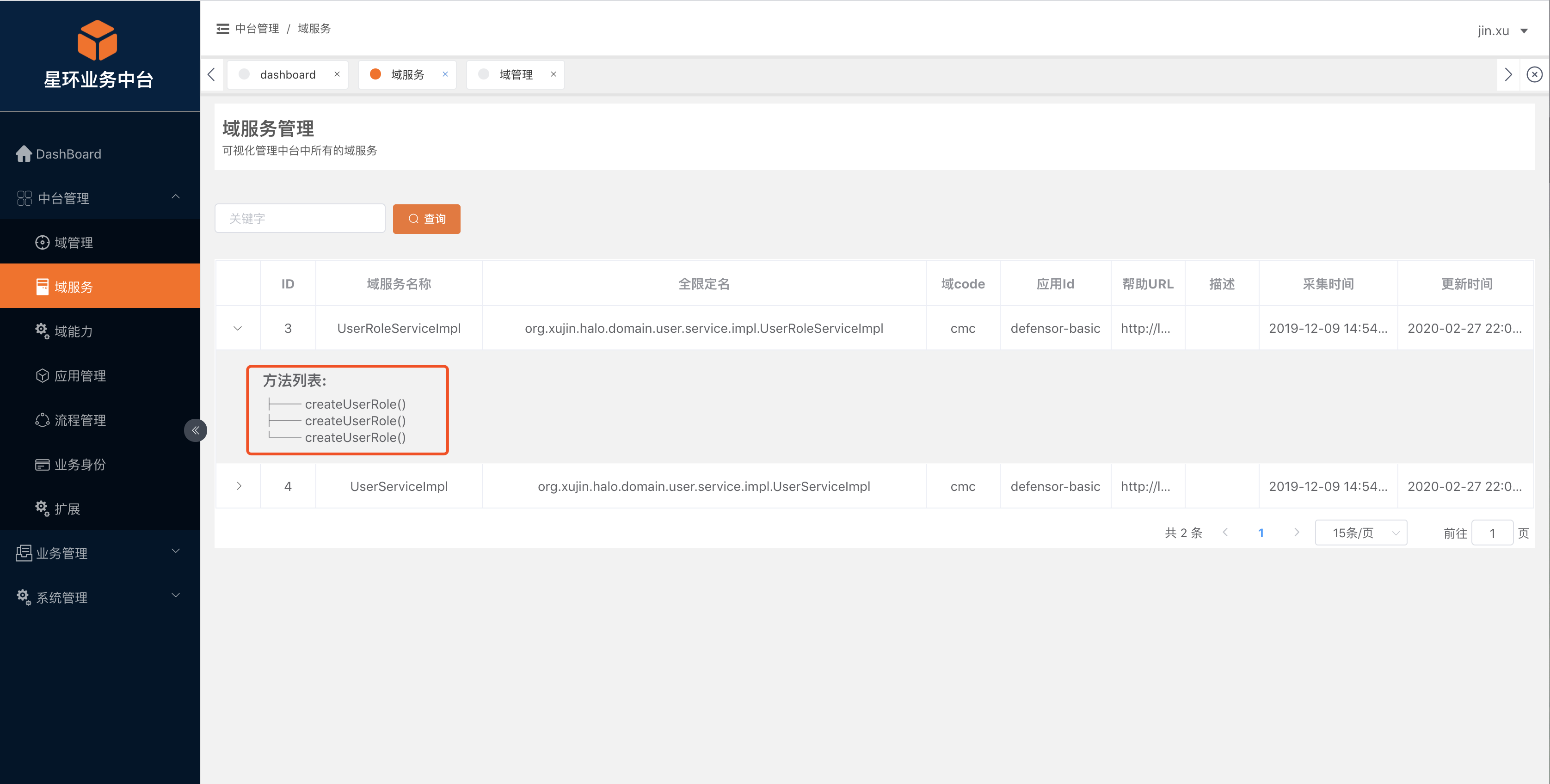
60. 域能力
业务中台有业务域,业务域中的应用提供的服务组成域服务对外提供域服务,域服务调用多个域能力,完成整个业务操作。Halo中的域能力即领域驱动中实体或值对象的行为和能力。 Halo Admin将每个业务域的域能力统一收集上传。
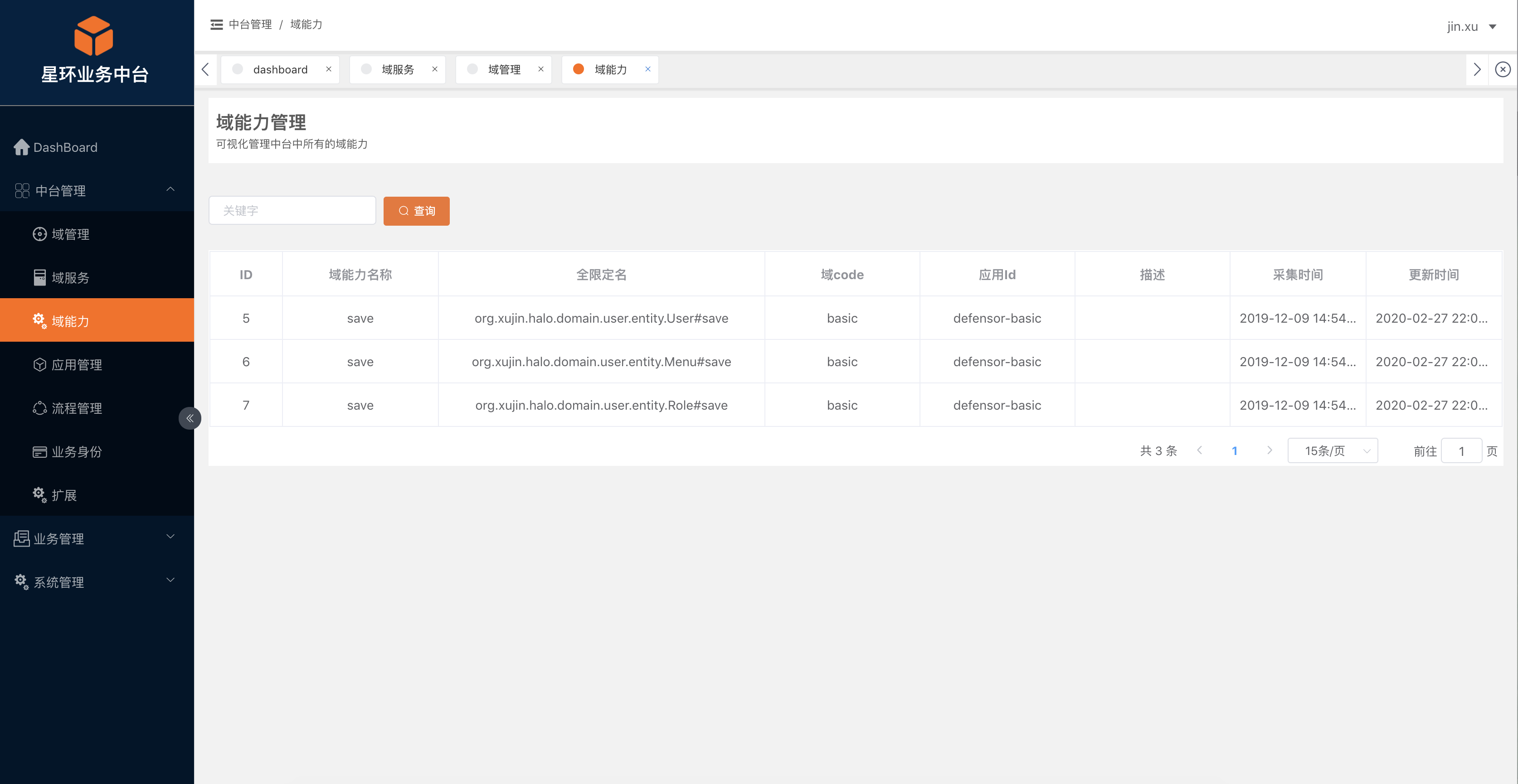
61. 应用管理
1.业务中台将对业务中台的应用进行管理,包括应用所属域,职能以及应用Owner进行管理,如下图示:
62. 流程编排管理
1.中台应用,业务流程代码编排图形化展示,对业务可复用资产一目了然。
63. 扩展管理
1.中台应用的扩展能力和插件能力,展示支撑的产品线,业务线,业务活动等能力,如下图所示:
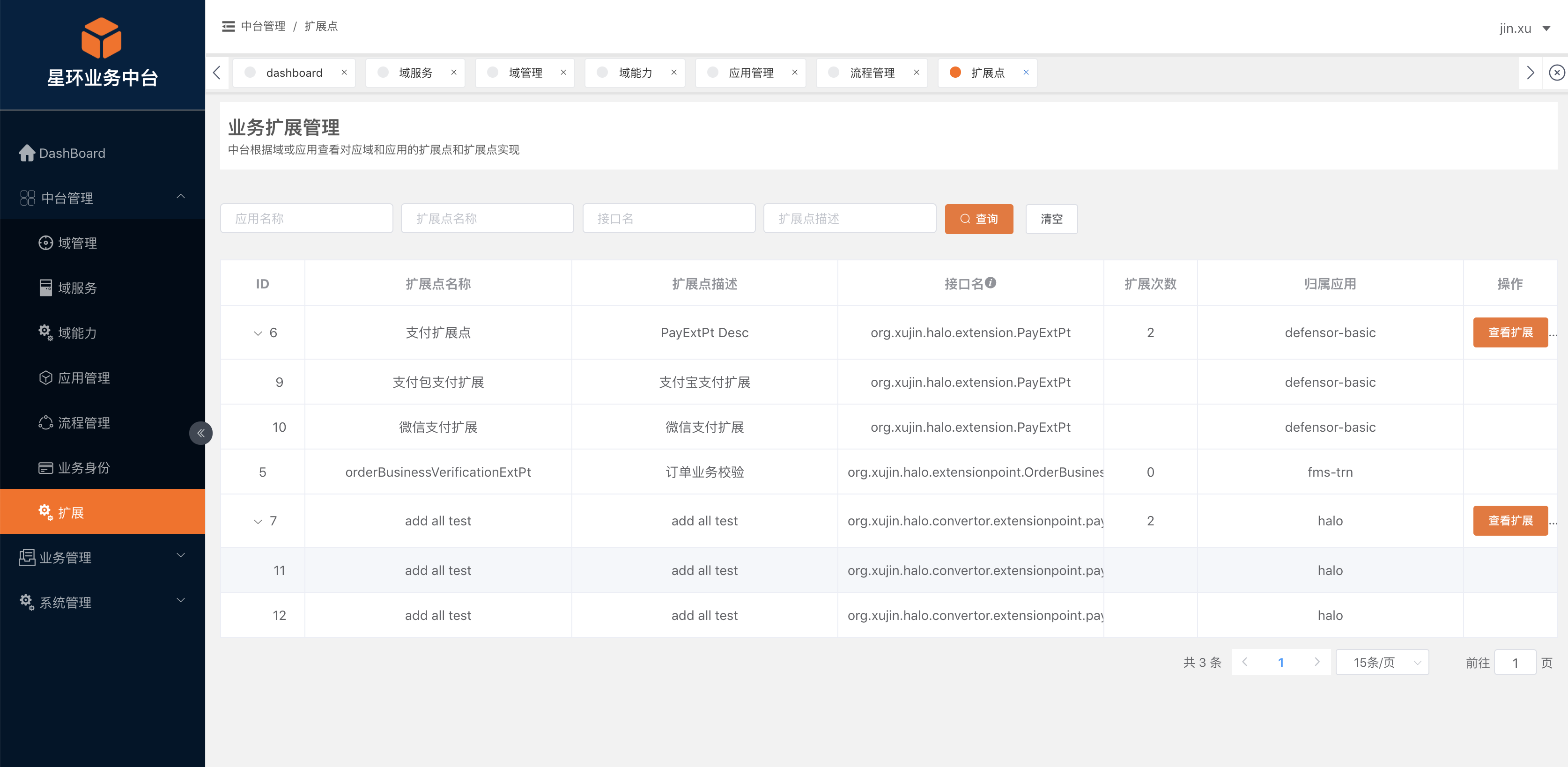
VIII Tools
65. 代码生成器
Codegen 是一款用来生成Halo framework代码风格和项目结构的代码生成器工具,可以利用它去生成指定类型的项目.
目前codegen只支持生成Maven项目,不支持生成Gradle项目。
codegen可以生成xxx-App,xxx-inst
目前halo codegen有网页版。
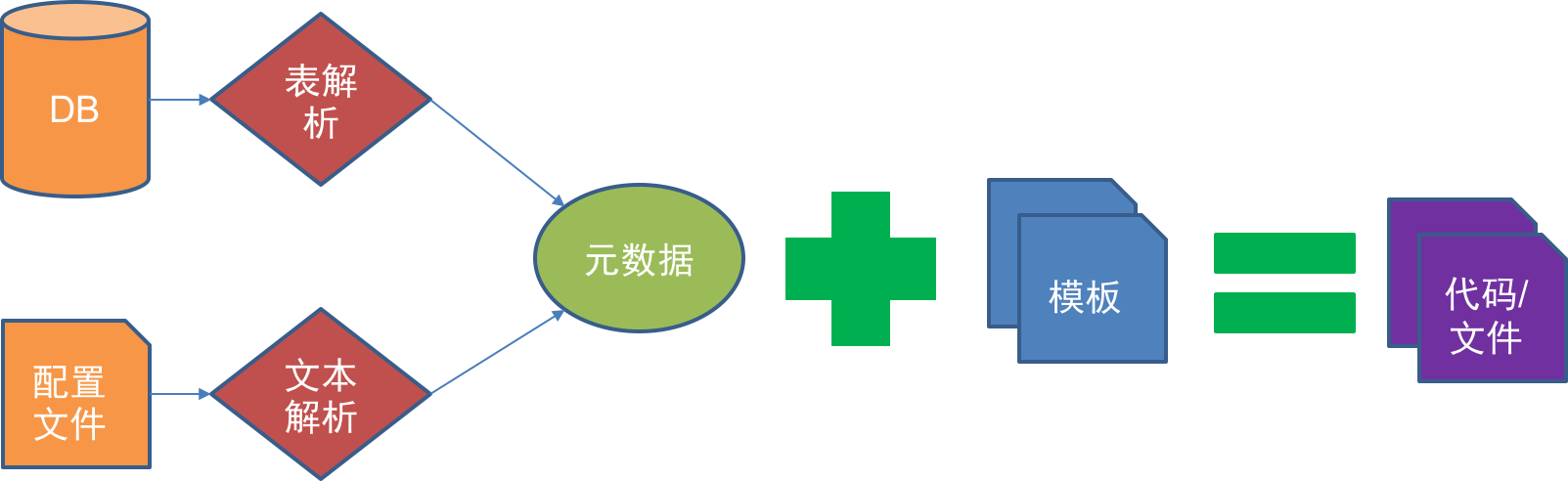
66. Halo Plugin
66.1. Halo Gradle Plugin
66.1.1. Halo Reference Plugin
halo-reference-plugin是Halo Team专为Halo框架文档的编写定制的Gradle插件.通过此插件可以生成目前你看到的文档.
| halo-reference-plugin是对https://github.com/spring-gradle-plugins/docbook-reference-plugin[docbook-reference-plugin增强和定制] |
dependencies {
//Provides additional optional and provided dependency configurations for Gradle along with Maven POM generation support
classpath("org.springframework.build.gradle:propdeps-plugin:0.0.7")
classpath("org.asciidoctor:asciidoctor-gradle-plugin:1.5.0")
classpath("org.xujin.gradleplugin:halo-reference-plugin:0.0.4-SNAPSHOT")
}67. 开发规范
开发规范主要有以下内容:
| 规范 | 说明 |
|---|---|
应用分层规范 |
统一应用的分层结构,达成统一认知,更多访问应用分层规范 |
数据库访问层规范 |
更多访问数据库访问层规范 |
返回值规范 |
统一给前端或手机App的返回值,更多访问返回值规范 |
二方包规范 |
统一服务提供者,提供的sdk规范,更多访问二方包规范 |
日志规范规范 |
统一应用内部打日志,更多访问日志规范 |
开发工具设置规范 |
统一IDEA开发工具的设置,更多访问IDEA常用设置 |
67.1. 应用分层规范
发布系统入口支持创建,应用分层,直接生成标准的应用工程结构,严格按照分层结构开发。
67.1.1. Halo简化版DDD分层
Halo DDD的简化版,是把App层,domain层,基础设施层合并到core模块,减少层次结构
├── ddd-demo-client //二方包
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── xujin
│ └── ddd
│ └── demo
│ └── client
│ ├── api //接口定义
│ ├── cmo //命令对象
│ └── co
│ └── UserCO.java //客户端对象
├── ddd-demo-core //应用的核心层,包含了ddd中的app层,domain层和基础设施层
│ ├── pom.xml
│ └── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── ddd
│ │ └── demo
│ │ ├── app
│ │ │ ├── command
│ │ │ │ ├── AddUserCmdExe.java // 写命令
│ │ │ │ ├── cmo
│ │ │ │ │ └── AddUserCmd.java //命令对象
│ │ │ │ ├── co
│ │ │ │ │ └── UserCO.java //客户端对象
│ │ │ │ └── query //查询命令
│ │ │ └── converter
│ │ │ └── UserClientConverter.java //转换防腐层
│ │ ├── domain
│ │ │ ├── aggregate01 //聚合1
│ │ │ │ ├── converter
│ │ │ │ │ └── UserConverter.java // app进domain的转换层
│ │ │ │ ├── entity
│ │ │ │ │ └── UserE.java //实体
│ │ │ │ ├── factory
│ │ │ │ │ └── UserFactory.java //工厂
│ │ │ │ ├── ports
│ │ │ │ │ └── UserPort.java //端口
│ │ │ │ ├── repository
│ │ │ │ │ └── UserRepository.java //资源库
│ │ │ │ └── service
│ │ │ │ ├── UserService.java //域服务接口
│ │ │ │ └── impl
│ │ │ │ └── UserServiceImpl.java //域服务接口实现
│ │ │ └── aggregate02 //聚合2
│ │ │ └── test.java
│ │ └── infrastructure
│ │ ├── adapters
│ │ │ └── UserAdapter.java //基础设施层-适配层
│ │ └── tunnel //数据通道
│ │ └── db
│ │ ├── dao
│ │ │ └── UserMapper.java //MyBatis对应的Mapper
│ │ └── dataobject
│ │ └── UserDO.java //数据对象
│ └── resources
│ ├── META-INF
│ │ └── app.properties
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html
├── ddd-demo-start //应用启动入口,只允许放Controller和自己开发的Spring Boot Starter
│ ├── pom.xml
│ └── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── ddd
│ │ └── demo
│ │ ├── Application.java //主入口程序启动类
│ │ └── start
│ │ └── controller // controller所在包
│ │ └── UserController.java
│ └── resources
│ ├── META-INF
│ │ └── app.properties
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html
├── ddd-demo.iml
├── pom.xml67.1.2. Halo传统三层分层
Halo的传统三层是结合Service,Dao,Controller,和命令的编程模式。
tradition-demo
├── README.md
├── pom.xml
├── src
│ └── main
│ ├── java
│ │ └── org
│ │ └── xujin
│ │ └── tradition
│ │ └── demo
│ │ ├── Application.java //Spring Boot主入口程序类
│ │ ├── command //命令包
│ │ │ ├── AddUserCmdExe.java //写命令
│ │ │ ├── cmo
│ │ │ │ └── AddUserCmd.java //命令对象
│ │ │ ├── co
│ │ │ │ └── UserCO.java //客户端对象
│ │ │ └── query
│ │ │ └── QueryUserCmdExe.java //查询命令
│ │ ├── config
│ │ │ └── AutoConfig.java //自己定制的Spring Boot的AutoConfig
│ │ ├── controller
│ │ │ └── UserController.java //Controller
│ │ ├── converter
│ │ │ └── UserConverter.java //整个应用的转换防腐层,比如命令对象转为数据对象,数据对象转为客户端对象
│ │ ├── dao
│ │ │ └── UserMapper.java //MyBatis的Mapper
│ │ ├── dataobject
│ │ │ └── UserDO.java //数据对象
│ │ ├── service
│ │ │ ├── UserService.java //Service层的接口定义
│ │ │ └── impl
│ │ │ └── UserServiceImpl.java //Service层的接口实现,里面注入Mapper
│ │ └── utils
│ │ └── Iputil.java //自己写的工具类
│ └── resources
│ ├── META-INF
│ │ └── app.properties //Apollo的配置文件
│ ├── application.yml
│ ├── bootstrap.yml
│ ├── logback-spring.xml
│ └── static
│ └── index.html67.1.3. 统一的Java类命令规范
-
Controller-必须以Controller结尾,例如UserController.java
-
命令对象,必须放在cmo包下面,命令对象创建必须以cmd结尾,例如:AddUserCmd.java
-
命令执行器,必须以exe结尾,例如:AddUserCmdExe.java
-
Mapper,必须以Mapper结尾,例如:UserMapper.java
-
数据对象,必须以DO结尾,例如:UserDO.java
-
实体,必须以E结尾,例如:UserE.java
-
工厂,必须以Factory结尾, 例如:UserFactory.java
-
转换层,必须以Converter结尾,例如:UserConverter.java
-
资源库,必须以Repository结尾,例如:UserRepository.java
-
值对象,必须以VO结尾,例如:AppCallRelationVO.java
| 命令执行器中的代码,逻辑只做命令内容的check(即入参的check)和Service层的编排 |
67.2. 数据库访问层规范
Halo框架数据库访问层,目前通过封装Mybatis Plus作为统一的数据库访问层。
67.2.1. Halo Mybatis标准
-
新应用只允许使用Halo Mybatis作为数据库访问层,不允许使用其它Dao层,例如:JPA,原生Mybatis(非Mybatis Plus),Nutz等。
67.2.2. Mapper层规范
Mapper需继承BaseMapper,如下代码所示:
@Mapper
public interface UserMapper extends BaseMapper<UserDO> {
@Select("SELECT * FROM t_user u where u.is_deleted=0 and u.username=#{userName}")
UserDO findUserByUserName(@Param("userName") String userName);
}| @Select注解不允许写复杂的sql语句,复杂的sql语句,通过xml的方式处理。 |
67.3. 日志规范
系统上线之后,一旦发生异常或生产事故,首当其冲的是快速止损(最大降低损失),同时要弄清楚当时发生了什么, 用户当时做了什么操作,环境有无影响,数据有什么变化,是不是反复发生等,然后再进一步的确定大致出现的是什么问题。 此时,关键日志信息起到至关重要的作用。因此对日志的使用进行规范。
67.3.1. 日志使用原则
-
不能影响系统正常运行;
-
不允许产生数据安全问题,重要数据脱敏。
-
不允许输出机密或敏感信息;
-
日志可供开发人员定位问题的真正原因;
-
日志可供监控系统自动监控与分析;
67.3.2. 日志打点
-
系统初始化:系统初始化时会依赖一些关键配置,根据参数不同会提供不一样的服务。将系统的启动参数记录INFO日志,打印出参数以及启动完成态服务表述。
-
业务流程与预期不符:项目代码中结果与期望不符时也是日志场景之一,简单来说所有流程分支都可以加入考虑。取决于开发人员判断能否容忍情形发生。常见的合适场景包括外部参数不正确,数据处理问题导致返回码不在合理范围内等等。
-
系统核心的关键动作:系统中核心角色触发的业务动作是需要多加关注的,是衡量系统正常运行的重要指标,建议记录INFO级别日志,比如电商系统用户从登录到下单的整个流程;微服务各服务节点交互;核心数据表增删改等等。
-
系统异常:这类捕获的异常是系统告知开发人员需要加以关注的,是质量非常高的报错。应当适当记录日志,根据实际结合业务的情况使用warn或者error级别。
67.3.3. 记日志场景
什么时候应该打日志
-
当你遇到问题的时候,只能通过debug功能来确定问题,你应该考虑打日志,良好的应用,是可以通过日志进行问题定位分析的。
-
当你碰到if…else 或者 switch这样的分支时,要在分支的入口打印日志,用来确定进入了哪个分支
-
经常以功能为核心进行开发,你应该在提交代码前,可以确定通过日志可以看到整个流程
67.3.4. 日志打印规范
1.使用slf4j
-
使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
-
实现方式统一使用: Logback框架
-
统一使用 slf4j,它本质是Facade, 便于我们后期随时切换日志实现。避免在代码中直接使用log4j或java logging 等实现类
2.对象声明
建议使用private static final。声明为private可防止logger对象被其他类非法使用。声明为static可防止重复new出logger对象,还可以防止 logger被序列化,造成安全风险。声明为final是因为在类的生命周期内无需变更logger。
private static final Logger logger = LoggerFactory.getLogger(Xxx.class);3.必须使用参数化信息的方式:
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);| 不推荐使用字符串拼接的方式打印日志,可读性和可维护性都比较差。建议使用占位符 |
4.对于debug日志,必须判断是否为debug级别后,才进行使用:
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " +id + " symbol: " + symbol);
}5.不要进行字符串拼接,那样会产生很多String对象,占用空间,影响性能。
logger.debug("Processing trade with id: " + id + " symbol: " + symbol);6.使用[]进行参数变量隔离
如有参数变量,应该写成如下写法:
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);| 这样的格式写法,可读性更好,对于排查问题更有帮助。 |
7.语言
最好在打印日志时输出英文,防止中文不支持,导致落盘出现日志乱码的情况。
8.禁用System输出
9.不打印无意义日志
10.打印日志的代码不能出现任何异常
11.catch中的异常记录必须打印堆栈信息,不要用e.printStackTrace()。
logger.error("xxx fail ",e);| 不要记录日志后又抛出异常。抛出去的异常,一般外层会处理。 如果不处理,那为什么还要抛出去?另外一个原则是,无论是否发生异常,都不要在不同地方重复记录针对同一事件的日志信息 |
67.3.5. 不同日志级别的使用
1.ERROR日志:影响到程序正常运行需要记录error日志,系统需要将错误或异常细节记录ERROR日志中,方便后续人工回溯解决。
当前请求正常运行的异常情况,例如:
-
打开配置文件失败
-
所有第三方对接的异常(包括第三方返回错误码)
-
所有影响功能使用的异常,包括:SQLException和除了业务异常之外的所有异常(RuntimeException和Exception)
比如往ES,MongoDB等写数据失败,如果有Throwable信息,需要记录完成的堆栈信息:
try{
....
}catch(Exception ex){
String errorMessage=String.format("Error while reading information of user [%s]",userName);
logger.error(errorMessage,ex); (1)
throw new BusinessException(errorMessage,ex);
}| 1 | 如果进行了异常抛出操作,如果没有全局异常解析器统一记录日志或者相应代码捕获处理,需要记录error日志,否则不需要。 |
2.WARN:不应该出现但是不影响程序时,需要记录warn日志。
-
当前请求正常运行的异常情况:
-
有容错机制的时候出现的错误情况
-
找不到配置文件,但是系统能自动创建配置文件
-
程序调用了一个旧版本的接口,可选参数不合法,非业务预期的状态但仍可继续处理等
-
-
即将接近临界值的时候:
-
缓存池占用达到警告线
-
-
业务异常的记录:
-
当接口抛出业务异常时,应该记录此异常
-
3.INFO:记录系统关键信息,旨在保留系统正常工作期间关键运行指标, 开发人员可以将初始化系统配置、业务状态变化信息,或者用户业务流程中的核心处理记录到INFO日志中, 方便日常运维工作以及错误回溯时上下文场景复现
-
Service方法中对于系统/业务状态的变更 -主要逻辑中的分步骤
-
外部接口部分
-
客户端请求参数(REST/WS)
-
调用第三方时的调用参数和调用结果
| 1.并不是所有的service都进行出入口打点记录,单一、简单service是没有意义的(job除外,job需要记录开始和结束,)。 2.对于复杂的业务逻辑,需要进行日志打点,以及埋点记录,比如电商系统中的下订单逻辑,以及OrderAction操作(业务状态变更)。 3.对于整个系统的提供出去的接口(REST/RPC),使用info记录入参 4.服务外部接口提供方,需要记录入参。 5.调用其他第三方服务时,所有的出参和入参是必须要记录的(否则出现问题很难追溯) |
4.DEBUG:可以填写所有的想知道的相关信息(但不代表可以随便写,debug信息要有意义,最好有相关参数)用于Debug调试
生产环境需要关闭Debug日志,如果在生产环境下需要开启DEBUG,需要使用开关进行管理,不能一直开启。
logger.debug("开始获取员工[{}] [{}]年[{}]月休假情况",employee,year,month);
logger.debug("员工[{}][{}]年[{}]月年假/病假/事假为[{}]/[{}]/[{}]",employee,year,month,annualLeaveDays,sickLeaveDays,noPayLeaveDays);5.TRACE:特别详细的系统运行完整信息,业务代码中,不要使用.(除非有特殊用意,否则请使用DEBUG级别替代)
规范示例说明
@Override
@Transactional
public void createUserAndBindMobile(@NotBlank String mobile, @NotNull User user) throws CreateConflictException{
boolean debug = log.isDebugEnabled();
if(debug){
log.debug("开始创建用户并绑定手机号. args[mobile=[{}],user=[{}]]", mobile, LogObjects.toString(user));
}
try {
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
userRepository.insertSelective(user);
if(debug){
log.debug("创建用户信息成功. insertedUser=[{}]",LogObjects.toString(user));
}
UserMobileRelationship relationship = new UserMobileRelationship();
relationship.setMobile(mobile);
relationship.setOpenId(user.getOpenId());
relationship.setCreateTime(new Date());
relationship.setUpdateTime(new Date());
userMobileRelationshipRepository.insertOnDuplicateKey(relationship);
if(debug){
log.debug("绑定手机成功. relationship=[{}]",LogObjects.toString(relationship));
}
log.info("创建用户并绑定手机号. userId=[{}],openId=[{}],mobile=[{}]",user.getId(),user.getOpenId(),mobile);
}catch(DuplicateKeyException e){
log.info("创建用户并绑定手机号失败,已存在相同的用户. openId=[{}],mobile=[{}]",user.getOpenId(),mobile);
throw new CreateConflictException("创建用户发生冲突, openid=[%s]",user.getOpenId());
}
}| 上述日志级别从高到低排列,是开发中最常用的五种。生产系统一般只打印INFO 级别以上的日志,对于 DEBUG 级别的日志,只在测试环境中打印。 打印错误日志时,需要区分是业务异常(如:用户名不能为空)还是系统异常(如:调用 会员核心异常),业务异常使用 warn 级别记录, 系统异常使用 error 记录。 |
67.4. 二方包规范
67.4.1. 二方包原则
1.提供方原则:谁提供的二方包,需要对其负责,由快照版本变为正式版本,有通知修改的义务和责任
2.使用方原则:不管是谁提供的二方包,如果是快照版,要么不要用,要么对方给出发布正式版本的时间, 上线前必须修改为正式版本
3.二方包中只允许存在接口定义,入参,出参,枚举等不含有影响其它应用启动,正常运行的功能存在
67.4.2. Feign接口定义规范
Feign接口开发目前出现五花八门的开发方式,特做此约定。
1.@FeignClient中使用name=Spring Application Name明确服务提供者,不允许使用value,示例代码如下
@FeignClient(name = "defensor-openfeign-provider")
public interface UserService {
@RequestMapping(value = "/user/add", method = RequestMethod.GET)
public String addUser(User user);
@RequestMapping(value = "/user/update", method = RequestMethod.POST)
public String updateUser(@RequestBody User user);
}| 不允许使用@FeignClient(value="ZM-ECONTRACT-SERVICE")方式,代码review关注点。 |
2.只能使用@RequestMapping或 @PostMapping, @GetMapping定义接口中的方法。
-
使用@RequestMapping
@FeignClient(name = "defensor-openfeign-provider")
public interface UserService {
@RequestMapping(value = "/user/add", method = RequestMethod.GET)
public String addUser(User user);
@RequestMapping(value = "/user/update", method = RequestMethod.POST)
public String updateUser(@RequestBody User user);
}-
使用@PostMapping和 @GetMapping
@FeignClient(name = "defensor-openfeign-provider")
public interface UserService {
@GetMapping(value = "/user/add")
public String addUser(User user);
@PostMapping(value = "/user/update")
public String updateUser(@RequestBody User user);
}3.不允许使用Netflix底层的@RequestLine去定义接口中的方法,如下所示。
@FeignClient(name = "ZM-CRM-SERVICE", configuration = FeignConfiguration.class, fallbackFactory = CrmFeignClientFallbackFactory.class)
public interface CrmFeignClient {
@RequestLine("POST /giveUpReason/saveGiveUpReason")
Result saveGiveUpReason(@RequestBody GiveUpReason GiveUpReason);
@RequestLine("GET /giveUpReason/queryGiveUpReasonIdByStuId?studentId={studentId}")
Result<List<Integer>> queryGiveUpReasonIdByStuId(@Param("studentId") Integer studentId);
}| @RequestLine("POST /giveUpReason/saveGiveUpReason")其中POST /giveUpReason中的空格,多一个或少一个会报错,可编码差。 |
4.不允许使用@PathVariable("xxx") 绑定到操作方法的入参中定义方法,列如:
@RequestMapping(value = "/getUser/{id}", method = RequestMethod.GET)
public String getUser( @PathVariable Long id);| 主要是Cat进行调用链分析时,/getUser/{id}URL参数丢失。 |
67.5. IDEA常用设置
67.5.1. Eclipse Code Formatter Plugin安装
在eclipse中有自动配置code style的功能 ,但是idea上却没有,这个时候需要自己手工配置
-
在idea中找到Preference→Plugins→Browse repositories→搜索Eclipse Code Formatter,安装插件,
-
统一格式化模板,格式化应用代码。 搜索安装Eclipse Code Formatter插件,如下图所示:
-
-
导入Spring官方定制的Formatter文件.
安装完成之后,按快捷键Alt + Ctrl + L就可以格式化代码了
67.5.2. Save Actions插件安装
每次手动格式化代码是不是很不爽,可以安装Save Actions插件,安装完成之后, 每次保存(Window:Ctrl+S Mac:command+s,Mac版Idea自动保存文件不会触发)代码的时候插件会自动帮你格式化代码,不需要手工格式化了
67.5.3. 无效导入包自动整理设置
Add unambiguous imports on the fly:快速添加明确的导入。
Optimize imports on the fly:快速优化导入,优化的意思即自动帮助删除无用的导入。
67.5.6. 设置统一Header
可以通过下面的方式,统一设置如下图所示:
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")
package ${PACKAGE_NAME};
#end
/**
*
* 〈${DESCRIPTION}〉
*
* @author xujin
* @date ${DATE} ${TIME}
* @since ${version}
*/
public class ${NAME} {
}67.6. 返回值规范
67.6.1. 常规返回约定
Halo框架提供统一的返回值约定,可以直接使用org.xujin.halo.dto.ResultData.java
| 字段 | 描述 | 备注 |
|---|---|---|
code |
表示http请求成功,当code为200的时候代表收到了后端的返回,客户端去按照ResultData以Json格式反序列化Http Body的报文 |
值为200 |
msgCode |
表示业务处理返回的状态码 |
|
msgContent |
表示业务处理返回的内容提示信息 |
|
data |
表示业务处理返回的任意结构的泛型数据 |
{
"code": 200,
"msgCode": "200",
"msgContent": "success",
"data": {
"username": "zhangsan",
"idCard": "19921137705",
"password": "123456",
"email": "12345@qq.com",
"phone": "18888888888"
}
}|
msgCode只所以设计为String而不是int类型,是因为考虑到状态码分组扩展,比如msgCode="U201"等,可以设置模块前缀或其它分组前缀 |
67.6.2. 分页返回约定
在Halo框架中内置了分页的返回值,详细查看org.xujin.halo.dto.PageResult.java,代码如下所示:
package org.xujin.halo.dto;
import lombok.Builder;
import lombok.Getter;
import lombok.Setter;
import java.util.List;
/**
* 统一的分页返回数据
* @author xujin
* @param <T>
*/
@Getter
@Setter
@Builder
public class PageResult<T> {
/**
* 分页的数据
*/
private List<T> list;
/**
* 总的记录数
*/
private long totalCount;
/**
* 总页数
*/
private long totalPage;
/**
* 当前页数
*/
private long currentPage;
public PageResult() {
}
public static <T> PageResultBuilder builder(List<T> list){
return new PageResultBuilder().list(list);
}
public PageResult(List<T> list, long totalCount, long totalPage, long currentPage) {
this.list = list;
this.totalCount = totalCount;
this.totalPage = totalPage;
this.currentPage = currentPage;
}
}{
"code": 200,
"msgCode": "200",
"msgContent": "success",
"data": {
"list": [
{
"id": 2,
"appId": "biz-order",
"domainID": "4",
"domainName": "订单域",
"name": "biz-order",
"description": "订单应用",
"springApplicationName": "biz-order",
"haloStatus": 1,
"isDeleted": 0,
"gmtCreate": "2019-08-02 14:01:14",
"gmtModified": "2019-08-02 14:01:14"
},
{
"id": 16,
"appId": "biz-goods",
"domainID": "6",
"domainName": "商品域",
"name": "biz-goods",
"description": "商品",
"springApplicationName": "biz-goods",
"haloStatus": 1,
"isDeleted": 0,
"gmtCreate": "2019-08-05 10:54:43",
"gmtModified": "2019-08-05 10:54:43"
}
],
"totalCount": 17,
"totalPage": 2,
"currentPage": 1
}
}67.7. Git Flow规范
Git流程借鉴AoneFlow模式。主要思想就是如下所示:
1.从maser拉出Feature分支进行功能开发,可以多个Feature分支并行存在。
2.当需要发布时,由测试负责人或发布负责人,从maser拉出最新的发布分支,需要发布的功能合并到发布分支进行测试(如果突然有功能需要搭车进行一起发布,需要严格把握,因为合并的Feature分支越多,需要回归测试的功能点就越多,不控制很容易翻车)
3.测试完毕之后进行发布,发布完毕之后,把发布分支合并到master分支(原有发布分支可以删除也可以保留)
4.紧急Hotfix原则从Master分支拉出hotfix分支,例如:/hotfix/20190728_fix某某某,HotFix之后合并到Master分支。
67.7.1. 分支说明
| 分支 | 说明 | 备注 |
|---|---|---|
特性分支 |
特定功能版本分支 |
个人或者开发小组,开发团队从master拉出feature分支,最终开发完毕合并到发布分支 |
主干分支 |
主干分支即Master分支 |
生产最新最稳定的分支,必要时对master分支打Tag |
开发分支 |
开发分支即develop分支 |
开发主线分支 |
发布分支 |
发布分支,主要用于发布,也可以称之为realese分支,也可以叫publish分支。 |
发布分支一般由测试,或者发布负责人,从Master拉出,比如周三要上线,测试或者发布负责人拉出发布分支为/publish_20190724_xxx |
67.7.2. 从Master拉出Feature分支
每当开始一件新的工作项(比如新的功能或是待解决的问题)的时候,从代表最新已发布版本的主干上创建一个通常以feature/前缀命名的特性分支,然后在这个分支上提交代码修改。也就是说,每个工作项(可以是一个人完成,或是多个人协作完成)对应一个特性分支,所有的修改都不允许直接提交到主干。如下图所示:
67.7.3. 通过合并特性分支,形成发布分支
AoneFlow的思路是,从主干上拉出一条新分支,将所有本次要集成或发布的特性分支依次合并过去,从而得到发布分支。发布分支通常以release/前缀命名或者/publish为前缀。
67.7.4. 发布分支发布完毕之后,合并到主干
发布到线上正式环境后,合并相应的发布分支到主干,在主干添加标签,同时删除该发布分支关联的特性分支。 当一条发布分支上的流水线完成了一次线上正式环境的部署,就意味着相应的功能真正地发布了,此时应该将这条发布分支合并到主干。为了避免在代码仓库里堆积大量历史上的特性分支,还应该清理掉已经上线部分特性分支。与 GitFlow 相似,主干分支上的最新版本始终与线上版本一致,如果要回溯历史版本,只需在主干分支上找到相应的版本标签即可。
67.7.5. Hotfix原则
如果出现bug,需要紧急HotFix,原则也是从Master分支,拉出分支,修改发布,然后合并到Maser。
67.8. 错误码设计
67.8.1. 为什么需要错误码
-
输出到日志的错误码: 用来快速溯源找到问题和形成监控大盘。
-
错误码是用来做沟通的:系统与系统间的沟通,人与人间的沟通,人与系统间的沟通。
67.8.2. 什么是错误码
错误码的出现就是为了快速定位系统的问题从而快速解决问题和故障,止损。比如系统整个链路,应用内部错在哪,谁的错,如何快速应对。
-
好的错误码必须能够快速知晓错误来源。
-
好的错误码必须易于记忆和对比。
-
好的错误码必须能够脱离文档和系统平台达到线下轻量沟通的目的(这个要求比较高)。
67.8.3. 错误码规范
按照《阿里Java开发手册》的建议设计出的面向日志的错误码定义共十三位(十位有意义,三位连接符),并且应该具有如下分类:
-
应用标识,表示错误属于哪个应用,三位数字。
-
功能域标识,表示错误属于应用中的哪个功能模块,三位数字。
-
错误类型,表示错误属于那种类型,一位字母。
-
错误编码,错误类型下的具体错误,三位数字。
-
不用枚举定义错误码
国际化支持是一个不使用枚举定义错误码很重要的理由。 我们通过 i18n 的支持可以做到错误码、错误状态、错误描述的管理。
-
错误码定义要有字母也要有数字.
-
快速溯源|简单易记 | 沟通标准化
怎么能达到这个效果呢? 首先要有一套标准并且在域内各个业务都在用同样的标准。 其次要求错误码有自我解释的能力是有信息含量的有意义。 最后在域内要传递错误码。
67.8.4. 异常码使用建议
异常码使用参考建议,如下:
成功
- 200: 完全成功
- 201-209: HTTP 规范值
---------------------
业务异常
非监控中心必须立刻告警解决的异常
- 220-249: 应用自定义业务异常分组。可用于调用成功但发生业务异常的情况,如购物车超限购。
- 250-259: 自定义,如降级,熔断,限流等主动行为,通过埋点事件告警。
- 260-299: 保留分组,可用于Halo Framework。
---------------------
客户端系统异常
- 400: 通用的客户端异常
- 401-419: HTTP 规范值,如401,403代表认证、授权的失效。
- 420-449: 应用自定义分组
- 450-469: 客户端抛出异常
- 470-499: 保留分组,可用于Halo Framework
---------------------
服务端系统异常
- 500: 通用的服务端异常,应用抛出的,未设置分组时的默认异常
- 501-509: HTTP 规范值,如503代表服务忙
- 520-559: 应用自定义分组
- 560-599: 保留分组,可用于Halo Framework
---------------------
使用建议
应用可使用通用的400,500状态码,也可以根据Http规范含义,使用类似401,403,503这样的有意义状态码,也可以使用规范中留给应用自定义的分组。
Halo框架固定使用规范中定义的分组。